 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQORT-Former: Query-optimized Real-time Transformer for Understanding Two Hands Manipulating Objects
Feb 27, 2025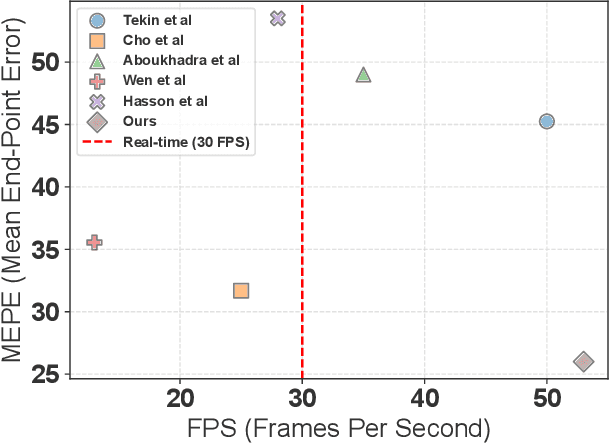
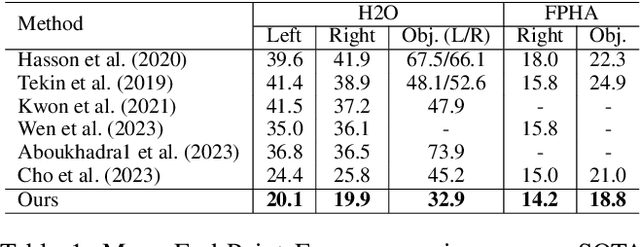
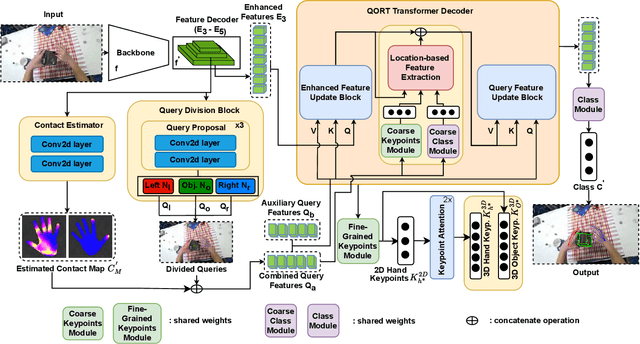
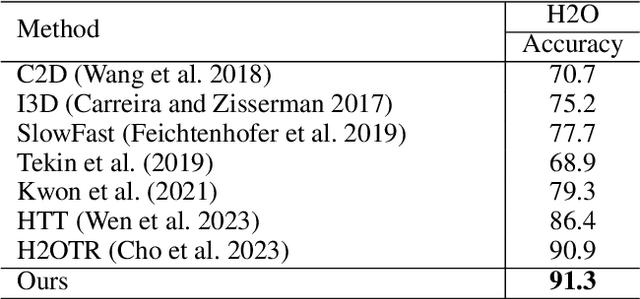
Significant advancements have been achieved in the realm of understanding poses and interactions of two hands manipulating an object. The emergence of augmented reality (AR) and virtual reality (VR) technologies has heightened the demand for real-time performance in these applications. However, current state-of-the-art models often exhibit promising results at the expense of substantial computational overhead. In this paper, we present a query-optimized real-time Transformer (QORT-Former), the first Transformer-based real-time framework for 3D pose estimation of two hands and an object. We first limit the number of queries and decoders to meet the efficiency requirement. Given limited number of queries and decoders, we propose to optimize queries which are taken as input to the Transformer decoder, to secure better accuracy: (1) we propose to divide queries into three types (a left hand query, a right hand query and an object query) and enhance query features (2) by using the contact information between hands and an object and (3) by using three-step update of enhanced image and query features with respect to one another. With proposed methods, we achieved real-time pose estimation performance using just 108 queries and 1 decoder (53.5 FPS on an RTX 3090TI GPU). Surpassing state-of-the-art results on the H2O dataset by 17.6% (left hand), 22.8% (right hand), and 27.2% (object), as well as on the FPHA dataset by 5.3% (right hand) and 10.4% (object), our method excels in accuracy. Additionally, it sets the state-of-the-art in interaction recognition, maintaining real-time efficiency with an off-the-shelf action recognition module.
Image-free Domain Generalization via CLIP for 3D Hand Pose Estimation
Oct 30, 2022



RGB-based 3D hand pose estimation has been successful for decades thanks to large-scale databases and deep learning. However, the hand pose estimation network does not operate well for hand pose images whose characteristics are far different from the training data. This is caused by various factors such as illuminations, camera angles, diverse backgrounds in the input images, etc. Many existing methods tried to solve it by supplying additional large-scale unconstrained/target domain images to augment data space; however collecting such large-scale images takes a lot of labors. In this paper, we present a simple image-free domain generalization approach for the hand pose estimation framework that uses only source domain data. We try to manipulate the image features of the hand pose estimation network by adding the features from text descriptions using the CLIP (Contrastive Language-Image Pre-training) model. The manipulated image features are then exploited to train the hand pose estimation network via the contrastive learning framework. In experiments with STB and RHD datasets, our algorithm shows improved performance over the state-of-the-art domain generalization approaches.