 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs a Seat at the Table Enough? Engaging Teachers and Students in Dataset Specification for ML in Education
Nov 09, 2023Despite the promises of ML in education, its adoption in the classroom has surfaced numerous issues regarding fairness, accountability, and transparency, as well as concerns about data privacy and student consent. A root cause of these issues is the lack of understanding of the complex dynamics of education, including teacher-student interactions, collaborative learning, and classroom environment. To overcome these challenges and fully utilize the potential of ML in education, software practitioners need to work closely with educators and students to fully understand the context of the data (the backbone of ML applications) and collaboratively define the ML data specifications. To gain a deeper understanding of such a collaborative process, we conduct ten co-design sessions with ML software practitioners, educators, and students. In the sessions, teachers and students work with ML engineers, UX designers, and legal practitioners to define dataset characteristics for a given ML application. We find that stakeholders contextualize data based on their domain and procedural knowledge, proactively design data requirements to mitigate downstream harms and data reliability concerns, and exhibit role-based collaborative strategies and contribution patterns. Further, we find that beyond a seat at the table, meaningful stakeholder participation in ML requires structured supports: defined processes for continuous iteration and co-evaluation, shared contextual data quality standards, and information scaffolds for both technical and non-technical stakeholders to traverse expertise boundaries.
Are We Closing the Loop Yet? Gaps in the Generalizability of VIS4ML Research
Aug 10, 2023Visualization for machine learning (VIS4ML) research aims to help experts apply their prior knowledge to develop, understand, and improve the performance of machine learning models. In conceiving VIS4ML systems, researchers characterize the nature of human knowledge to support human-in-the-loop tasks, design interactive visualizations to make ML components interpretable and elicit knowledge, and evaluate the effectiveness of human-model interchange. We survey recent VIS4ML papers to assess the generalizability of research contributions and claims in enabling human-in-the-loop ML. Our results show potential gaps between the current scope of VIS4ML research and aspirations for its use in practice. We find that while papers motivate that VIS4ML systems are applicable beyond the specific conditions studied, conclusions are often overfitted to non-representative scenarios, are based on interactions with a small set of ML experts and well-understood datasets, fail to acknowledge crucial dependencies, and hinge on decisions that lack justification. We discuss approaches to close the gap between aspirations and research claims and suggest documentation practices to report generality constraints that better acknowledge the exploratory nature of VIS4ML research.
Spellburst: A Node-based Interface for Exploratory Creative Coding with Natural Language Prompts
Aug 07, 2023Creative coding tasks are often exploratory in nature. When producing digital artwork, artists usually begin with a high-level semantic construct such as a "stained glass filter" and programmatically implement it by varying code parameters such as shape, color, lines, and opacity to produce visually appealing results. Based on interviews with artists, it can be effortful to translate semantic constructs to program syntax, and current programming tools don't lend well to rapid creative exploration. To address these challenges, we introduce Spellburst, a large language model (LLM) powered creative-coding environment. Spellburst provides (1) a node-based interface that allows artists to create generative art and explore variations through branching and merging operations, (2) expressive prompt-based interactions to engage in semantic programming, and (3) dynamic prompt-driven interfaces and direct code editing to seamlessly switch between semantic and syntactic exploration. Our evaluation with artists demonstrates Spellburst's potential to enhance creative coding practices and inform the design of computational creativity tools that bridge semantic and syntactic spaces.
fAIlureNotes: Supporting Designers in Understanding the Limits of AI Models for Computer Vision Tasks
Feb 22, 2023To design with AI models, user experience (UX) designers must assess the fit between the model and user needs. Based on user research, they need to contextualize the model's behavior and potential failures within their product-specific data instances and user scenarios. However, our formative interviews with ten UX professionals revealed that such a proactive discovery of model limitations is challenging and time-intensive. Furthermore, designers often lack technical knowledge of AI and accessible exploration tools, which challenges their understanding of model capabilities and limitations. In this work, we introduced a failure-driven design approach to AI, a workflow that encourages designers to explore model behavior and failure patterns early in the design process. The implementation of fAIlureNotes, a designer-centered failure exploration and analysis tool, supports designers in evaluating models and identifying failures across diverse user groups and scenarios. Our evaluation with UX practitioners shows that fAIlureNotes outperforms today's interactive model cards in assessing context-specific model performance.
Designerly Understanding: Information Needs for Model Transparency to Support Design Ideation for AI-Powered User Experience
Feb 21, 2023

