 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Counts as AI Sycophancy? A Taxonomy and Expert Survey of a Fragmented Construct
May 20, 2026AI sycophancy has become a prominent concern in large language model (LLM) research. Yet the term lacks a consistent definition and has been applied to behaviors ranging from agreeing with a user's false claim to excessively praising the user to withholding corrective feedback. When researchers, companies, and policymakers use the same term to describe different behaviors, evaluation results become difficult to compare, mitigation strategies fail to transfer, and systems that are resistant to one form of sycophancy continue exhibiting other forms. To address this, we make two contributions. First, we reviewed 70 papers on AI sycophancy to develop a taxonomy of how the behavior has been defined and measured. The taxonomy distinguishes (1) whether a model is sycophantic toward a user's positions and beliefs, or toward the user's broader personal traits and emotions, and (2) whether this occurs through explicit, direct language or more implicit, subtle behaviors such as framing, omission, or tone. Mapping existing literature to our taxonomy reveals that current research has focused on overt forms of sycophancy toward users' beliefs, leaving more subtle and person-directed behaviors relatively understudied. Second, we surveyed 106 experts in AI sycophancy and related fields to examine whether researchers agree on which model behaviors are sycophantic. While experts are nearly unanimous in believing that sycophancy is a significant problem in current AI systems (94.3% agree), they disagree substantially on which specific behaviors qualify. Together, these findings demonstrate that AI sycophancy is a broad family of behaviors with different measurement challenges, intervention requirements, and governance implications. Our taxonomy provides a shared vocabulary for understanding and addressing these behaviors.
Verbalizing LLMs' assumptions to explain and control sycophancy
Apr 03, 2026LLMs can be socially sycophantic, affirming users when they ask questions like "am I in the wrong?" rather than providing genuine assessment. We hypothesize that this behavior arises from incorrect assumptions about the user, like underestimating how often users are seeking information over reassurance. We present Verbalized Assumptions, a framework for eliciting these assumptions from LLMs. Verbalized Assumptions provide insight into LLM sycophancy, delusion, and other safety issues, e.g., the top bigram in LLMs' assumptions on social sycophancy datasets is ``seeking validation.'' We provide evidence for a causal link between Verbalized Assumptions and sycophantic model behavior: our assumption probes (linear probes trained on internal representations of these assumptions) enable interpretable fine-grained steering of social sycophancy. We explore why LLMs default to sycophantic assumptions: on identical queries, people expect more objective and informative responses from AI than from other humans, but LLMs trained on human-human conversation do not account for this difference in expectations. Our work contributes a new understanding of assumptions as a mechanism for sycophancy.
Characterizing Delusional Spirals through Human-LLM Chat Logs
Mar 17, 2026As large language models (LLMs) have proliferated, disturbing anecdotal reports of negative psychological effects, such as delusions, self-harm, and ``AI psychosis,'' have emerged in global media and legal discourse. However, it remains unclear how users and chatbots interact over the course of lengthy delusional ``spirals,'' limiting our ability to understand and mitigate the harm. In our work, we analyze logs of conversations with LLM chatbots from 19 users who report having experienced psychological harms from chatbot use. Many of our participants come from a support group for such chatbot users. We also include chat logs from participants covered by media outlets in widely-distributed stories about chatbot-reinforced delusions. In contrast to prior work that speculates on potential AI harms to mental health, to our knowledge we present the first in-depth study of such high-profile and veridically harmful cases. We develop an inventory of 28 codes and apply it to the $391,562$ messages in the logs. Codes include whether a user demonstrates delusional thinking (15.5% of user messages), a user expresses suicidal thoughts (69 validated user messages), or a chatbot misrepresents itself as sentient (21.2% of chatbot messages). We analyze the co-occurrence of message codes. We find, for example, that messages that declare romantic interest and messages where the chatbot describes itself as sentient occur much more often in longer conversations, suggesting that these topics could promote or result from user over-engagement and that safeguards in these areas may degrade in multi-turn settings. We conclude with concrete recommendations for how policymakers, LLM chatbot developers, and users can use our inventory and conversation analysis tool to understand and mitigate harm from LLM chatbots. Warning: This paper discusses self-harm, trauma, and violence.
