 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVPGNet: Vanishing Point Guided Network for Lane and Road Marking Detection and Recognition
Oct 17, 2017
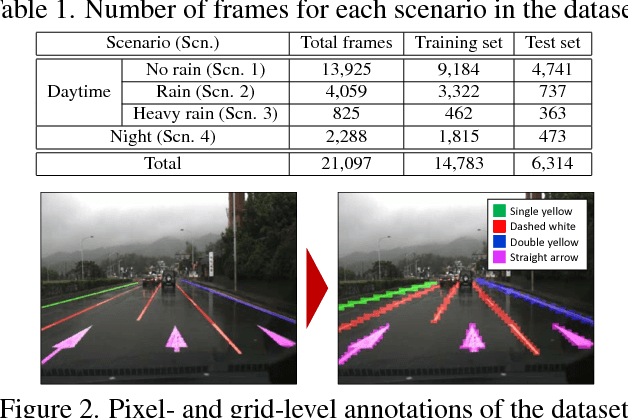
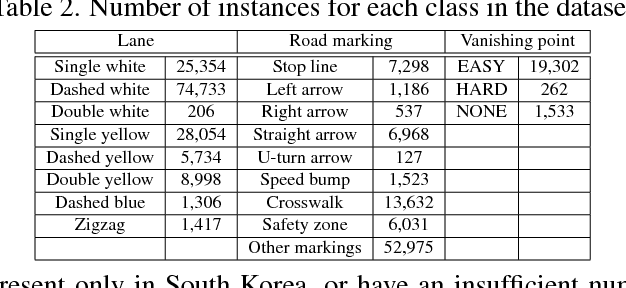
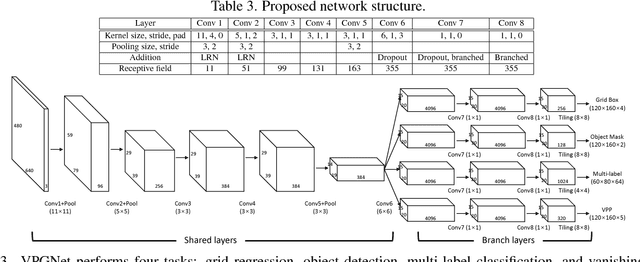
In this paper, we propose a unified end-to-end trainable multi-task network that jointly handles lane and road marking detection and recognition that is guided by a vanishing point under adverse weather conditions. We tackle rainy and low illumination conditions, which have not been extensively studied until now due to clear challenges. For example, images taken under rainy days are subject to low illumination, while wet roads cause light reflection and distort the appearance of lane and road markings. At night, color distortion occurs under limited illumination. As a result, no benchmark dataset exists and only a few developed algorithms work under poor weather conditions. To address this shortcoming, we build up a lane and road marking benchmark which consists of about 20,000 images with 17 lane and road marking classes under four different scenarios: no rain, rain, heavy rain, and night. We train and evaluate several versions of the proposed multi-task network and validate the importance of each task. The resulting approach, VPGNet, can detect and classify lanes and road markings, and predict a vanishing point with a single forward pass. Experimental results show that our approach achieves high accuracy and robustness under various conditions in real-time (20 fps). The benchmark and the VPGNet model will be publicly available.
Pixel-Level Matching for Video Object Segmentation using Convolutional Neural Networks
Aug 17, 2017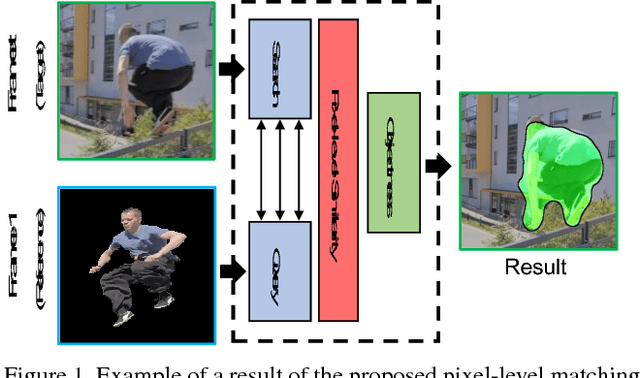
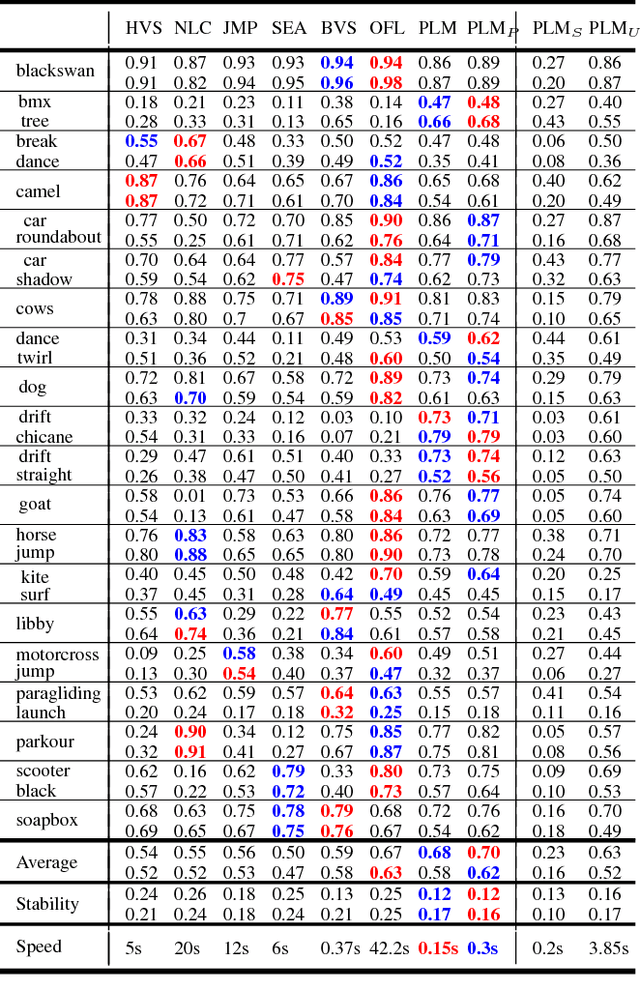
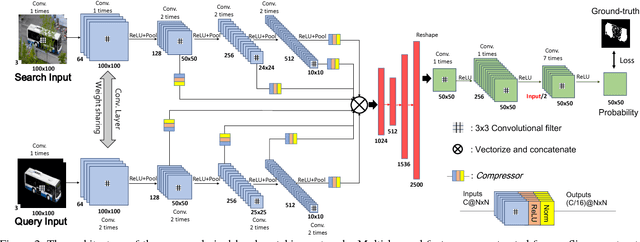
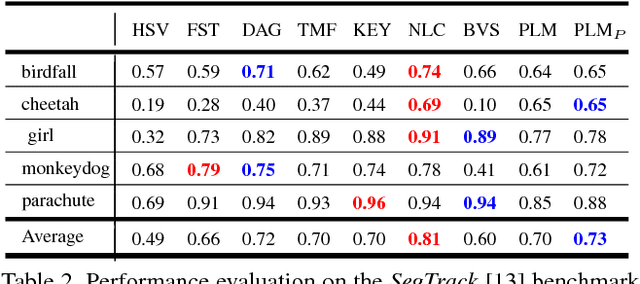
