 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Guided Multi-Source Domain Adaptation for Object Detection
May 13, 2026General object detection (OD) struggles to detect objects in the target domain that differ from the training distribution. To address this, recent studies demonstrate that training from multiple source domains and explicitly processing them separately for multi-source domain adaptation (MSDA) outperforms blending them for unsupervised domain adaptation (UDA). However, existing MSDA methods learn domain-agnostic features from domain-specific RGB images while preserving domain-specific information from the domain-agnostic feature map. To address this, we propose MS-DePro: Multi-Source Detector with Depth and Prompt, composed of (1) depth-guided localization and (2) multi-modal guided prompt learning. We leverage domain-agnostic input modalities, namely depth maps and text, to encode domain-agnostic characteristics. Specifically, we utilize depth maps to generate domain-agnostic region proposals for localization and integrate multi-modal features to align learnable text embeddings for classification. MS-DePro achieves state-of-the-art performance on MSDA benchmarks, and comprehensive ablations demonstrate the effectiveness of our contributions. Our code is available on https://github.com/sejong-rcv/Multi-Modal-Guided-Multi-Source-Domain-Adaptation-for-Object-Detection.
VERIA: Verification-Centric Multimodal Instance Augmentation for Long-Tailed 3D Object Detection
Mar 25, 2026Long-tail distributions in driving datasets pose a fundamental challenge for 3D perception, as rare classes exhibit substantial intra-class diversity yet available samples cover this variation space only sparsely. Existing instance augmentation methods based on copy-paste or asset libraries improve rare-class exposure but are often limited in fine-grained diversity and scene-context placement. We propose VERIA, an image-first multimodal augmentation framework that synthesizes synchronized RGB--LiDAR instances using off-the-shelf foundation models and curates them with sequential semantic and geometric verification. This verification-centric design tends to select instances that better match real LiDAR statistics while spanning a wider range of intra-class variation. Stage-wise yield decomposition provides a log-based diagnostic of pipeline reliability. On nuScenes and Lyft, VERIA improves rare-class 3D object detection in both LiDAR-only and multimodal settings. Our code is available at https://sgvr.kaist.ac.kr/VERIA/.
Boosting Cross-spectral Unsupervised Domain Adaptation for Thermal Semantic Segmentation
May 11, 2025In autonomous driving, thermal image semantic segmentation has emerged as a critical research area, owing to its ability to provide robust scene understanding under adverse visual conditions. In particular, unsupervised domain adaptation (UDA) for thermal image segmentation can be an efficient solution to address the lack of labeled thermal datasets. Nevertheless, since these methods do not effectively utilize the complementary information between RGB and thermal images, they significantly decrease performance during domain adaptation. In this paper, we present a comprehensive study on cross-spectral UDA for thermal image semantic segmentation. We first propose a novel masked mutual learning strategy that promotes complementary information exchange by selectively transferring results between each spectral model while masking out uncertain regions. Additionally, we introduce a novel prototypical self-supervised loss designed to enhance the performance of the thermal segmentation model in nighttime scenarios. This approach addresses the limitations of RGB pre-trained networks, which cannot effectively transfer knowledge under low illumination due to the inherent constraints of RGB sensors. In experiments, our method achieves higher performance over previous UDA methods and comparable performance to state-of-the-art supervised methods.
