 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtility-Preserving De-Identification for Math Tutoring: Investigating Numeric Ambiguity in the MathEd-PII Benchmark Dataset
Feb 18, 2026Large-scale sharing of dialogue-based data is instrumental for advancing the science of teaching and learning, yet rigorous de-identification remains a major barrier. In mathematics tutoring transcripts, numeric expressions frequently resemble structured identifiers (e.g., dates or IDs), leading generic Personally Identifiable Information (PII) detection systems to over-redact core instructional content and reduce dataset utility. This work asks how PII can be detected in math tutoring transcripts while preserving their educational utility. To address this challenge, we investigate the "numeric ambiguity" problem and introduce MathEd-PII, the first benchmark dataset for PII detection in math tutoring dialogues, created through a human-in-the-loop LLM workflow that audits upstream redactions and generates privacy-preserving surrogates. The dataset contains 1,000 tutoring sessions (115,620 messages; 769,628 tokens) with validated PII annotations. Using a density-based segmentation method, we show that false PII redactions are disproportionately concentrated in math-dense regions, confirming numeric ambiguity as a key failure mode. We then compare four detection strategies: a Presidio baseline and LLM-based approaches with basic, math-aware, and segment-aware prompting. Math-aware prompting substantially improves performance over the baseline (F1: 0.821 vs. 0.379) while reducing numeric false positives, demonstrating that de-identification must incorporate domain context to preserve analytic utility. This work provides both a new benchmark and evidence that utility-preserving de-identification for tutoring data requires domain-aware modeling.
Discursive objection strategies in online comments: Developing a classification schema and validating its training
May 13, 2024



Most Americans agree that misinformation, hate speech and harassment are harmful and inadequately curbed on social media through current moderation practices. In this paper, we aim to understand the discursive strategies employed by people in response to harmful speech in news comments. We conducted a content analysis of more than 6500 comment replies to trending news videos on YouTube and Twitter and identified seven distinct discursive objection strategies (Study 1). We examined the frequency of each strategy's occurrence from the 6500 comment replies, as well as from a second sample of 2004 replies (Study 2). Together, these studies show that people deploy a diversity of discursive strategies when objecting to speech, and reputational attacks are the most common. The resulting classification scheme accounts for different theoretical approaches for expressing objections and offers a comprehensive perspective on grassroots efforts aimed at stopping offensive or problematic speech on campus.
Algorithmic Fairness in Education
Jul 10, 2020
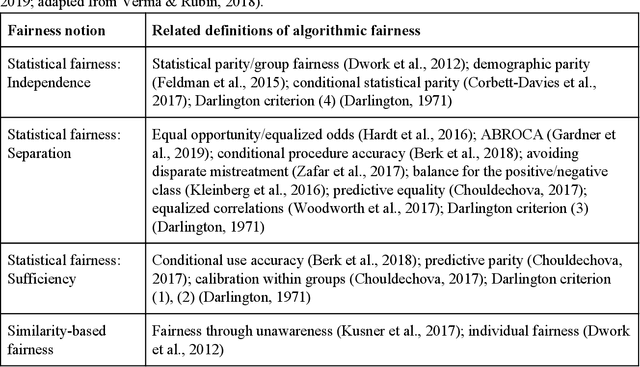
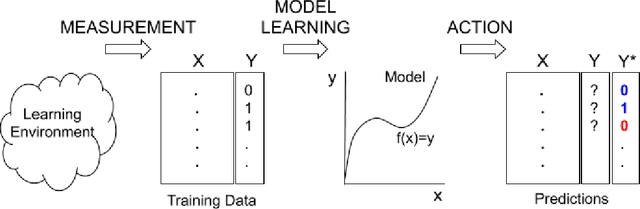
Data-driven predictive models are increasingly used in education to support students, instructors, and administrators. However, there are concerns about the fairness of the predictions and uses of these algorithmic systems. In this introduction to algorithmic fairness in education, we draw parallels to prior literature on educational access, bias, and discrimination, and we examine core components of algorithmic systems (measurement, model learning, and action) to identify sources of bias and discrimination in the process of developing and deploying these systems. Statistical, similarity-based, and causal notions of fairness are reviewed and contrasted in the way they apply in educational contexts. Recommendations for policy makers and developers of educational technology offer guidance for how to promote algorithmic fairness in education.
Evaluation of Fairness Trade-offs in Predicting Student Success
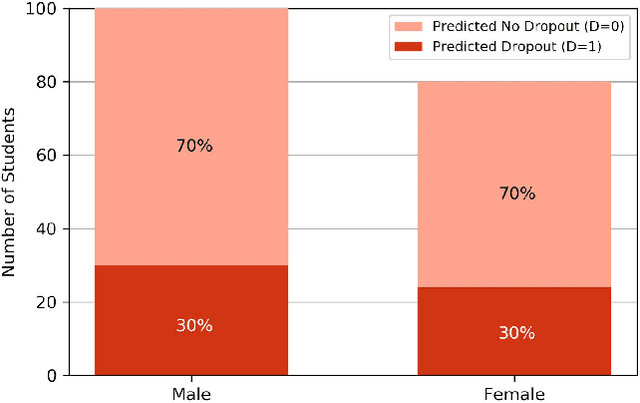
Jun 30, 2020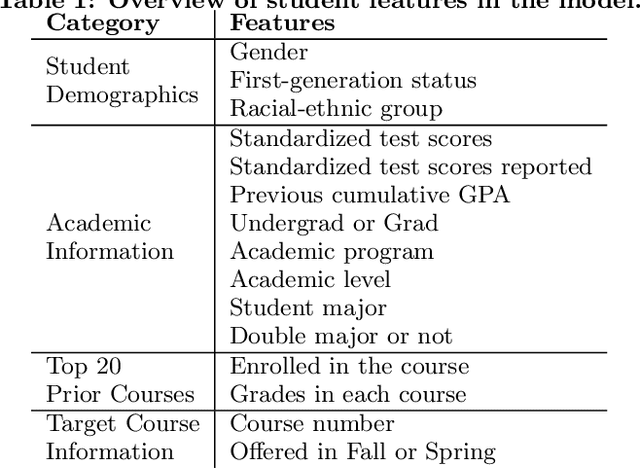
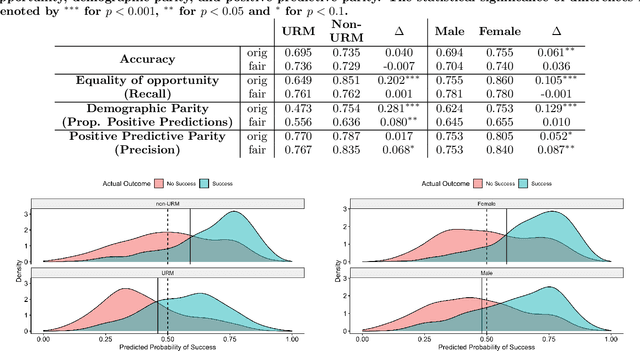
Predictive models for identifying at-risk students early can help teaching staff direct resources to better support them, but there is a growing concern about the fairness of algorithmic systems in education. Predictive models may inadvertently introduce bias in who receives support and thereby exacerbate existing inequities. We examine this issue by building a predictive model of student success based on university administrative records. We find that the model exhibits gender and racial bias in two out of three fairness measures considered. We then apply post-hoc adjustments to improve model fairness to highlight trade-offs between the three fairness measures.