 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality over Quantity: Demonstration Curation via Influence Functions for Data-Centric Robot Learning
Mar 10, 2026Learning from demonstrations has emerged as a promising paradigm for end-to-end robot control, particularly when scaled to diverse and large datasets. However, the quality of demonstration data, often collected through human teleoperation, remains a critical bottleneck for effective data-driven robot learning. Human errors, operational constraints, and teleoperator variability introduce noise and suboptimal behaviors, making data curation essential yet largely manual and heuristic-driven. In this work, we propose Quality over Quantity (QoQ), a grounded and systematic approach to identifying high-quality data by defining data quality as the contribution of each training sample to reducing loss on validation demonstrations. To efficiently estimate this contribution, we leverage influence functions, which quantify the impact of individual training samples on model performance. We further introduce two key techniques to adapt influence functions for robot demonstrations: (i) using maximum influence across validation samples to capture the most relevant state-action pairs, and (ii) aggregating influence scores of state-action pairs within the same trajectory to reduce noise and improve data coverage. Experiments in both simulated and real-world settings show that QoQ consistently improves policy performances over prior data selection methods.
Towards Autonomous Mathematics Research
Feb 12, 2026Recent advances in foundational models have yielded reasoning systems capable of achieving a gold-medal standard at the International Mathematical Olympiad. The transition from competition-level problem-solving to professional research, however, requires navigating vast literature and constructing long-horizon proofs. In this work, we introduce Aletheia, a math research agent that iteratively generates, verifies, and revises solutions end-to-end in natural language. Specifically, Aletheia is powered by an advanced version of Gemini Deep Think for challenging reasoning problems, a novel inference-time scaling law that extends beyond Olympiad-level problems, and intensive tool use to navigate the complexities of mathematical research. We demonstrate the capability of Aletheia from Olympiad problems to PhD-level exercises and most notably, through several distinct milestones in AI-assisted mathematics research: (a) a research paper (Feng26) generated by AI without any human intervention in calculating certain structure constants in arithmetic geometry called eigenweights; (b) a research paper (LeeSeo26) demonstrating human-AI collaboration in proving bounds on systems of interacting particles called independent sets; and (c) an extensive semi-autonomous evaluation (Feng et al., 2026a) of 700 open problems on Bloom's Erdos Conjectures database, including autonomous solutions to four open questions. In order to help the public better understand the developments pertaining to AI and mathematics, we suggest quantifying standard levels of autonomy and novelty of AI-assisted results, as well as propose a novel concept of human-AI interaction cards for transparency. We conclude with reflections on human-AI collaboration in mathematics and share all prompts as well as model outputs at https://github.com/google-deepmind/superhuman/tree/main/aletheia.
Revisiting Reliability in the Reasoning-based Pose Estimation Benchmark
Jul 17, 2025The reasoning-based pose estimation (RPE) benchmark has emerged as a widely adopted evaluation standard for pose-aware multimodal large language models (MLLMs). Despite its significance, we identified critical reproducibility and benchmark-quality issues that hinder fair and consistent quantitative evaluations. Most notably, the benchmark utilizes different image indices from those of the original 3DPW dataset, forcing researchers into tedious and error-prone manual matching processes to obtain accurate ground-truth (GT) annotations for quantitative metrics (\eg, MPJPE, PA-MPJPE). Furthermore, our analysis reveals several inherent benchmark-quality limitations, including significant image redundancy, scenario imbalance, overly simplistic poses, and ambiguous textual descriptions, collectively undermining reliable evaluations across diverse scenarios. To alleviate manual effort and enhance reproducibility, we carefully refined the GT annotations through meticulous visual matching and publicly release these refined annotations as an open-source resource, thereby promoting consistent quantitative evaluations and facilitating future advancements in human pose-aware multimodal reasoning.