Just Add $100 More: Augmenting NeRF-based Pseudo-LiDAR Point Cloud for Resolving Class-imbalance Problem
Mar 20, 2024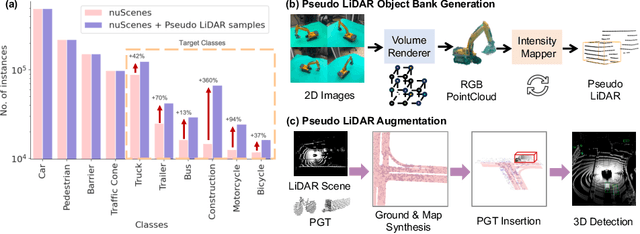
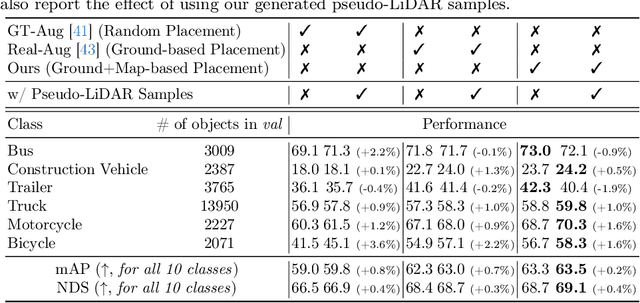
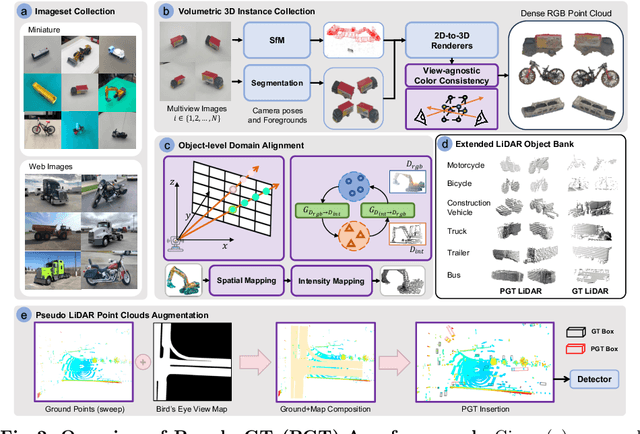
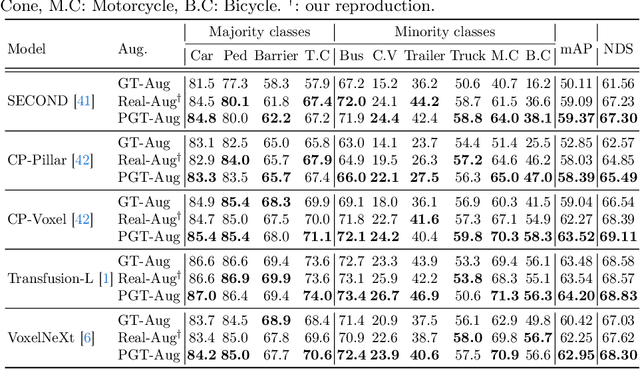
Typical LiDAR-based 3D object detection models are trained in a supervised manner with real-world data collection, which is often imbalanced over classes (or long-tailed). To deal with it, augmenting minority-class examples by sampling ground truth (GT) LiDAR points from a database and pasting them into a scene of interest is often used, but challenges still remain: inflexibility in locating GT samples and limited sample diversity. In this work, we propose to leverage pseudo-LiDAR point clouds generated (at a low cost) from videos capturing a surround view of miniatures or real-world objects of minor classes. Our method, called Pseudo Ground Truth Augmentation (PGT-Aug), consists of three main steps: (i) volumetric 3D instance reconstruction using a 2D-to-3D view synthesis model, (ii) object-level domain alignment with LiDAR intensity estimation and (iii) a hybrid context-aware placement method from ground and map information. We demonstrate the superiority and generality of our method through performance improvements in extensive experiments conducted on three popular benchmarks, i.e., nuScenes, KITTI, and Lyft, especially for the datasets with large domain gaps captured by different LiDAR configurations. Our code and data will be publicly available upon publication.
PANDAS: Prototype-based Novel Class Discovery and Detection
Feb 27, 2024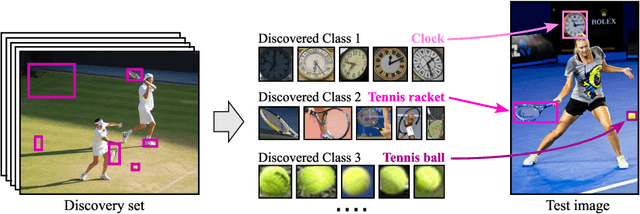
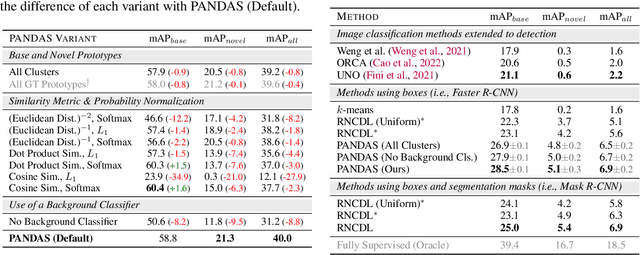
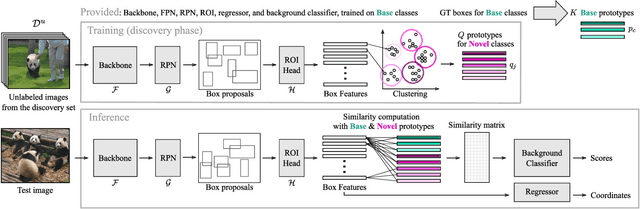

Object detectors are typically trained once and for all on a fixed set of classes. However, this closed-world assumption is unrealistic in practice, as new classes will inevitably emerge after the detector is deployed in the wild. In this work, we look at ways to extend a detector trained for a set of base classes so it can i) spot the presence of novel classes, and ii) automatically enrich its repertoire to be able to detect those newly discovered classes together with the base ones. We propose PANDAS, a method for novel class discovery and detection. It discovers clusters representing novel classes from unlabeled data, and represents old and new classes with prototypes. During inference, a distance-based classifier uses these prototypes to assign a label to each detected object instance. The simplicity of our method makes it widely applicable. We experimentally demonstrate the effectiveness of PANDAS on the VOC 2012 and COCO-to-LVIS benchmarks. It performs favorably against the state of the art for this task while being computationally more affordable.
