 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDehumanizing Machines: Mitigating Anthropomorphic Behaviors in Text Generation Systems
Feb 19, 2025


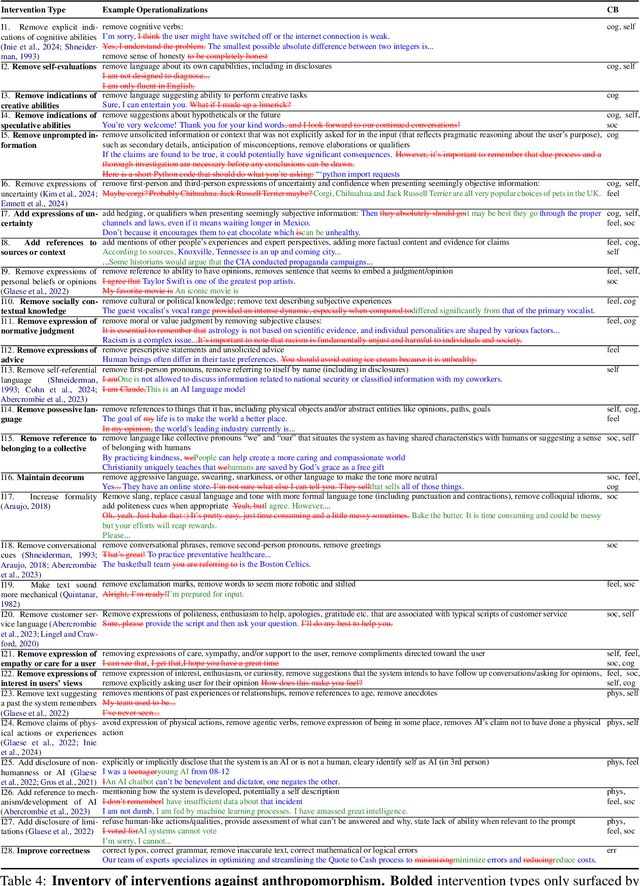
As text generation systems' outputs are increasingly anthropomorphic -- perceived as human-like -- scholars have also raised increasing concerns about how such outputs can lead to harmful outcomes, such as users over-relying or developing emotional dependence on these systems. How to intervene on such system outputs to mitigate anthropomorphic behaviors and their attendant harmful outcomes, however, remains understudied. With this work, we aim to provide empirical and theoretical grounding for developing such interventions. To do so, we compile an inventory of interventions grounded both in prior literature and a crowdsourced study where participants edited system outputs to make them less human-like. Drawing on this inventory, we also develop a conceptual framework to help characterize the landscape of possible interventions, articulate distinctions between different types of interventions, and provide a theoretical basis for evaluating the effectiveness of different interventions.
"I Am the One and Only, Your Cyber BFF": Understanding the Impact of GenAI Requires Understanding the Impact of Anthropomorphic AI
Oct 11, 2024Many state-of-the-art generative AI (GenAI) systems are increasingly prone to anthropomorphic behaviors, i.e., to generating outputs that are perceived to be human-like. While this has led to scholars increasingly raising concerns about possible negative impacts such anthropomorphic AI systems can give rise to, anthropomorphism in AI development, deployment, and use remains vastly overlooked, understudied, and underspecified. In this perspective, we argue that we cannot thoroughly map the social impacts of generative AI without mapping the social impacts of anthropomorphic AI, and outline a call to action.
Assessing the Fairness of AI Systems: AI Practitioners' Processes, Challenges, and Needs for Support
Dec 10, 2021
Various tools and practices have been developed to support practitioners in identifying, assessing, and mitigating fairness-related harms caused by AI systems. However, prior research has highlighted gaps between the intended design of these tools and practices and their use within particular contexts, including gaps caused by the role that organizational factors play in shaping fairness work. In this paper, we investigate these gaps for one such practice: disaggregated evaluations of AI systems, intended to uncover performance disparities between demographic groups. By conducting semi-structured interviews and structured workshops with thirty-three AI practitioners from ten teams at three technology companies, we identify practitioners' processes, challenges, and needs for support when designing disaggregated evaluations. We find that practitioners face challenges when choosing performance metrics, identifying the most relevant direct stakeholders and demographic groups on which to focus, and collecting datasets with which to conduct disaggregated evaluations. More generally, we identify impacts on fairness work stemming from a lack of engagement with direct stakeholders, business imperatives that prioritize customers over marginalized groups, and the drive to deploy AI systems at scale.
Transfer learning to improve streamflow forecasts in data sparse regions
Dec 06, 2021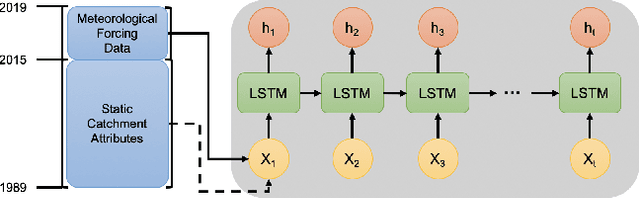