Test-Time Adaptation with Binary Feedback
May 24, 2025


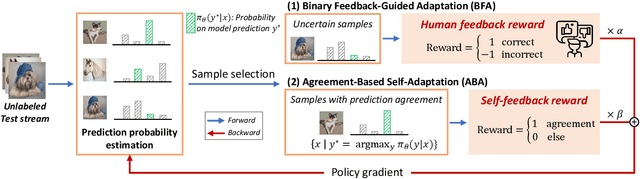
Deep learning models perform poorly when domain shifts exist between training and test data. Test-time adaptation (TTA) is a paradigm to mitigate this issue by adapting pre-trained models using only unlabeled test samples. However, existing TTA methods can fail under severe domain shifts, while recent active TTA approaches requiring full-class labels are impractical due to high labeling costs. To address this issue, we introduce a new setting of TTA with binary feedback. This setting uses a few binary feedback inputs from annotators to indicate whether model predictions are correct, thereby significantly reducing the labeling burden of annotators. Under the setting, we propose BiTTA, a novel dual-path optimization framework that leverages reinforcement learning to balance binary feedback-guided adaptation on uncertain samples with agreement-based self-adaptation on confident predictions. Experiments show BiTTA achieves 13.3%p accuracy improvements over state-of-the-art baselines, demonstrating its effectiveness in handling severe distribution shifts with minimal labeling effort. The source code is available at https://github.com/taeckyung/BiTTA.
Diffusion Meets Few-shot Class Incremental Learning
Mar 30, 2025Few-shot class-incremental learning (FSCIL) is challenging due to extremely limited training data; while aiming to reduce catastrophic forgetting and learn new information. We propose Diffusion-FSCIL, a novel approach that employs a text-to-image diffusion model as a frozen backbone. Our conjecture is that FSCIL can be tackled using a large generative model's capabilities benefiting from 1) generation ability via large-scale pre-training; 2) multi-scale representation; 3) representational flexibility through the text encoder. To maximize the representation capability, we propose to extract multiple complementary diffusion features to play roles as latent replay with slight support from feature distillation for preventing generative biases. Our framework realizes efficiency through 1) using a frozen backbone; 2) minimal trainable components; 3) batch processing of multiple feature extractions. Extensive experiments on CUB-200, miniImageNet, and CIFAR-100 show that Diffusion-FSCIL surpasses state-of-the-art methods, preserving performance on previously learned classes and adapting effectively to new ones.
LoRA Training Provably Converges to a Low-Rank Global Minimum or It Fails Loudly (But it Probably Won't Fail)
Feb 13, 2025Low-rank adaptation (LoRA) has become a standard approach for fine-tuning large foundation models. However, our theoretical understanding of LoRA remains limited as prior analyses of LoRA's training dynamics either rely on linearization arguments or consider highly simplified setups. In this work, we analyze the LoRA loss landscape without such restrictive assumptions. We define two regimes: a ``special regime'', which includes idealized setups where linearization arguments hold, and a ``generic regime'' representing more realistic setups where linearization arguments do not hold. In the generic regime, we show that LoRA training converges to a global minimizer with low rank and small magnitude, or a qualitatively distinct solution with high rank and large magnitude. Finally, we argue that the zero-initialization and weight decay in LoRA training induce an implicit bias toward the low-rank, small-magnitude region of the parameter space -- where global minima lie -- thus shedding light on why LoRA training usually succeeds in finding global minima.
B-RIGHT: Benchmark Re-evaluation for Integrity in Generalized Human-Object Interaction Testing
Jan 28, 2025Human-object interaction (HOI) is an essential problem in artificial intelligence (AI) which aims to understand the visual world that involves complex relationships between humans and objects. However, current benchmarks such as HICO-DET face the following limitations: (1) severe class imbalance and (2) varying number of train and test sets for certain classes. These issues can potentially lead to either inflation or deflation of model performance during evaluation, ultimately undermining the reliability of evaluation scores. In this paper, we propose a systematic approach to develop a new class-balanced dataset, Benchmark Re-evaluation for Integrity in Generalized Human-object Interaction Testing (B-RIGHT), that addresses these imbalanced problems. B-RIGHT achieves class balance by leveraging balancing algorithm and automated generation-and-filtering processes, ensuring an equal number of instances for each HOI class. Furthermore, we design a balanced zero-shot test set to systematically evaluate models on unseen scenario. Re-evaluating existing models using B-RIGHT reveals substantial the reduction of score variance and changes in performance rankings compared to conventional HICO-DET. Our experiments demonstrate that evaluation under balanced conditions ensure more reliable and fair model comparisons.
