 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALIGN: Advanced Query Initialization with LiDAR-Image Guidance for Occlusion-Robust 3D Object Detection
Dec 20, 2025

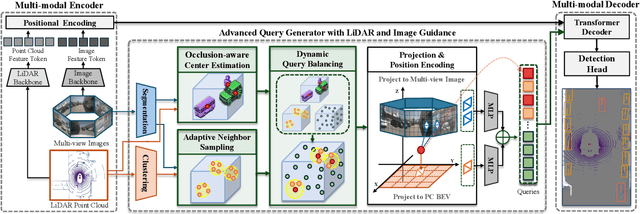

Recent query-based 3D object detection methods using camera and LiDAR inputs have shown strong performance, but existing query initialization strategies,such as random sampling or BEV heatmap-based sampling, often result in inefficient query usage and reduced accuracy, particularly for occluded or crowded objects. To address this limitation, we propose ALIGN (Advanced query initialization with LiDAR and Image GuidaNce), a novel approach for occlusion-robust, object-aware query initialization. Our model consists of three key components: (i) Occlusion-aware Center Estimation (OCE), which integrates LiDAR geometry and image semantics to estimate object centers accurately (ii) Adaptive Neighbor Sampling (ANS), which generates object candidates from LiDAR clustering and supplements each object by sampling spatially and semantically aligned points around it and (iii) Dynamic Query Balancing (DQB), which adaptively balances queries between foreground and background regions. Our extensive experiments on the nuScenes benchmark demonstrate that ALIGN consistently improves performance across multiple state-of-the-art detectors, achieving gains of up to +0.9 mAP and +1.2 NDS, particularly in challenging scenes with occlusions or dense crowds. Our code will be publicly available upon publication.
Finetuning Pre-trained Model with Limited Data for LiDAR-based 3D Object Detection by Bridging Domain Gaps
Oct 02, 2024LiDAR-based 3D object detectors have been largely utilized in various applications, including autonomous vehicles or mobile robots. However, LiDAR-based detectors often fail to adapt well to target domains with different sensor configurations (e.g., types of sensors, spatial resolution, or FOVs) and location shifts. Collecting and annotating datasets in a new setup is commonly required to reduce such gaps, but it is often expensive and time-consuming. Recent studies suggest that pre-trained backbones can be learned in a self-supervised manner with large-scale unlabeled LiDAR frames. However, despite their expressive representations, they remain challenging to generalize well without substantial amounts of data from the target domain. Thus, we propose a novel method, called Domain Adaptive Distill-Tuning (DADT), to adapt a pre-trained model with limited target data (approximately 100 LiDAR frames), retaining its representation power and preventing it from overfitting. Specifically, we use regularizers to align object-level and context-level representations between the pre-trained and finetuned models in a teacher-student architecture. Our experiments with driving benchmarks, i.e., Waymo Open dataset and KITTI, confirm that our method effectively finetunes a pre-trained model, achieving significant gains in accuracy.
Just Add $100 More: Augmenting NeRF-based Pseudo-LiDAR Point Cloud for Resolving Class-imbalance Problem
Mar 20, 2024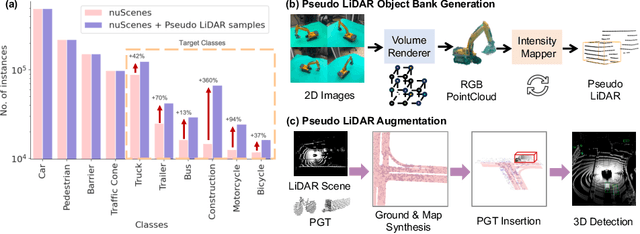
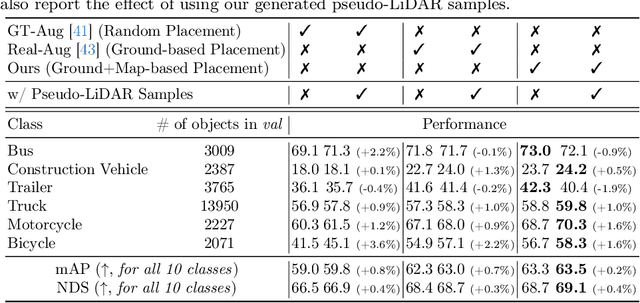
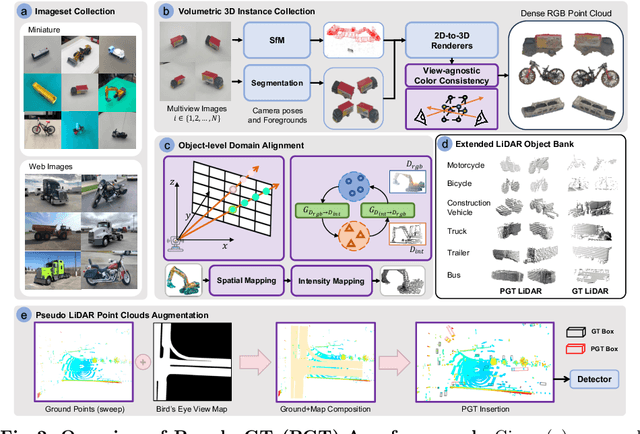
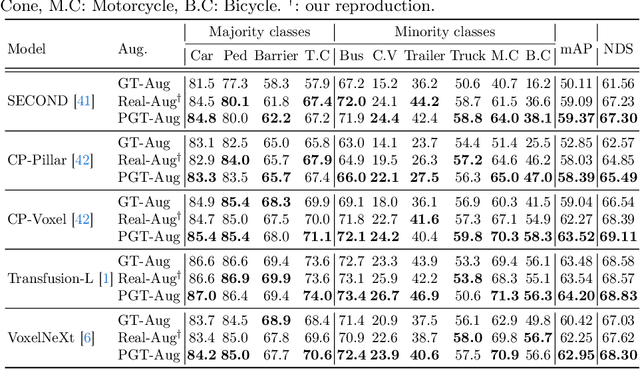
Typical LiDAR-based 3D object detection models are trained in a supervised manner with real-world data collection, which is often imbalanced over classes (or long-tailed). To deal with it, augmenting minority-class examples by sampling ground truth (GT) LiDAR points from a database and pasting them into a scene of interest is often used, but challenges still remain: inflexibility in locating GT samples and limited sample diversity. In this work, we propose to leverage pseudo-LiDAR point clouds generated (at a low cost) from videos capturing a surround view of miniatures or real-world objects of minor classes. Our method, called Pseudo Ground Truth Augmentation (PGT-Aug), consists of three main steps: (i) volumetric 3D instance reconstruction using a 2D-to-3D view synthesis model, (ii) object-level domain alignment with LiDAR intensity estimation and (iii) a hybrid context-aware placement method from ground and map information. We demonstrate the superiority and generality of our method through performance improvements in extensive experiments conducted on three popular benchmarks, i.e., nuScenes, KITTI, and Lyft, especially for the datasets with large domain gaps captured by different LiDAR configurations. Our code and data will be publicly available upon publication.