 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRigidity-Aware 3D Gaussian Deformation from a Single Image
Sep 26, 2025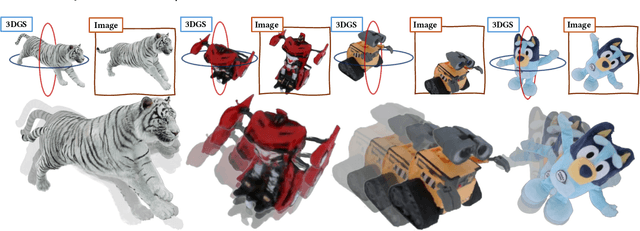
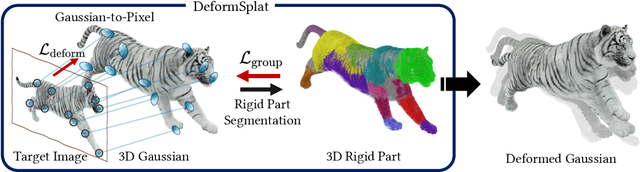

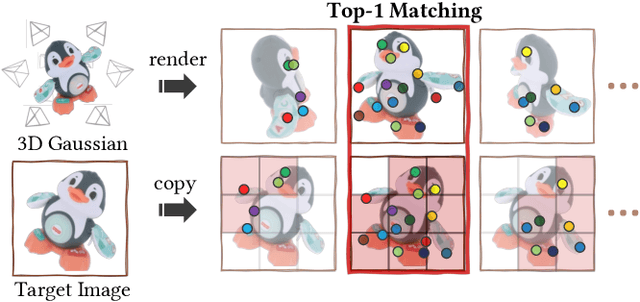
Reconstructing object deformation from a single image remains a significant challenge in computer vision and graphics. Existing methods typically rely on multi-view video to recover deformation, limiting their applicability under constrained scenarios. To address this, we propose DeformSplat, a novel framework that effectively guides 3D Gaussian deformation from only a single image. Our method introduces two main technical contributions. First, we present Gaussian-to-Pixel Matching which bridges the domain gap between 3D Gaussian representations and 2D pixel observations. This enables robust deformation guidance from sparse visual cues. Second, we propose Rigid Part Segmentation consisting of initialization and refinement. This segmentation explicitly identifies rigid regions, crucial for maintaining geometric coherence during deformation. By combining these two techniques, our approach can reconstruct consistent deformations from a single image. Extensive experiments demonstrate that our approach significantly outperforms existing methods and naturally extends to various applications,such as frame interpolation and interactive object manipulation.
LighthouseGS: Indoor Structure-aware 3D Gaussian Splatting for Panorama-Style Mobile Captures
Jul 08, 2025Recent advances in 3D Gaussian Splatting (3DGS) have enabled real-time novel view synthesis (NVS) with impressive quality in indoor scenes. However, achieving high-fidelity rendering requires meticulously captured images covering the entire scene, limiting accessibility for general users. We aim to develop a practical 3DGS-based NVS framework using simple panorama-style motion with a handheld camera (e.g., mobile device). While convenient, this rotation-dominant motion and narrow baseline make accurate camera pose and 3D point estimation challenging, especially in textureless indoor scenes. To address these challenges, we propose LighthouseGS, a novel framework inspired by the lighthouse-like sweeping motion of panoramic views. LighthouseGS leverages rough geometric priors, such as mobile device camera poses and monocular depth estimation, and utilizes the planar structures often found in indoor environments. We present a new initialization method called plane scaffold assembly to generate consistent 3D points on these structures, followed by a stable pruning strategy to enhance geometry and optimization stability. Additionally, we introduce geometric and photometric corrections to resolve inconsistencies from motion drift and auto-exposure in mobile devices. Tested on collected real and synthetic indoor scenes, LighthouseGS delivers photorealistic rendering, surpassing state-of-the-art methods and demonstrating the potential for panoramic view synthesis and object placement.
Structure-from-Sherds++: Robust Incremental 3D Reassembly of Axially Symmetric Pots from Unordered and Mixed Fragment Collections
Feb 19, 2025Reassembling multiple axially symmetric pots from fragmentary sherds is crucial for cultural heritage preservation, yet it poses significant challenges due to thin and sharp fracture surfaces that generate numerous false positive matches and hinder large-scale puzzle solving. Existing global approaches, which optimize all potential fragment pairs simultaneously or data-driven models, are prone to local minima and face scalability issues when multiple pots are intermixed. Motivated by Structure-from-Motion (SfM) for 3D reconstruction from multiple images, we propose an efficient reassembly method for axially symmetric pots based on iterative registration of one sherd at a time, called Structure-from-Sherds++ (SfS++). Our method extends beyond simple replication of incremental SfM and leverages multi-graph beam search to explore multiple registration paths. This allows us to effectively filter out indistinguishable false matches and simultaneously reconstruct multiple pots without requiring prior information such as base or the number of mixed objects. Our approach achieves 87% reassembly accuracy on a dataset of 142 real fragments from 10 different pots, outperforming other methods in handling complex fracture patterns with mixed datasets and achieving state-of-the-art performance. Code and results can be found in our project page https://sj-yoo.info/sfs/.
The Devil is in the Details: Simple Remedies for Image-to-LiDAR Representation Learning
Jan 16, 2025LiDAR is a crucial sensor in autonomous driving, commonly used alongside cameras. By exploiting this camera-LiDAR setup and recent advances in image representation learning, prior studies have shown the promising potential of image-to-LiDAR distillation. These prior arts focus on the designs of their own losses to effectively distill the pre-trained 2D image representations into a 3D model. However, the other parts of the designs have been surprisingly unexplored. We find that fundamental design elements, e.g., the LiDAR coordinate system, quantization according to the existing input interface, and data utilization, are more critical than developing loss functions, which have been overlooked in prior works. In this work, we show that simple fixes to these designs notably outperform existing methods by 16% in 3D semantic segmentation on the nuScenes dataset and 13% in 3D object detection on the KITTI dataset in downstream task performance. We focus on overlooked design choices along the spatial and temporal axes. Spatially, prior work has used cylindrical coordinate and voxel sizes without considering their side effects yielded with a commonly deployed sparse convolution layer input interface, leading to spatial quantization errors in 3D models. Temporally, existing work has avoided cumbersome data curation by discarding unsynced data, limiting the use to only the small portion of data that is temporally synced across sensors. We analyze these effects and propose simple solutions for each overlooked aspect.
A Benchmark Dataset for Collaborative SLAM in Service Environments
Nov 22, 2024