Unsupervised-to-Online Reinforcement Learning
Aug 27, 2024Offline-to-online reinforcement learning (RL), a framework that trains a policy with offline RL and then further fine-tunes it with online RL, has been considered a promising recipe for data-driven decision-making. While sensible, this framework has drawbacks: it requires domain-specific offline RL pre-training for each task, and is often brittle in practice. In this work, we propose unsupervised-to-online RL (U2O RL), which replaces domain-specific supervised offline RL with unsupervised offline RL, as a better alternative to offline-to-online RL. U2O RL not only enables reusing a single pre-trained model for multiple downstream tasks, but also learns better representations, which often result in even better performance and stability than supervised offline-to-online RL. To instantiate U2O RL in practice, we propose a general recipe for U2O RL to bridge task-agnostic unsupervised offline skill-based policy pre-training and supervised online fine-tuning. Throughout our experiments in nine state-based and pixel-based environments, we empirically demonstrate that U2O RL achieves strong performance that matches or even outperforms previous offline-to-online RL approaches, while being able to reuse a single pre-trained model for a number of different downstream tasks.
VPOcc: Exploiting Vanishing Point for Monocular 3D Semantic Occupancy Prediction
Aug 07, 2024



Monocular 3D semantic occupancy prediction is becoming important in robot vision due to the compactness of using a single RGB camera. However, existing methods often do not adequately account for camera perspective geometry, resulting in information imbalance along the depth range of the image. To address this issue, we propose a vanishing point (VP) guided monocular 3D semantic occupancy prediction framework named VPOcc. Our framework consists of three novel modules utilizing VP. First, in the VPZoomer module, we initially utilize VP in feature extraction to achieve information balanced feature extraction across the scene by generating a zoom-in image based on VP. Second, we perform perspective geometry-aware feature aggregation by sampling points towards VP using a VP-guided cross-attention (VPCA) module. Finally, we create an information-balanced feature volume by effectively fusing original and zoom-in voxel feature volumes with a balanced feature volume fusion (BVFV) module. Experiments demonstrate that our method achieves state-of-the-art performance for both IoU and mIoU on SemanticKITTI and SSCBench-KITTI360. These results are obtained by effectively addressing the information imbalance in images through the utilization of VP. Our code will be available at www.github.com/anonymous.
VLM-PL: Advanced Pseudo Labeling approach Class Incremental Object Detection with Vision-Language Model
Mar 08, 2024



In the field of Class Incremental Object Detection (CIOD), creating models that can continuously learn like humans is a major challenge. Pseudo-labeling methods, although initially powerful, struggle with multi-scenario incremental learning due to their tendency to forget past knowledge. To overcome this, we introduce a new approach called Vision-Language Model assisted Pseudo-Labeling (VLM-PL). This technique uses Vision-Language Model (VLM) to verify the correctness of pseudo ground-truths (GTs) without requiring additional model training. VLM-PL starts by deriving pseudo GTs from a pre-trained detector. Then, we generate custom queries for each pseudo GT using carefully designed prompt templates that combine image and text features. This allows the VLM to classify the correctness through its responses. Furthermore, VLM-PL integrates refined pseudo and real GTs from upcoming training, effectively combining new and old knowledge. Extensive experiments conducted on the Pascal VOC and MS COCO datasets not only highlight VLM-PL's exceptional performance in multi-scenario but also illuminate its effectiveness in dual-scenario by achieving state-of-the-art results in both.