We propose a novel video object segmentation algorithm based on pixel-level matching using Convolutional Neural Networks (CNN). Our network aims to distinguish the target area from the background on the basis of the pixel-level similarity between two object units. The proposed network represents a target object using features from different depth layers in order to take advantage of both the spatial details and the category-level semantic information. Furthermore, we propose a feature compression technique that drastically reduces the memory requirements while maintaining the capability of feature representation. Two-stage training (pre-training and fine-tuning) allows our network to handle any target object regardless of its category (even if the object's type does not belong to the pre-training data) or of variations in its appearance through a video sequence. Experiments on large datasets demonstrate the effectiveness of our model - against related methods - in terms of accuracy, speed, and stability. Finally, we introduce the transferability of our network to different domains, such as the infrared data domain.
Vision System and Depth Processing for DRC-HUBO+
Sep 28, 2015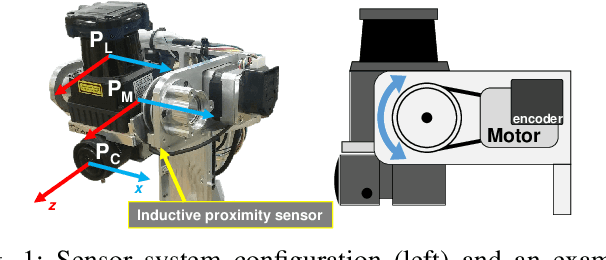
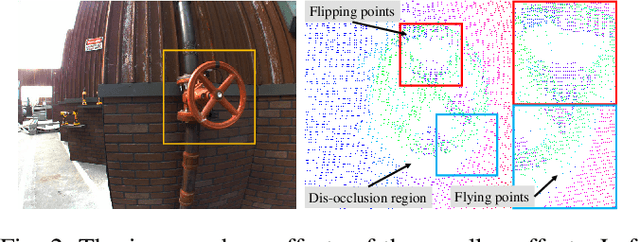
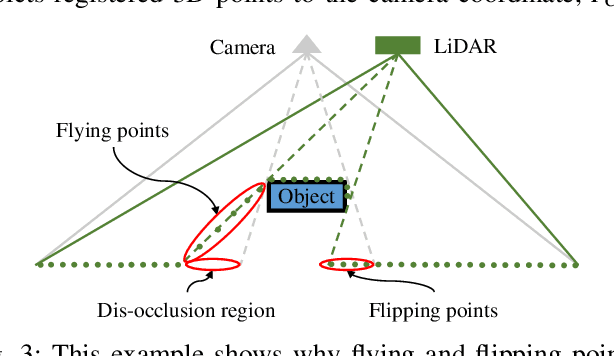
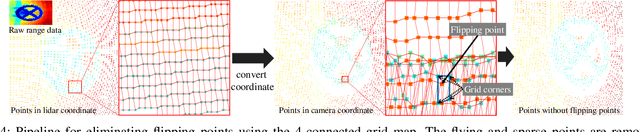
This paper presents a vision system and a depth processing algorithm for DRC-HUBO+, the winner of the DRC finals 2015. Our system is designed to reliably capture 3D information of a scene and objects robust to challenging environment conditions. We also propose a depth-map upsampling method that produces an outliers-free depth map by explicitly handling depth outliers. Our system is suitable for an interactive robot with real-world that requires accurate object detection and pose estimation. We evaluate our depth processing algorithm over state-of-the-art algorithms on several synthetic and real-world datasets.