 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Cartography: Mapping the Latent Landscape of AI Benchmark Ecosystems
May 24, 2026While aggregate leaderboard scores drive AI development, they contain substantial measurement noise whose sources and magnitudes remain unquantified, making it unclear when rankings reflect genuine capability differences versus evaluation artifacts. We introduce a framework for measuring the latent landscape in AI benchmark ecosystems. Applying Confirmatory Factor Analysis (CFA) and Generalizability Theory to 4,000+ models from the Open LLM Leaderboard, we decompose sources of ranking variance and establish: (1) structures assumed in current reporting practice underestimate the strength of relationships between benchmarks; (2) evidence of local dependence among leaderboard items, undermining uses of benchmarks as measurement instruments under current scoring systems; (3) contributor metadata explains more rank-relevant variance ($\approx9\%$) than architecture or deployment categories in this context; (4) a manifest-score "scaling law" slope has low reliability ($R_β=0.53$); by contrast, the latent general-factor size slope is highly stable across ecosystem controls ($R_g=0.97$). We are able to provide unique insights into benchmark dynamics, such as which benchmarks are a function of LLM size and which can be oppositely impacted by post-training practices. We provide actionable diagnostics to determine how benchmark rankings can be trusted and how benchmark design can be improved.
3D Reconstruction of Interacting Multi-Person in Clothing from a Single Image
Jan 12, 2024This paper introduces a novel pipeline to reconstruct the geometry of interacting multi-person in clothing on a globally coherent scene space from a single image. The main challenge arises from the occlusion: a part of a human body is not visible from a single view due to the occlusion by others or the self, which introduces missing geometry and physical implausibility (e.g., penetration). We overcome this challenge by utilizing two human priors for complete 3D geometry and surface contacts. For the geometry prior, an encoder learns to regress the image of a person with missing body parts to the latent vectors; a decoder decodes these vectors to produce 3D features of the associated geometry; and an implicit network combines these features with a surface normal map to reconstruct a complete and detailed 3D humans. For the contact prior, we develop an image-space contact detector that outputs a probability distribution of surface contacts between people in 3D. We use these priors to globally refine the body poses, enabling the penetration-free and accurate reconstruction of interacting multi-person in clothing on the scene space. The results demonstrate that our method is complete, globally coherent, and physically plausible compared to existing methods.
Dynamic Appearance Modeling of Clothed 3D Human Avatars using a Single Camera
Dec 28, 2023The appearance of a human in clothing is driven not only by the pose but also by its temporal context, i.e., motion. However, such context has been largely neglected by existing monocular human modeling methods whose neural networks often struggle to learn a video of a person with large dynamics due to the motion ambiguity, i.e., there exist numerous geometric configurations of clothes that are dependent on the context of motion even for the same pose. In this paper, we introduce a method for high-quality modeling of clothed 3D human avatars using a video of a person with dynamic movements. The main challenge comes from the lack of 3D ground truth data of geometry and its temporal correspondences. We address this challenge by introducing a novel compositional human modeling framework that takes advantage of both explicit and implicit human modeling. For explicit modeling, a neural network learns to generate point-wise shape residuals and appearance features of a 3D body model by comparing its 2D rendering results and the original images. This explicit model allows for the reconstruction of discriminative 3D motion features from UV space by encoding their temporal correspondences. For implicit modeling, an implicit network combines the appearance and 3D motion features to decode high-fidelity clothed 3D human avatars with motion-dependent geometry and texture. The experiments show that our method can generate a large variation of secondary motion in a physically plausible way.
