 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Eyes Betray AI: Social Gaze Consistency as a Semantic Cue for AI-Generated Image Detection
May 27, 2026Recent generative models have largely closed the gap on low-level artifacts - pixel fingerprints, frequency anomalies, upsampling traces - particularly in person-centric and partial-edit settings where the manipulated region is small and surrounded by photometrically authentic content. We introduce Social Gaze Consistency, a high-level semantic cue defined as the mutual coherence of gaze direction, head-eye alignment, and pupil placement between interacting individuals, and show that it constitutes a previously underutilized detection axis orthogonal to existing low-level paradigms. We instantiate this insight through three coupled mechanisms: (i) a controlled diagnostic dataset with region-specific perturbations of gaze-consistent imagery, where strict pair-level grouping forecloses generator-fingerprint memorization as an optimization-time shortcut rather than relying on augmentation; (ii) Block-Compositional Caption Supervision, which holds a single 5-block reasoning skeleton invariant across 1,250 macro-combined captions, decoupling reasoning consistency from surface diversity; (iii) Cross-architecture validation showing the same supervision improves a vision-language backbone (FakeVLM) by +3.7 pp on the COCOAI Interaction subset (balanced accuracy 67.8 -> 71.5) and +1.3 pp on the COCOAI Person subset (83.0 -> 84.3), with consistent gains on a vision-only backbone (Effort), evidencing a backbone-agnostic cue. Real- and fake-class recalls rise simultaneously, ruling out a "predict-all-fake" artifact. A four-step mechanistic account - paired-edit shortcut blocking, hard-to-easy difficulty transfer, CLIP prior preservation, and diffusion-family shared spectral weakness in periocular structure - explains why training on a single inpainter (FLUX.1-Fill) transfers to multi-generator suites. We will release the code upon acceptance to facilitate reproducibility.
OpenFS: Multi-Hand-Capable Fingerspelling Recognition with Implicit Signing-Hand Detection and Frame-Wise Letter-Conditioned Synthesis
Feb 26, 2026Fingerspelling is a component of sign languages in which words are spelled out letter by letter using specific hand poses. Automatic fingerspelling recognition plays a crucial role in bridging the communication gap between Deaf and hearing communities, yet it remains challenging due to the signing-hand ambiguity issue, the lack of appropriate training losses, and the out-of-vocabulary (OOV) problem. Prior fingerspelling recognition methods rely on explicit signing-hand detection, which often leads to recognition failures, and on a connectionist temporal classification (CTC) loss, which exhibits the peaky behavior problem. To address these issues, we develop OpenFS, an open-source approach for fingerspelling recognition and synthesis. We propose a multi-hand-capable fingerspelling recognizer that supports both single- and multi-hand inputs and performs implicit signing-hand detection by incorporating a dual-level positional encoding and a signing-hand focus (SF) loss. The SF loss encourages cross-attention to focus on the signing hand, enabling implicit signing-hand detection during recognition. Furthermore, without relying on the CTC loss, we introduce a monotonic alignment (MA) loss that enforces the output letter sequence to follow the temporal order of the input pose sequence through cross-attention regularization. In addition, we propose a frame-wise letter-conditioned generator that synthesizes realistic fingerspelling pose sequences for OOV words. This generator enables the construction of a new synthetic benchmark, called FSNeo. Through comprehensive experiments, we demonstrate that our approach achieves state-of-the-art performance in recognition and validate the effectiveness of the proposed recognizer and generator. Codes and data are available in: https://github.com/JunukCha/OpenFS.
CoT-Pose: Chain-of-Thought Reasoning for 3D Pose Generation from Abstract Prompts
Aug 11, 2025Recent advances in multi-modal large language models (MLLMs) and chain-of-thought (CoT) reasoning have led to significant progress in image and text generation tasks. However, the field of 3D human pose generation still faces critical limitations. Most existing text-to-pose models rely heavily on detailed (low-level) prompts that explicitly describe joint configurations. In contrast, humans tend to communicate actions and intentions using abstract (high-level) language. This mismatch results in a practical challenge for deploying pose generation systems in real-world scenarios. To bridge this gap, we introduce a novel framework that incorporates CoT reasoning into the pose generation process, enabling the interpretation of abstract prompts into accurate 3D human poses. We further propose a data synthesis pipeline that automatically generates triplets of abstract prompts, detailed prompts, and corresponding 3D poses for training process. Experimental results demonstrate that our reasoning-enhanced model, CoT-Pose, can effectively generate plausible and semantically aligned poses from abstract textual inputs. This work highlights the importance of high-level understanding in pose generation and opens new directions for reasoning-enhanced approach for human pose generation.