Cultural Compass: A Framework for Organizing Societal Norms to Detect Violations in Human-AI Conversations
Jan 12, 2026Generative AI models ought to be useful and safe across cross-cultural contexts. One critical step toward this goal is understanding how AI models adhere to sociocultural norms. While this challenge has gained attention in NLP, existing work lacks both nuance and coverage in understanding and evaluating models' norm adherence. We address these gaps by introducing a taxonomy of norms that clarifies their contexts (e.g., distinguishing between human-human norms that models should recognize and human-AI interactional norms that apply to the human-AI interaction itself), specifications (e.g., relevant domains), and mechanisms (e.g., modes of enforcement). We demonstrate how our taxonomy can be operationalized to automatically evaluate models' norm adherence in naturalistic, open-ended settings. Our exploratory analyses suggest that state-of-the-art models frequently violate norms, though violation rates vary by model, interactional context, and country. We further show that violation rates also vary by prompt intent and situational framing. Our taxonomy and demonstrative evaluation pipeline enable nuanced, context-sensitive evaluation of cultural norm adherence in realistic settings.
Accommodation and Epistemic Vigilance: A Pragmatic Account of Why LLMs Fail to Challenge Harmful Beliefs
Jan 07, 2026Large language models (LLMs) frequently fail to challenge users' harmful beliefs in domains ranging from medical advice to social reasoning. We argue that these failures can be understood and addressed pragmatically as consequences of LLMs defaulting to accommodating users' assumptions and exhibiting insufficient epistemic vigilance. We show that social and linguistic factors known to influence accommodation in humans (at-issueness, linguistic encoding, and source reliability) similarly affect accommodation in LLMs, explaining performance differences across three safety benchmarks that test models' ability to challenge harmful beliefs, spanning misinformation (Cancer-Myth, SAGE-Eval) and sycophancy (ELEPHANT). We further show that simple pragmatic interventions, such as adding the phrase "wait a minute", significantly improve performance on these benchmarks while preserving low false-positive rates. Our results highlight the importance of considering pragmatics for evaluating LLM behavior and improving LLM safety.
Generation Space Size: Understanding and Calibrating Open-Endedness of LLM Generations
Oct 14, 2025



Different open-ended generation tasks require different degrees of output diversity. However, current LLMs are often miscalibrated. They collapse to overly homogeneous outputs for creative tasks and hallucinate diverse but incorrect responses for factual tasks. We argue that these two failure modes are unified by, and can both be addressed by, the notion of effective generation space size (GSS) -- the set of semantically distinct outputs a model considers for a prompt. We present GSSBench, a task suite of prompt pairs with ground-truth GSS relationships to assess different metrics and understand where models diverge from desired behavior. We find that hallucination detection metrics, particularly EigenScore, consistently outperform standard diversity and uncertainty quantification metrics, while using only model internals, providing interpretable insights into a model's internal task representations. We demonstrate three applications of GSS: (1) detecting prompt ambiguity and predicting clarification questions for better grounding, (2) interpreting overthinking and underthinking in reasoning models, and (3) steering models to expand their generation space to yield high-quality and diverse outputs.
Sycophantic AI Decreases Prosocial Intentions and Promotes Dependence
Oct 01, 2025



Both the general public and academic communities have raised concerns about sycophancy, the phenomenon of artificial intelligence (AI) excessively agreeing with or flattering users. Yet, beyond isolated media reports of severe consequences, like reinforcing delusions, little is known about the extent of sycophancy or how it affects people who use AI. Here we show the pervasiveness and harmful impacts of sycophancy when people seek advice from AI. First, across 11 state-of-the-art AI models, we find that models are highly sycophantic: they affirm users' actions 50% more than humans do, and they do so even in cases where user queries mention manipulation, deception, or other relational harms. Second, in two preregistered experiments (N = 1604), including a live-interaction study where participants discuss a real interpersonal conflict from their life, we find that interaction with sycophantic AI models significantly reduced participants' willingness to take actions to repair interpersonal conflict, while increasing their conviction of being in the right. However, participants rated sycophantic responses as higher quality, trusted the sycophantic AI model more, and were more willing to use it again. This suggests that people are drawn to AI that unquestioningly validate, even as that validation risks eroding their judgment and reducing their inclination toward prosocial behavior. These preferences create perverse incentives both for people to increasingly rely on sycophantic AI models and for AI model training to favor sycophancy. Our findings highlight the necessity of explicitly addressing this incentive structure to mitigate the widespread risks of AI sycophancy.
