 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaPa: Carve-n-Paint Synthesis for Efficient 4K Textured Mesh Generation
Jan 16, 2025The synthesis of high-quality 3D assets from textual or visual inputs has become a central objective in modern generative modeling. Despite the proliferation of 3D generation algorithms, they frequently grapple with challenges such as multi-view inconsistency, slow generation times, low fidelity, and surface reconstruction problems. While some studies have addressed some of these issues, a comprehensive solution remains elusive. In this paper, we introduce \textbf{CaPa}, a carve-and-paint framework that generates high-fidelity 3D assets efficiently. CaPa employs a two-stage process, decoupling geometry generation from texture synthesis. Initially, a 3D latent diffusion model generates geometry guided by multi-view inputs, ensuring structural consistency across perspectives. Subsequently, leveraging a novel, model-agnostic Spatially Decoupled Attention, the framework synthesizes high-resolution textures (up to 4K) for a given geometry. Furthermore, we propose a 3D-aware occlusion inpainting algorithm that fills untextured regions, resulting in cohesive results across the entire model. This pipeline generates high-quality 3D assets in less than 30 seconds, providing ready-to-use outputs for commercial applications. Experimental results demonstrate that CaPa excels in both texture fidelity and geometric stability, establishing a new standard for practical, scalable 3D asset generation.
HOReeNet: 3D-aware Hand-Object Grasping Reenactment
Nov 11, 2022
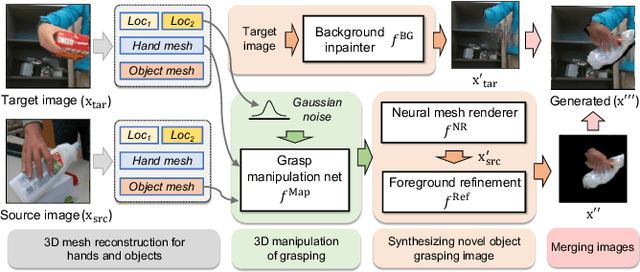

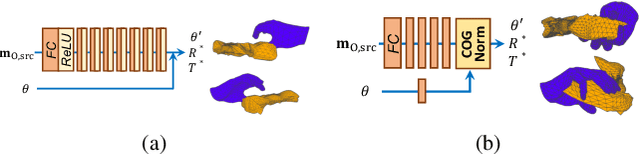
We present HOReeNet, which tackles the novel task of manipulating images involving hands, objects, and their interactions. Especially, we are interested in transferring objects of source images to target images and manipulating 3D hand postures to tightly grasp the transferred objects. Furthermore, the manipulation needs to be reflected in the 2D image space. In our reenactment scenario involving hand-object interactions, 3D reconstruction becomes essential as 3D contact reasoning between hands and objects is required to achieve a tight grasp. At the same time, to obtain high-quality 2D images from 3D space, well-designed 3D-to-2D projection and image refinement are required. Our HOReeNet is the first fully differentiable framework proposed for such a task. On hand-object interaction datasets, we compared our HOReeNet to the conventional image translation algorithms and reenactment algorithm. We demonstrated that our approach could achieved the state-of-the-art on the proposed task.
Image-free Domain Generalization via CLIP for 3D Hand Pose Estimation
Oct 30, 2022



RGB-based 3D hand pose estimation has been successful for decades thanks to large-scale databases and deep learning. However, the hand pose estimation network does not operate well for hand pose images whose characteristics are far different from the training data. This is caused by various factors such as illuminations, camera angles, diverse backgrounds in the input images, etc. Many existing methods tried to solve it by supplying additional large-scale unconstrained/target domain images to augment data space; however collecting such large-scale images takes a lot of labors. In this paper, we present a simple image-free domain generalization approach for the hand pose estimation framework that uses only source domain data. We try to manipulate the image features of the hand pose estimation network by adding the features from text descriptions using the CLIP (Contrastive Language-Image Pre-training) model. The manipulated image features are then exploited to train the hand pose estimation network via the contrastive learning framework. In experiments with STB and RHD datasets, our algorithm shows improved performance over the state-of-the-art domain generalization approaches.
Transformer-based Global 3D Hand Pose Estimation in Two Hands Manipulating Objects Scenarios
Oct 20, 2022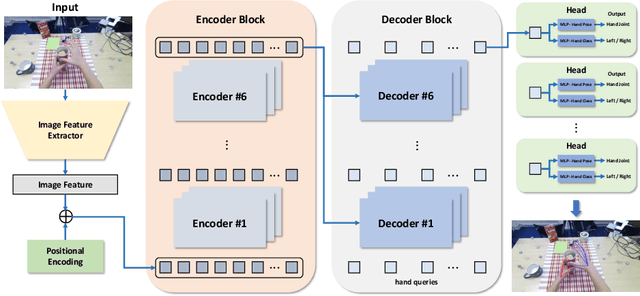
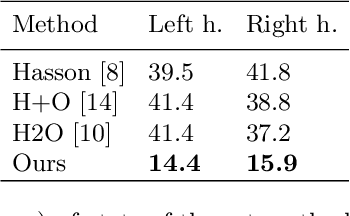
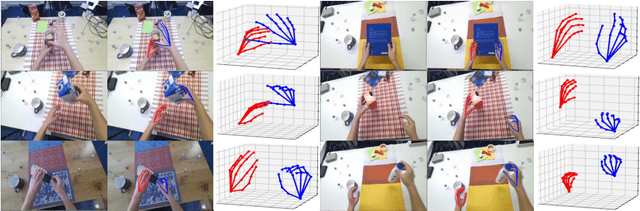

This report describes our 1st place solution to ECCV 2022 challenge on Human Body, Hands, and Activities (HBHA) from Egocentric and Multi-view Cameras (hand pose estimation). In this challenge, we aim to estimate global 3D hand poses from the input image where two hands and an object are interacting on the egocentric viewpoint. Our proposed method performs end-to-end multi-hand pose estimation via transformer architecture. In particular, our method robustly estimates hand poses in a scenario where two hands interact. Additionally, we propose an algorithm that considers hand scales to robustly estimate the absolute depth. The proposed algorithm works well even when the hand sizes are various for each person. Our method attains 14.4 mm (left) and 15.9 mm (right) errors for each hand in the test set.