Leveraging 2D Masked Reconstruction for Domain Adaptation of 3D Pose Estimation
Jan 14, 2025



RGB-based 3D pose estimation methods have been successful with the development of deep learning and the emergence of high-quality 3D pose datasets. However, most existing methods do not operate well for testing images whose distribution is far from that of training data. However, most existing methods do not operate well for testing images whose distribution is far from that of training data. This problem might be alleviated by involving diverse data during training, however it is non-trivial to collect such diverse data with corresponding labels (i.e. 3D pose). In this paper, we introduced an unsupervised domain adaptation framework for 3D pose estimation that utilizes the unlabeled data in addition to labeled data via masked image modeling (MIM) framework. Foreground-centric reconstruction and attention regularization are further proposed to increase the effectiveness of unlabeled data usage. Experiments are conducted on the various datasets in human and hand pose estimation tasks, especially using the cross-domain scenario. We demonstrated the effectiveness of ours by achieving the state-of-the-art accuracy on all datasets.
Text2HOI: Text-guided 3D Motion Generation for Hand-Object Interaction
Apr 02, 2024This paper introduces the first text-guided work for generating the sequence of hand-object interaction in 3D. The main challenge arises from the lack of labeled data where existing ground-truth datasets are nowhere near generalizable in interaction type and object category, which inhibits the modeling of diverse 3D hand-object interaction with the correct physical implication (e.g., contacts and semantics) from text prompts. To address this challenge, we propose to decompose the interaction generation task into two subtasks: hand-object contact generation; and hand-object motion generation. For contact generation, a VAE-based network takes as input a text and an object mesh, and generates the probability of contacts between the surfaces of hands and the object during the interaction. The network learns a variety of local geometry structure of diverse objects that is independent of the objects' category, and thus, it is applicable to general objects. For motion generation, a Transformer-based diffusion model utilizes this 3D contact map as a strong prior for generating physically plausible hand-object motion as a function of text prompts by learning from the augmented labeled dataset; where we annotate text labels from many existing 3D hand and object motion data. Finally, we further introduce a hand refiner module that minimizes the distance between the object surface and hand joints to improve the temporal stability of the object-hand contacts and to suppress the penetration artifacts. In the experiments, we demonstrate that our method can generate more realistic and diverse interactions compared to other baseline methods. We also show that our method is applicable to unseen objects. We will release our model and newly labeled data as a strong foundation for future research. Codes and data are available in: https://github.com/JunukCha/Text2HOI.
VLM-PL: Advanced Pseudo Labeling approach Class Incremental Object Detection with Vision-Language Model
Mar 08, 2024



In the field of Class Incremental Object Detection (CIOD), creating models that can continuously learn like humans is a major challenge. Pseudo-labeling methods, although initially powerful, struggle with multi-scenario incremental learning due to their tendency to forget past knowledge. To overcome this, we introduce a new approach called Vision-Language Model assisted Pseudo-Labeling (VLM-PL). This technique uses Vision-Language Model (VLM) to verify the correctness of pseudo ground-truths (GTs) without requiring additional model training. VLM-PL starts by deriving pseudo GTs from a pre-trained detector. Then, we generate custom queries for each pseudo GT using carefully designed prompt templates that combine image and text features. This allows the VLM to classify the correctness through its responses. Furthermore, VLM-PL integrates refined pseudo and real GTs from upcoming training, effectively combining new and old knowledge. Extensive experiments conducted on the Pascal VOC and MS COCO datasets not only highlight VLM-PL's exceptional performance in multi-scenario but also illuminate its effectiveness in dual-scenario by achieving state-of-the-art results in both.