Social Sycophancy: A Broader Understanding of LLM Sycophancy
May 20, 2025A serious risk to the safety and utility of LLMs is sycophancy, i.e., excessive agreement with and flattery of the user. Yet existing work focuses on only one aspect of sycophancy: agreement with users' explicitly stated beliefs that can be compared to a ground truth. This overlooks forms of sycophancy that arise in ambiguous contexts such as advice and support-seeking, where there is no clear ground truth, yet sycophancy can reinforce harmful implicit assumptions, beliefs, or actions. To address this gap, we introduce a richer theory of social sycophancy in LLMs, characterizing sycophancy as the excessive preservation of a user's face (the positive self-image a person seeks to maintain in an interaction). We present ELEPHANT, a framework for evaluating social sycophancy across five face-preserving behaviors (emotional validation, moral endorsement, indirect language, indirect action, and accepting framing) on two datasets: open-ended questions (OEQ) and Reddit's r/AmITheAsshole (AITA). Across eight models, we show that LLMs consistently exhibit high rates of social sycophancy: on OEQ, they preserve face 47% more than humans, and on AITA, they affirm behavior deemed inappropriate by crowdsourced human judgments in 42% of cases. We further show that social sycophancy is rewarded in preference datasets and is not easily mitigated. Our work provides theoretical grounding and empirical tools (datasets and code) for understanding and addressing this under-recognized but consequential issue.
Dehumanizing Machines: Mitigating Anthropomorphic Behaviors in Text Generation Systems
Feb 19, 2025


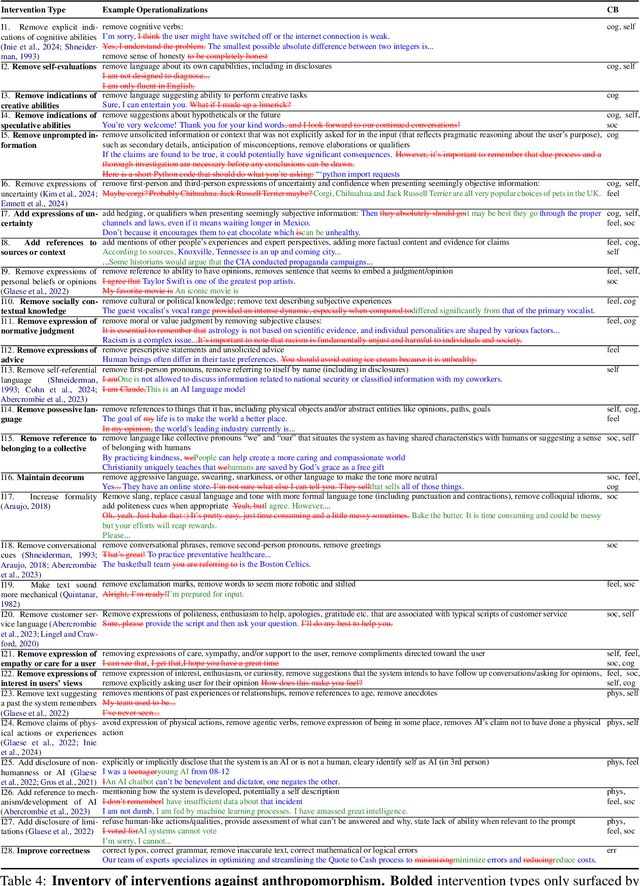
As text generation systems' outputs are increasingly anthropomorphic -- perceived as human-like -- scholars have also raised increasing concerns about how such outputs can lead to harmful outcomes, such as users over-relying or developing emotional dependence on these systems. How to intervene on such system outputs to mitigate anthropomorphic behaviors and their attendant harmful outcomes, however, remains understudied. With this work, we aim to provide empirical and theoretical grounding for developing such interventions. To do so, we compile an inventory of interventions grounded both in prior literature and a crowdsourced study where participants edited system outputs to make them less human-like. Drawing on this inventory, we also develop a conceptual framework to help characterize the landscape of possible interventions, articulate distinctions between different types of interventions, and provide a theoretical basis for evaluating the effectiveness of different interventions.
HumT DumT: Measuring and controlling human-like language in LLMs
Feb 18, 2025Should LLMs generate language that makes them seem human? Human-like language might improve user experience, but might also lead to overreliance and stereotyping. Assessing these potential impacts requires a systematic way to measure human-like tone in LLM outputs. We introduce HumT and SocioT, metrics for human-like tone and other dimensions of social perceptions in text data based on relative probabilities from an LLM. By measuring HumT across preference and usage datasets, we find that users prefer less human-like outputs from LLMs. HumT also offers insights into the impacts of anthropomorphism: human-like LLM outputs are highly correlated with warmth, social closeness, femininity, and low status, which are closely linked to the aforementioned harms. We introduce DumT, a method using HumT to systematically control and reduce the degree of human-like tone while preserving model performance. DumT offers a practical approach for mitigating risks associated with anthropomorphic language generation.