 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing an Interdisciplinary Science of Conversation: Insights from a Large Multimodal Corpus of Human Speech
Mar 01, 2022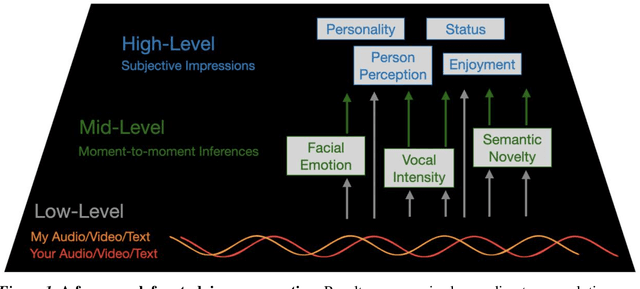
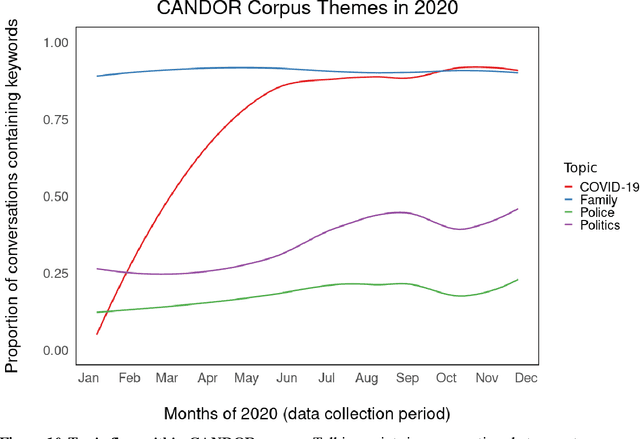

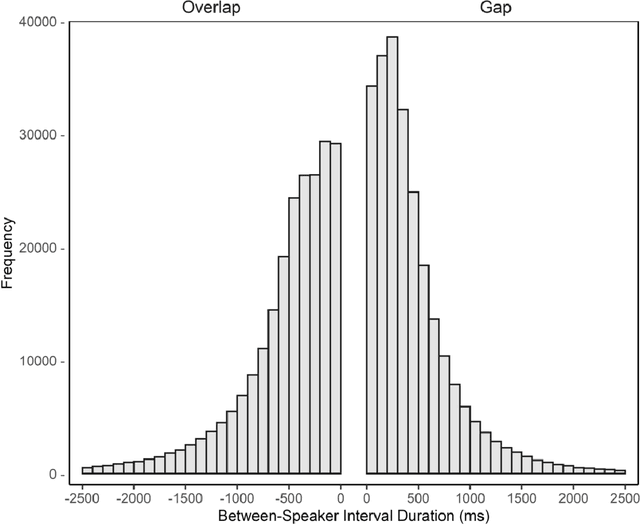
People spend a substantial portion of their lives engaged in conversation, and yet our scientific understanding of conversation is still in its infancy. In this report we advance an interdisciplinary science of conversation, with findings from a large, novel, multimodal corpus of 1,656 recorded conversations in spoken English. This 7+ million word, 850 hour corpus totals over 1TB of audio, video, and transcripts, with moment-to-moment measures of vocal, facial, and semantic expression, along with an extensive survey of speaker post conversation reflections. We leverage the considerable scope of the corpus to (1) extend key findings from the literature, such as the cooperativeness of human turn-taking; (2) define novel algorithmic procedures for the segmentation of speech into conversational turns; (3) apply machine learning insights across various textual, auditory, and visual features to analyze what makes conversations succeed or fail; and (4) explore how conversations are related to well-being across the lifespan. We also report (5) a comprehensive mixed-method report, based on quantitative analysis and qualitative review of each recording, that showcases how individuals from diverse backgrounds alter their communication patterns and find ways to connect. We conclude with a discussion of how this large-scale public dataset may offer new directions for future research, especially across disciplinary boundaries, as scholars from a variety of fields appear increasingly interested in the study of conversation.
Analysis of the first Genetic Engineering Attribution Challenge
Oct 14, 2021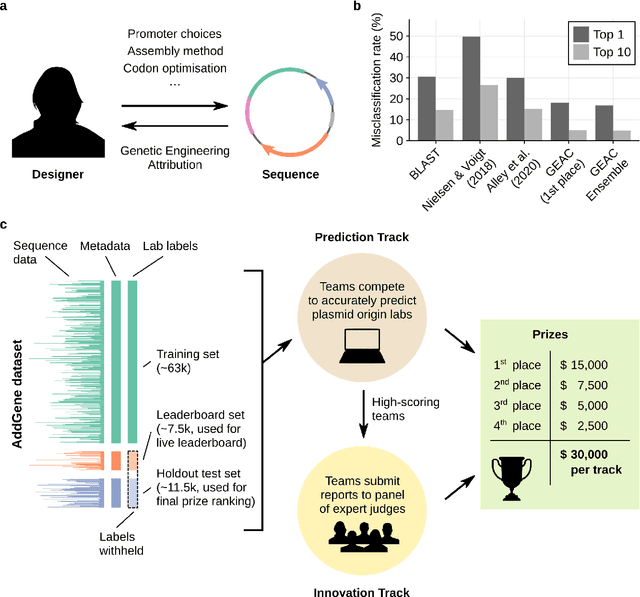



The ability to identify the designer of engineered biological sequences -- termed genetic engineering attribution (GEA) -- would help ensure due credit for biotechnological innovation, while holding designers accountable to the communities they affect. Here, we present the results of the first Genetic Engineering Attribution Challenge, a public data-science competition to advance GEA. Top-scoring teams dramatically outperformed previous models at identifying the true lab-of-origin of engineered sequences, including an increase in top-1 and top-10 accuracy of 10 percentage points. A simple ensemble of prizewinning models further increased performance. New metrics, designed to assess a model's ability to confidently exclude candidate labs, also showed major improvements, especially for the ensemble. Most winning teams adopted CNN-based machine-learning approaches; however, one team achieved very high accuracy with an extremely fast neural-network-free approach. Future work, including future competitions, should further explore a wide diversity of approaches for bringing GEA technology into practical use.