SDDGR: Stable Diffusion-based Deep Generative Replay for Class Incremental Object Detection
Feb 27, 2024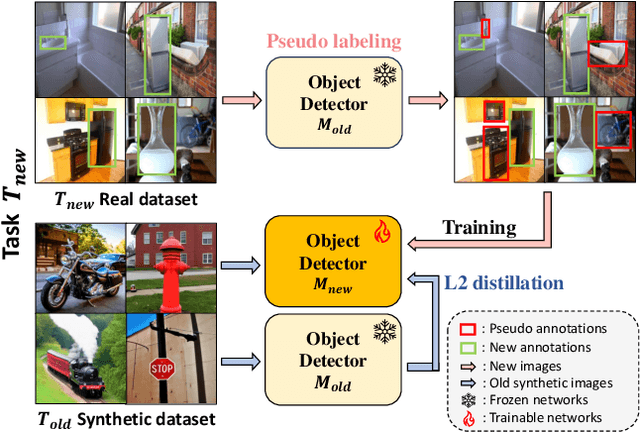
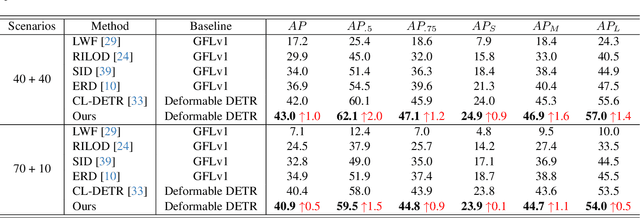
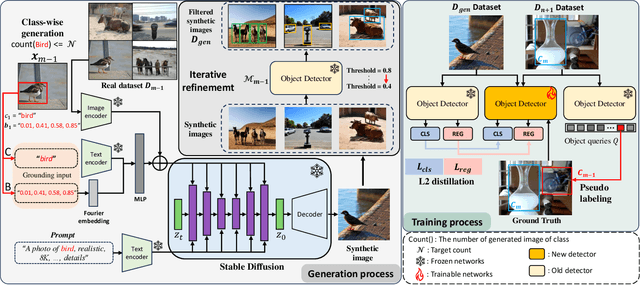
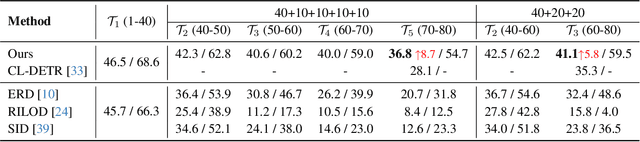
In the field of class incremental learning (CIL), genera- tive replay has become increasingly prominent as a method to mitigate the catastrophic forgetting, alongside the con- tinuous improvements in generative models. However, its application in class incremental object detection (CIOD) has been significantly limited, primarily due to the com- plexities of scenes involving multiple labels. In this paper, we propose a novel approach called stable diffusion deep generative replay (SDDGR) for CIOD. Our method utilizes a diffusion-based generative model with pre-trained text- to-diffusion networks to generate realistic and diverse syn- thetic images. SDDGR incorporates an iterative refinement strategy to produce high-quality images encompassing old classes. Additionally, we adopt an L2 knowledge distilla- tion technique to improve the retention of prior knowledge in synthetic images. Furthermore, our approach includes pseudo-labeling for old objects within new task images, pre- venting misclassification as background elements. Exten- sive experiments on the COCO 2017 dataset demonstrate that SDDGR significantly outperforms existing algorithms, achieving a new state-of-the-art in various CIOD scenarios. The source code will be made available to the public.
Class-Wise Buffer Management for Incremental Object Detection: An Effective Buffer Training Strategy
Dec 14, 2023



Class incremental learning aims to solve a problem that arises when continuously adding unseen class instances to an existing model This approach has been extensively studied in the context of image classification; however its applicability to object detection is not well established yet. Existing frameworks using replay methods mainly collect replay data without considering the model being trained and tend to rely on randomness or the number of labels of each sample. Also, despite the effectiveness of the replay, it was not yet optimized for the object detection task. In this paper, we introduce an effective buffer training strategy (eBTS) that creates the optimized replay buffer on object detection. Our approach incorporates guarantee minimum and hierarchical sampling to establish the buffer customized to the trained model. %These methods can facilitate effective retrieval of prior knowledge. Furthermore, we use the circular experience replay training to optimally utilize the accumulated buffer data. Experiments on the MS COCO dataset demonstrate that our eBTS achieves state-of-the-art performance compared to the existing replay schemes.