Is a Seat at the Table Enough? Engaging Teachers and Students in Dataset Specification for ML in Education
Nov 09, 2023

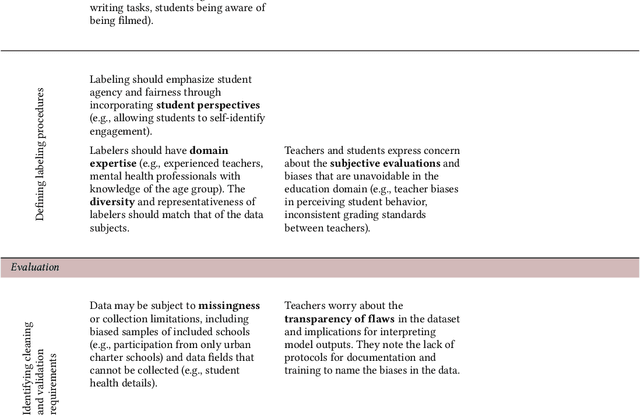

Despite the promises of ML in education, its adoption in the classroom has surfaced numerous issues regarding fairness, accountability, and transparency, as well as concerns about data privacy and student consent. A root cause of these issues is the lack of understanding of the complex dynamics of education, including teacher-student interactions, collaborative learning, and classroom environment. To overcome these challenges and fully utilize the potential of ML in education, software practitioners need to work closely with educators and students to fully understand the context of the data (the backbone of ML applications) and collaboratively define the ML data specifications. To gain a deeper understanding of such a collaborative process, we conduct ten co-design sessions with ML software practitioners, educators, and students. In the sessions, teachers and students work with ML engineers, UX designers, and legal practitioners to define dataset characteristics for a given ML application. We find that stakeholders contextualize data based on their domain and procedural knowledge, proactively design data requirements to mitigate downstream harms and data reliability concerns, and exhibit role-based collaborative strategies and contribution patterns. Further, we find that beyond a seat at the table, meaningful stakeholder participation in ML requires structured supports: defined processes for continuous iteration and co-evaluation, shared contextual data quality standards, and information scaffolds for both technical and non-technical stakeholders to traverse expertise boundaries.
IFaceUV: Intuitive Motion Facial Image Generation by Identity Preservation via UV map
Jun 08, 2023Reenacting facial images is an important task that can find numerous applications. We proposed IFaceUV, a fully differentiable pipeline that properly combines 2D and 3D information to conduct the facial reenactment task. The three-dimensional morphable face models (3DMMs) and corresponding UV maps are utilized to intuitively control facial motions and textures, respectively. Two-dimensional techniques based on 2D image warping is further required to compensate for missing components of the 3DMMs such as backgrounds, ear, hair and etc. In our pipeline, we first extract 3DMM parameters and corresponding UV maps from source and target images. Then, initial UV maps are refined by the UV map refinement network and it is rendered to the image with the motion manipulated 3DMM parameters. In parallel, we warp the source image according to the 2D flow field obtained from the 2D warping network. Rendered and warped images are combined in the final editing network to generate the final reenactment image. Additionally, we tested our model for the audio-driven facial reenactment task. Extensive qualitative and quantitative experiments illustrate the remarkable performance of our method compared to other state-of-the-art methods.
HOReeNet: 3D-aware Hand-Object Grasping Reenactment
Nov 11, 2022
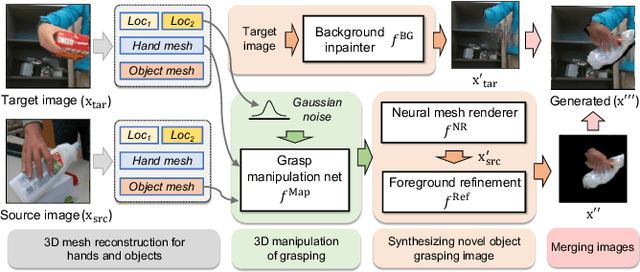

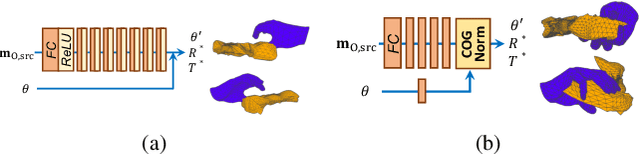
We present HOReeNet, which tackles the novel task of manipulating images involving hands, objects, and their interactions. Especially, we are interested in transferring objects of source images to target images and manipulating 3D hand postures to tightly grasp the transferred objects. Furthermore, the manipulation needs to be reflected in the 2D image space. In our reenactment scenario involving hand-object interactions, 3D reconstruction becomes essential as 3D contact reasoning between hands and objects is required to achieve a tight grasp. At the same time, to obtain high-quality 2D images from 3D space, well-designed 3D-to-2D projection and image refinement are required. Our HOReeNet is the first fully differentiable framework proposed for such a task. On hand-object interaction datasets, we compared our HOReeNet to the conventional image translation algorithms and reenactment algorithm. We demonstrated that our approach could achieved the state-of-the-art on the proposed task.
