 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom tools to thieves: Measuring and understanding public perceptions of AI through crowdsourced metaphors
Jan 29, 2025
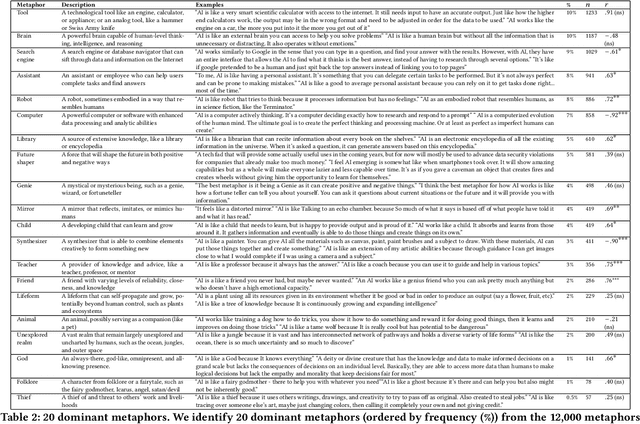
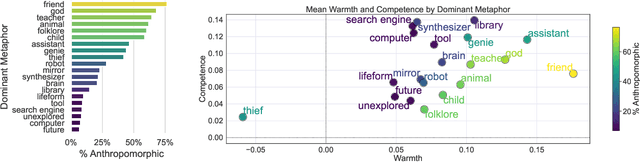
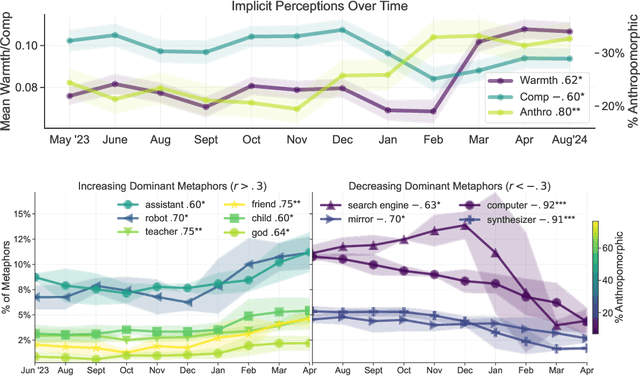
How has the public responded to the increasing prevalence of artificial intelligence (AI)-based technologies? We investigate public perceptions of AI by collecting over 12,000 responses over 12 months from a nationally representative U.S. sample. Participants provided open-ended metaphors reflecting their mental models of AI, a methodology that overcomes the limitations of traditional self-reported measures. Using a mixed-methods approach combining quantitative clustering and qualitative coding, we identify 20 dominant metaphors shaping public understanding of AI. To analyze these metaphors systematically, we present a scalable framework integrating language modeling (LM)-based techniques to measure key dimensions of public perception: anthropomorphism (attribution of human-like qualities), warmth, and competence. We find that Americans generally view AI as warm and competent, and that over the past year, perceptions of AI's human-likeness and warmth have significantly increased ($+34\%, r = 0.80, p < 0.01; +41\%, r = 0.62, p < 0.05$). Furthermore, these implicit perceptions, along with the identified dominant metaphors, strongly predict trust in and willingness to adopt AI ($r^2 = 0.21, 0.18, p < 0.001$). We further explore how differences in metaphors and implicit perceptions--such as the higher propensity of women, older individuals, and people of color to anthropomorphize AI--shed light on demographic disparities in trust and adoption. In addition to our dataset and framework for tracking evolving public attitudes, we provide actionable insights on using metaphors for inclusive and responsible AI development.
Advancing an Interdisciplinary Science of Conversation: Insights from a Large Multimodal Corpus of Human Speech
Mar 01, 2022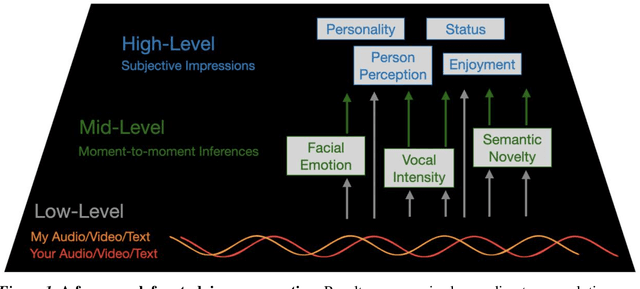
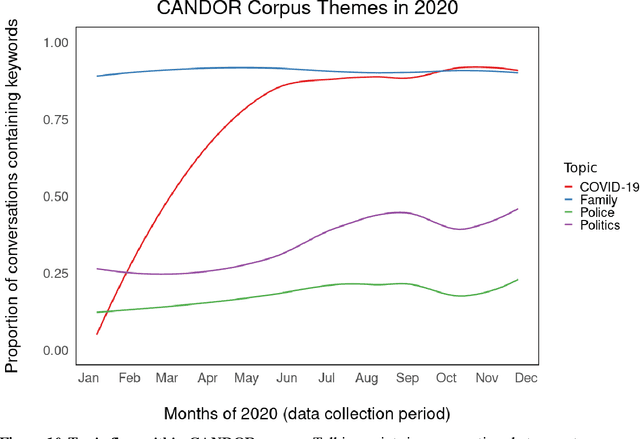

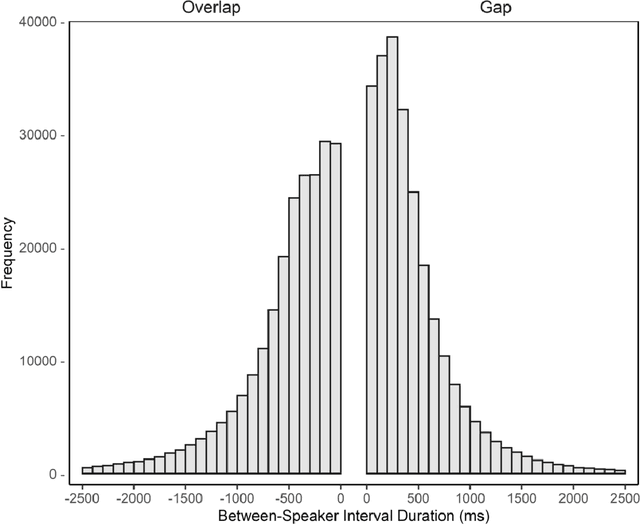
People spend a substantial portion of their lives engaged in conversation, and yet our scientific understanding of conversation is still in its infancy. In this report we advance an interdisciplinary science of conversation, with findings from a large, novel, multimodal corpus of 1,656 recorded conversations in spoken English. This 7+ million word, 850 hour corpus totals over 1TB of audio, video, and transcripts, with moment-to-moment measures of vocal, facial, and semantic expression, along with an extensive survey of speaker post conversation reflections. We leverage the considerable scope of the corpus to (1) extend key findings from the literature, such as the cooperativeness of human turn-taking; (2) define novel algorithmic procedures for the segmentation of speech into conversational turns; (3) apply machine learning insights across various textual, auditory, and visual features to analyze what makes conversations succeed or fail; and (4) explore how conversations are related to well-being across the lifespan. We also report (5) a comprehensive mixed-method report, based on quantitative analysis and qualitative review of each recording, that showcases how individuals from diverse backgrounds alter their communication patterns and find ways to connect. We conclude with a discussion of how this large-scale public dataset may offer new directions for future research, especially across disciplinary boundaries, as scholars from a variety of fields appear increasingly interested in the study of conversation.