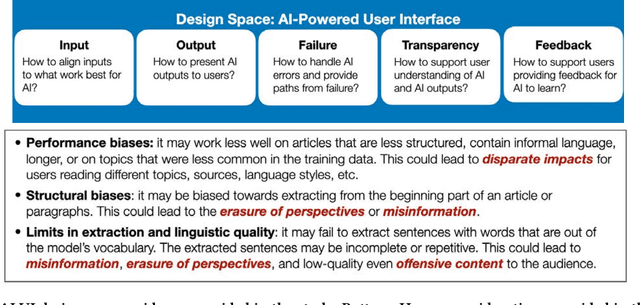

Despite the widespread use of artificial intelligence (AI), designing user experiences (UX) for AI-powered systems remains challenging. UX designers face hurdles understanding AI technologies, such as pre-trained language models, as design materials. This limits their ability to ideate and make decisions about whether, where, and how to use AI. To address this problem, we bridge the literature on AI design and AI transparency to explore whether and how frameworks for transparent model reporting can support design ideation with pre-trained models. By interviewing 23 UX practitioners, we find that practitioners frequently work with pre-trained models, but lack support for UX-led ideation. Through a scenario-based design task, we identify common goals that designers seek model understanding for and pinpoint their model transparency information needs. Our study highlights the pivotal role that UX designers can play in Responsible AI and calls for supporting their understanding of AI limitations through model transparency and interrogation.
Assessing the Fairness of AI Systems: AI Practitioners' Processes, Challenges, and Needs for Support
Dec 10, 2021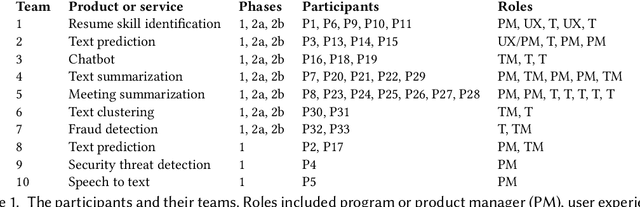
Various tools and practices have been developed to support practitioners in identifying, assessing, and mitigating fairness-related harms caused by AI systems. However, prior research has highlighted gaps between the intended design of these tools and practices and their use within particular contexts, including gaps caused by the role that organizational factors play in shaping fairness work. In this paper, we investigate these gaps for one such practice: disaggregated evaluations of AI systems, intended to uncover performance disparities between demographic groups. By conducting semi-structured interviews and structured workshops with thirty-three AI practitioners from ten teams at three technology companies, we identify practitioners' processes, challenges, and needs for support when designing disaggregated evaluations. We find that practitioners face challenges when choosing performance metrics, identifying the most relevant direct stakeholders and demographic groups on which to focus, and collecting datasets with which to conduct disaggregated evaluations. More generally, we identify impacts on fairness work stemming from a lack of engagement with direct stakeholders, business imperatives that prioritize customers over marginalized groups, and the drive to deploy AI systems at scale.
Towards A Process Model for Co-Creating AI Experiences
May 06, 2021
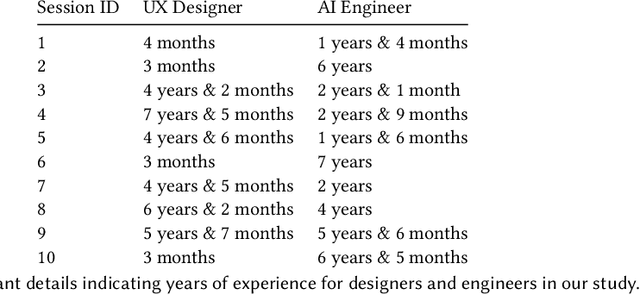


Thinking of technology as a design material is appealing. It encourages designers to explore the material's properties to understand its capabilities and limitations, a prerequisite to generative design thinking. However, as a material, AI resists this approach because its properties emerge as part of the design process itself. Therefore, designers and AI engineers must collaborate in new ways to create both the material and its application experience. We investigate the co-creation process through a design study with 10 pairs of designers and engineers. We find that design 'probes' with user data are a useful tool in defining AI materials. Through data probes, designers construct designerly representations of the envisioned AI experience (AIX) to identify desirable AI characteristics. Data probes facilitate divergent thinking, material testing, and design validation. Based on our findings, we propose a process model for co-creating AIX and offer design considerations for incorporating data probes in design tools.