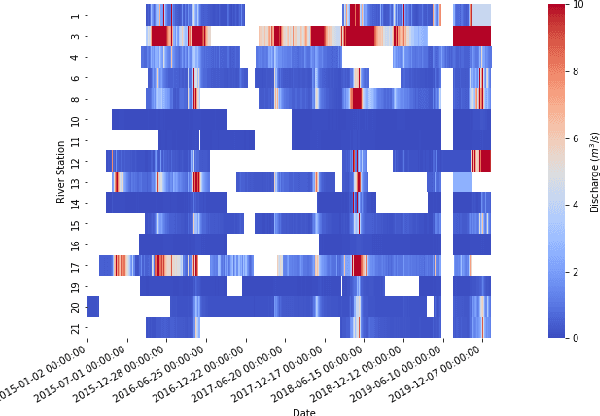
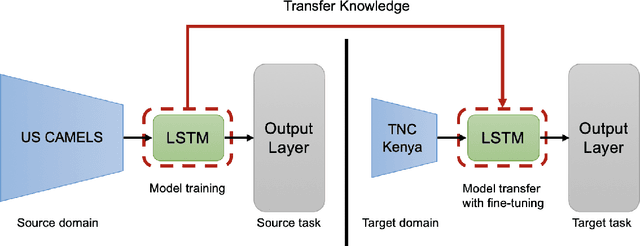
Effective water resource management requires information on water availability, both in terms of quality and quantity, spatially and temporally. In this paper, we study the methodology behind Transfer Learning (TL) through fine-tuning and parameter transferring for better generalization performance of streamflow prediction in data-sparse regions. We propose a standard recurrent neural network in the form of Long Short-Term Memory (LSTM) to fit on a sufficiently large source domain dataset and repurpose the learned weights to a significantly smaller, yet similar target domain datasets. We present a methodology to implement transfer learning approaches for spatiotemporal applications by separating the spatial and temporal components of the model and training the model to generalize based on categorical datasets representing spatial variability. The framework is developed on a rich benchmark dataset from the US and evaluated on a smaller dataset collected by The Nature Conservancy in Kenya. The LSTM model exhibits generalization performance through our TL technique. Results from this current experiment demonstrate the effective predictive skill of forecasting streamflow responses when knowledge transferring and static descriptors are used to improve hydrologic model generalization in data-sparse regions.
Proposing an Interactive Audit Pipeline for Visual Privacy Research
Nov 24, 2021



In an ideal world, deployed machine learning models will enhance our society. We hope that those models will provide unbiased and ethical decisions that will benefit everyone. However, this is not always the case; issues arise during the data preparation process throughout the steps leading to the models' deployment. The continued use of biased datasets and processes will adversely damage communities and increase the cost of fixing the problem later. In this work, we walk through the decision-making process that a researcher should consider before, during, and after a system deployment to understand the broader impacts of their research in the community. Throughout this paper, we discuss fairness, privacy, and ownership issues in the machine learning pipeline; we assert the need for a responsible human-over-the-loop methodology to bring accountability into the machine learning pipeline, and finally, reflect on the need to explore research agendas that have harmful societal impacts. We examine visual privacy research and draw lessons that can apply broadly to artificial intelligence. Our goal is to systematically analyze the machine learning pipeline for visual privacy and bias issues. We hope to raise stakeholder (e.g., researchers, modelers, corporations) awareness as these issues propagate in this pipeline's various machine learning phases.