Drop to Adapt: Learning Discriminative Features for Unsupervised Domain Adaptation
Oct 12, 2019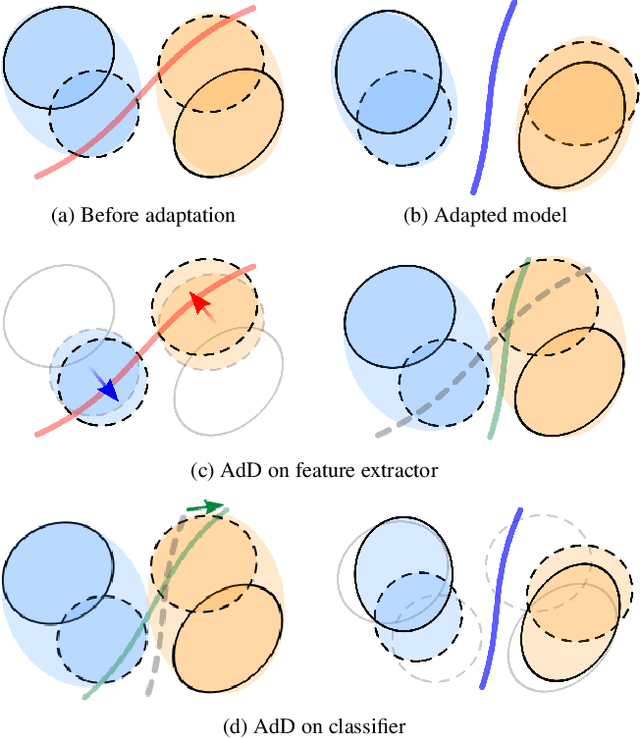
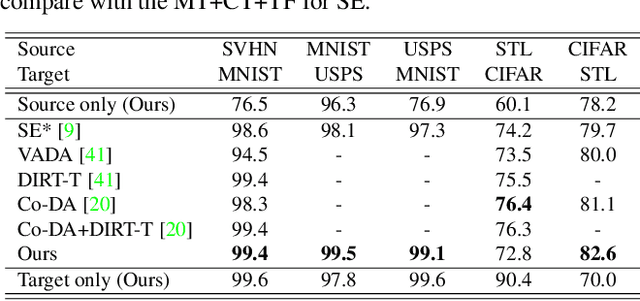
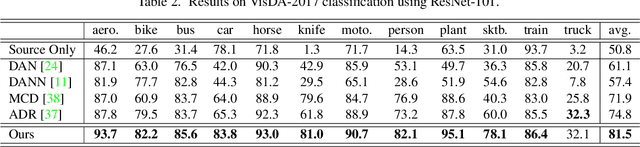
Recent works on domain adaptation exploit adversarial training to obtain domain-invariant feature representations from the joint learning of feature extractor and domain discriminator networks. However, domain adversarial methods render suboptimal performances since they attempt to match the distributions among the domains without considering the task at hand. We propose Drop to Adapt (DTA), which leverages adversarial dropout to learn strongly discriminative features by enforcing the cluster assumption. Accordingly, we design objective functions to support robust domain adaptation. We demonstrate efficacy of the proposed method on various experiments and achieve consistent improvements in both image classification and semantic segmentation tasks. Our source code is available at https://github.com/postBG/DTA.pytorch.