Image-free Domain Generalization via CLIP for 3D Hand Pose Estimation
Oct 30, 2022



RGB-based 3D hand pose estimation has been successful for decades thanks to large-scale databases and deep learning. However, the hand pose estimation network does not operate well for hand pose images whose characteristics are far different from the training data. This is caused by various factors such as illuminations, camera angles, diverse backgrounds in the input images, etc. Many existing methods tried to solve it by supplying additional large-scale unconstrained/target domain images to augment data space; however collecting such large-scale images takes a lot of labors. In this paper, we present a simple image-free domain generalization approach for the hand pose estimation framework that uses only source domain data. We try to manipulate the image features of the hand pose estimation network by adding the features from text descriptions using the CLIP (Contrastive Language-Image Pre-training) model. The manipulated image features are then exploited to train the hand pose estimation network via the contrastive learning framework. In experiments with STB and RHD datasets, our algorithm shows improved performance over the state-of-the-art domain generalization approaches.
Sequential Movie Genre Prediction using Average Transition Probability with Clustering
Nov 04, 2021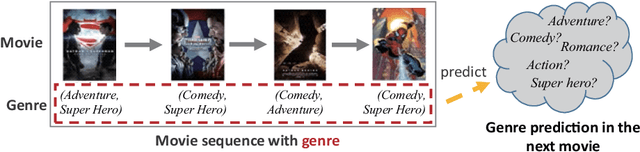
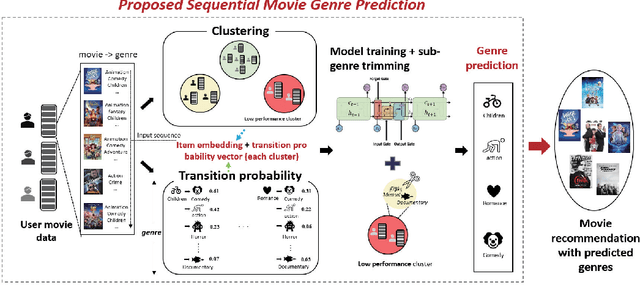
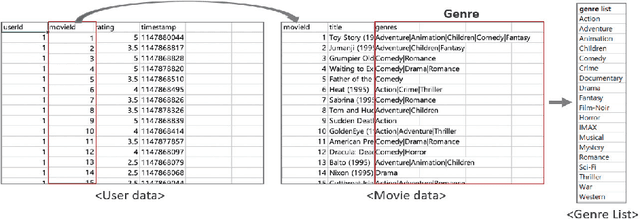
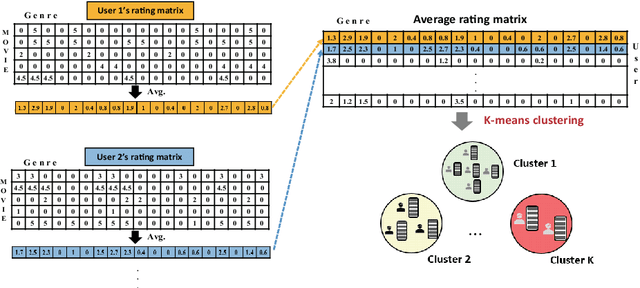
In recent movie recommendations, predicting the user's sequential behavior and suggesting the next movie to watch is one of the most important issues. However, capturing such sequential behavior is not easy because each user's short-term or long-term behavior must be taken into account. For this reason, many research results show that the performance of recommending a specific movie is not very high in a sequential recommendation. In this paper, we propose a cluster-based method for classifying users with similar movie purchase patterns and a movie genre prediction algorithm rather than the movie itself considering their short-term and long-term behaviors. The movie genre prediction does not recommend a specific movie, but it predicts the genre for the next movie to watch in consideration of each user's preference for the movie genre based on the genre included in the movie. Through this, it is possible to provide appropriate guidelines for recommending movies including the genre to users who tend to prefer a specific genre. In particular, in this paper, users with similar genre preferences are organized into clusters to recommend genres, and in clusters that do not have relatively specific tendencies, genre prediction is performed by appropriately trimming genres that are not necessary for recommendation in order to improve performance. We evaluate our method on well-known movie datasets, and qualitatively that it captures personalized dynamics and is able to make meaningful recommendations.