As service environments have become diverse, they have started to demand complicated tasks that are difficult for a single robot to complete. This change has led to an interest in multiple robots instead of a single robot. C-SLAM, as a fundamental technique for multiple service robots, needs to handle diverse challenges such as homogeneous scenes and dynamic objects to ensure that robots operate smoothly and perform their tasks safely. However, existing C-SLAM datasets do not include the various indoor service environments with the aforementioned challenges. To close this gap, we introduce a new multi-modal C-SLAM dataset for multiple service robots in various indoor service environments, called C-SLAM dataset in Service Environments (CSE). We use the NVIDIA Isaac Sim to generate data in various indoor service environments with the challenges that may occur in real-world service environments. By using simulation, we can provide accurate and precisely time-synchronized sensor data, such as stereo RGB, stereo depth, IMU, and ground truth (GT) poses. We configure three common indoor service environments (Hospital, Office, and Warehouse), each of which includes various dynamic objects that perform motions suitable to each environment. In addition, we drive three robots to mimic the actions of real service robots. Through these factors, we generate a more realistic C-SLAM dataset for multiple service robots. We demonstrate our dataset by evaluating diverse state-of-the-art single-robot SLAM and multi-robot SLAM methods. Our dataset is available at https://github.com/vision3d-lab/CSE_Dataset.
* 8 pages, 6 figures, Accepted to IEEE RA-L
VPOcc: Exploiting Vanishing Point for Monocular 3D Semantic Occupancy Prediction
Aug 07, 2024