VPGNet: Vanishing Point Guided Network for Lane and Road Marking Detection and Recognition
Oct 17, 2017
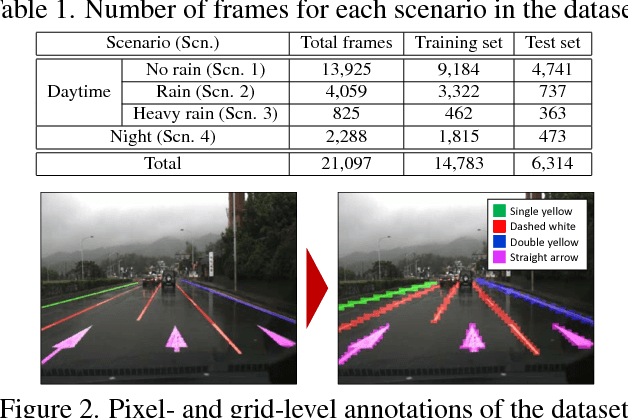
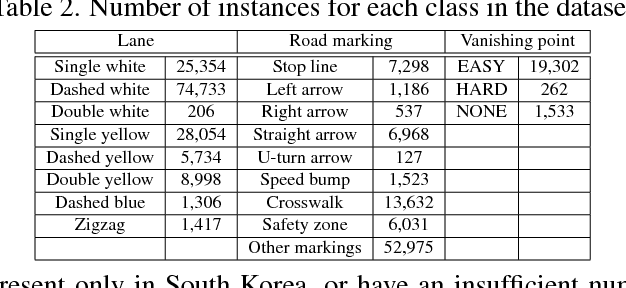
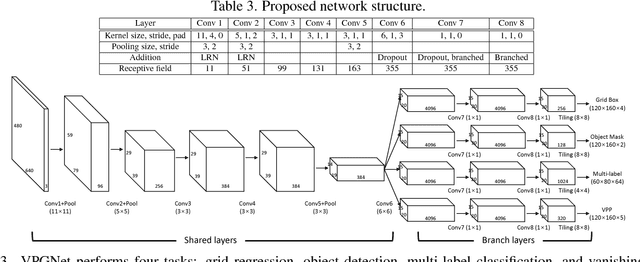
In this paper, we propose a unified end-to-end trainable multi-task network that jointly handles lane and road marking detection and recognition that is guided by a vanishing point under adverse weather conditions. We tackle rainy and low illumination conditions, which have not been extensively studied until now due to clear challenges. For example, images taken under rainy days are subject to low illumination, while wet roads cause light reflection and distort the appearance of lane and road markings. At night, color distortion occurs under limited illumination. As a result, no benchmark dataset exists and only a few developed algorithms work under poor weather conditions. To address this shortcoming, we build up a lane and road marking benchmark which consists of about 20,000 images with 17 lane and road marking classes under four different scenarios: no rain, rain, heavy rain, and night. We train and evaluate several versions of the proposed multi-task network and validate the importance of each task. The resulting approach, VPGNet, can detect and classify lanes and road markings, and predict a vanishing point with a single forward pass. Experimental results show that our approach achieves high accuracy and robustness under various conditions in real-time (20 fps). The benchmark and the VPGNet model will be publicly available.
Pixel-Level Domain Transfer
Nov 28, 2016
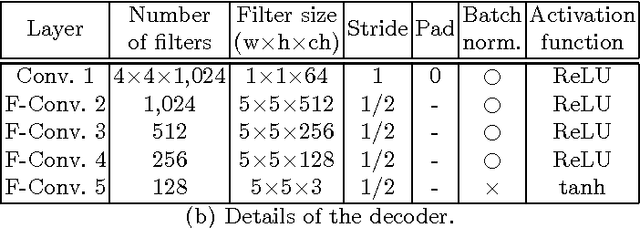
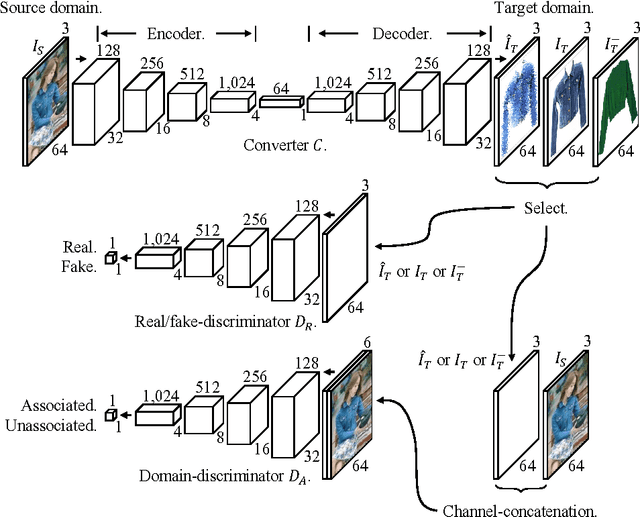

We present an image-conditional image generation model. The model transfers an input domain to a target domain in semantic level, and generates the target image in pixel level. To generate realistic target images, we employ the real/fake-discriminator as in Generative Adversarial Nets, but also introduce a novel domain-discriminator to make the generated image relevant to the input image. We verify our model through a challenging task of generating a piece of clothing from an input image of a dressed person. We present a high quality clothing dataset containing the two domains, and succeed in demonstrating decent results.