Algorithmic Fairness in Education
Jul 10, 2020
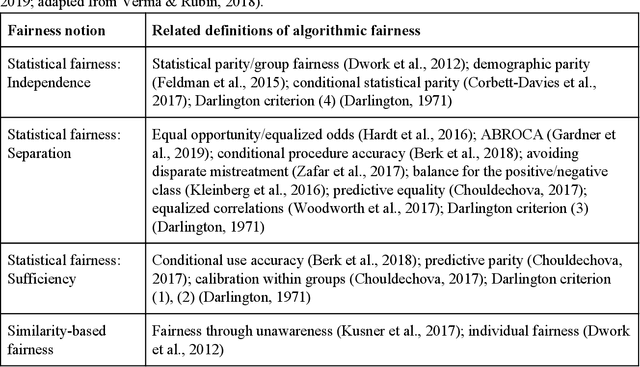
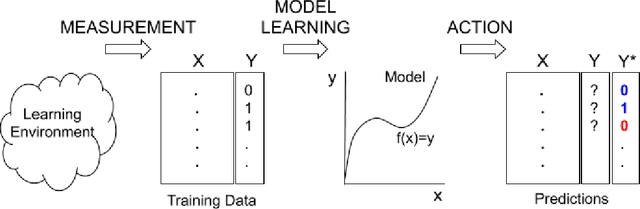
Data-driven predictive models are increasingly used in education to support students, instructors, and administrators. However, there are concerns about the fairness of the predictions and uses of these algorithmic systems. In this introduction to algorithmic fairness in education, we draw parallels to prior literature on educational access, bias, and discrimination, and we examine core components of algorithmic systems (measurement, model learning, and action) to identify sources of bias and discrimination in the process of developing and deploying these systems. Statistical, similarity-based, and causal notions of fairness are reviewed and contrasted in the way they apply in educational contexts. Recommendations for policy makers and developers of educational technology offer guidance for how to promote algorithmic fairness in education.
Evaluation of Fairness Trade-offs in Predicting Student Success
Jun 30, 2020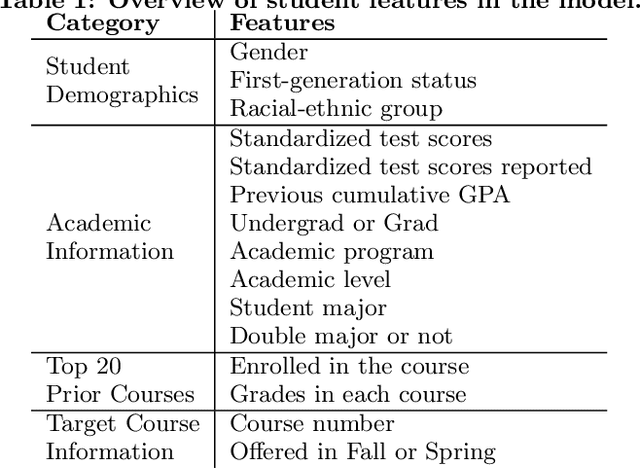
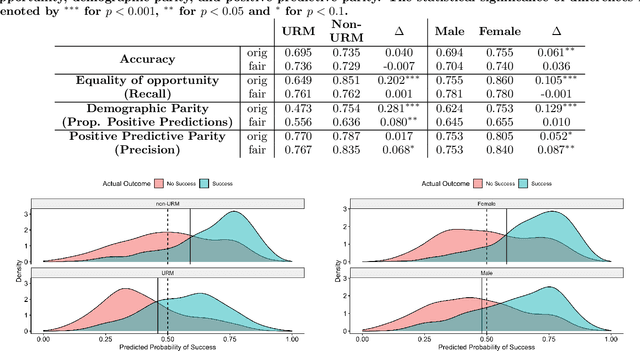
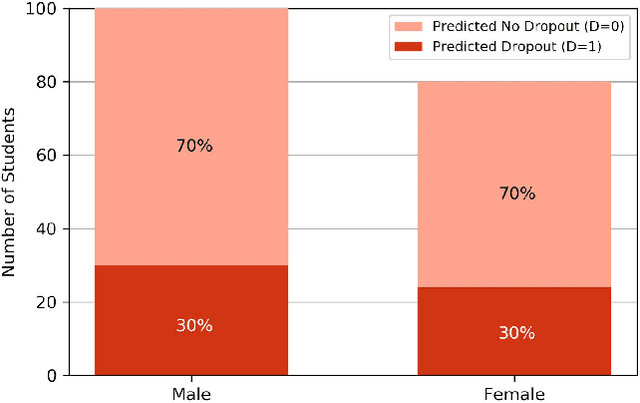
Predictive models for identifying at-risk students early can help teaching staff direct resources to better support them, but there is a growing concern about the fairness of algorithmic systems in education. Predictive models may inadvertently introduce bias in who receives support and thereby exacerbate existing inequities. We examine this issue by building a predictive model of student success based on university administrative records. We find that the model exhibits gender and racial bias in two out of three fairness measures considered. We then apply post-hoc adjustments to improve model fairness to highlight trade-offs between the three fairness measures.