Monocular 3D semantic occupancy prediction is becoming important in robot vision due to the compactness of using a single RGB camera. However, existing methods often do not adequately account for camera perspective geometry, resulting in information imbalance along the depth range of the image. To address this issue, we propose a vanishing point (VP) guided monocular 3D semantic occupancy prediction framework named VPOcc. Our framework consists of three novel modules utilizing VP. First, in the VPZoomer module, we initially utilize VP in feature extraction to achieve information balanced feature extraction across the scene by generating a zoom-in image based on VP. Second, we perform perspective geometry-aware feature aggregation by sampling points towards VP using a VP-guided cross-attention (VPCA) module. Finally, we create an information-balanced feature volume by effectively fusing original and zoom-in voxel feature volumes with a balanced feature volume fusion (BVFV) module. Experiments demonstrate that our method achieves state-of-the-art performance for both IoU and mIoU on SemanticKITTI and SSCBench-KITTI360. These results are obtained by effectively addressing the information imbalance in images through the utilization of VP. Our code will be available at www.github.com/anonymous.
DITTO: Dual and Integrated Latent Topologies for Implicit 3D Reconstruction
Mar 08, 2024We propose a novel concept of dual and integrated latent topologies (DITTO in short) for implicit 3D reconstruction from noisy and sparse point clouds. Most existing methods predominantly focus on single latent type, such as point or grid latents. In contrast, the proposed DITTO leverages both point and grid latents (i.e., dual latent) to enhance their strengths, the stability of grid latents and the detail-rich capability of point latents. Concretely, DITTO consists of dual latent encoder and integrated implicit decoder. In the dual latent encoder, a dual latent layer, which is the key module block composing the encoder, refines both latents in parallel, maintaining their distinct shapes and enabling recursive interaction. Notably, a newly proposed dynamic sparse point transformer within the dual latent layer effectively refines point latents. Then, the integrated implicit decoder systematically combines these refined latents, achieving high-fidelity 3D reconstruction and surpassing previous state-of-the-art methods on object- and scene-level datasets, especially in thin and detailed structures.
AiSDF: Structure-aware Neural Signed Distance Fields in Indoor Scenes
Mar 04, 2024



Indoor scenes we are living in are visually homogenous or textureless, while they inherently have structural forms and provide enough structural priors for 3D scene reconstruction. Motivated by this fact, we propose a structure-aware online signed distance fields (SDF) reconstruction framework in indoor scenes, especially under the Atlanta world (AW) assumption. Thus, we dub this incremental SDF reconstruction for AW as AiSDF. Within the online framework, we infer the underlying Atlanta structure of a given scene and then estimate planar surfel regions supporting the Atlanta structure. This Atlanta-aware surfel representation provides an explicit planar map for a given scene. In addition, based on these Atlanta planar surfel regions, we adaptively sample and constrain the structural regularity in the SDF reconstruction, which enables us to improve the reconstruction quality by maintaining a high-level structure while enhancing the details of a given scene. We evaluate the proposed AiSDF on the ScanNet and ReplicaCAD datasets, where we demonstrate that the proposed framework is capable of reconstructing fine details of objects implicitly, as well as structures explicitly in room-scale scenes.
ContactGen: Contact-Guided Interactive 3D Human Generation for Partners
Feb 03, 2024Among various interactions between humans, such as eye contact and gestures, physical interactions by contact can act as an essential moment in understanding human behaviors. Inspired by this fact, given a 3D partner human with the desired interaction label, we introduce a new task of 3D human generation in terms of physical contact. Unlike previous works of interacting with static objects or scenes, a given partner human can have diverse poses and different contact regions according to the type of interaction. To handle this challenge, we propose a novel method of generating interactive 3D humans for a given partner human based on a guided diffusion framework. Specifically, we newly present a contact prediction module that adaptively estimates potential contact regions between two input humans according to the interaction label. Using the estimated potential contact regions as complementary guidances, we dynamically enforce ContactGen to generate interactive 3D humans for a given partner human within a guided diffusion model. We demonstrate ContactGen on the CHI3D dataset, where our method generates physically plausible and diverse poses compared to comparison methods.
FishRecGAN: An End to End GAN Based Network for Fisheye Rectification and Calibration
May 09, 2023



We propose an end-to-end deep learning approach to rectify fisheye images and simultaneously calibrate camera intrinsic and distortion parameters. Our method consists of two parts: a Quick Image Rectification Module developed with a Pix2Pix GAN and Wasserstein GAN (W-Pix2PixGAN), and a Calibration Module with a CNN architecture. Our Quick Rectification Network performs robust rectification with good resolution, making it suitable for constant calibration in camera-based surveillance equipment. To achieve high-quality calibration, we use the straightened output from the Quick Rectification Module as a guidance-like semantic feature map for the Calibration Module to learn the geometric relationship between the straightened feature and the distorted feature. We train and validate our method with a large synthesized dataset labeled with well-simulated parameters applied to a perspective image dataset. Our solution has achieved robust performance in high-resolution with a significant PSNR value of 22.343.