Fine-scale Surface Normal Estimation using a Single NIR Image
Mar 24, 2016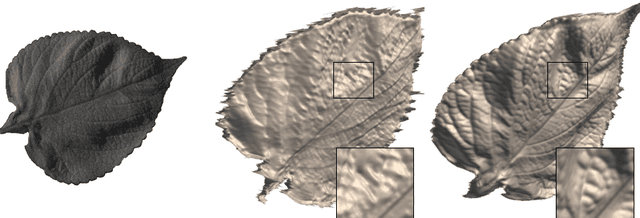
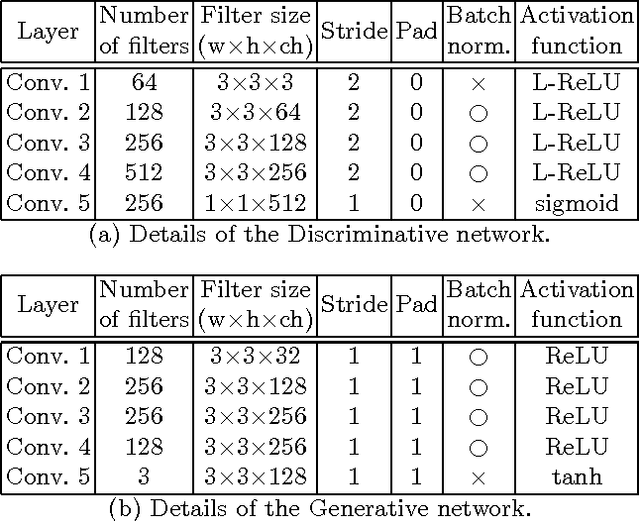
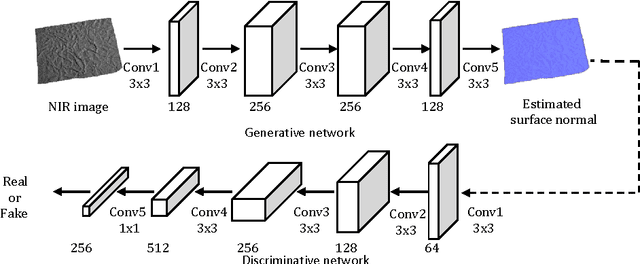
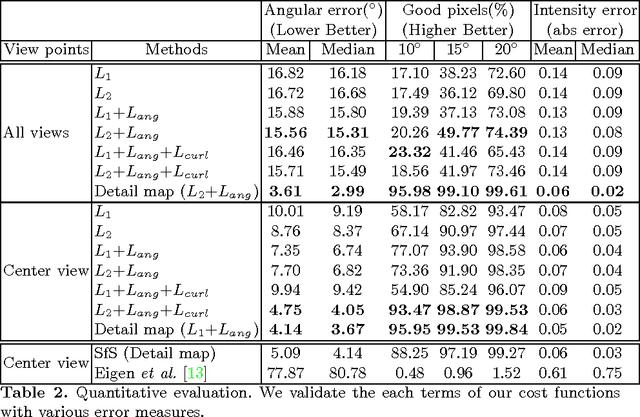
We present surface normal estimation using a single near infrared (NIR) image. We are focusing on fine-scale surface geometry captured with an uncalibrated light source. To tackle this ill-posed problem, we adopt a generative adversarial network which is effective in recovering a sharp output, which is also essential for fine-scale surface normal estimation. We incorporate angular error and integrability constraint into the objective function of the network to make estimated normals physically meaningful. We train and validate our network on a recent NIR dataset, and also evaluate the generality of our trained model by using new external datasets which are captured with a different camera under different environment.