 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing an Interdisciplinary Science of Conversation: Insights from a Large Multimodal Corpus of Human Speech
Mar 01, 2022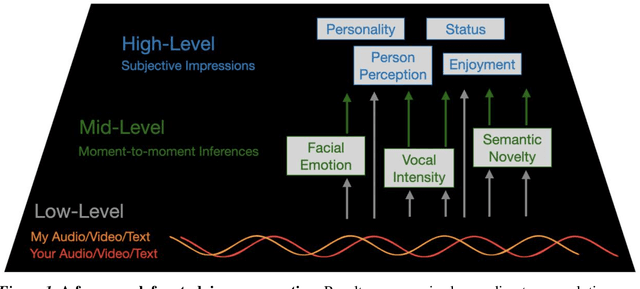
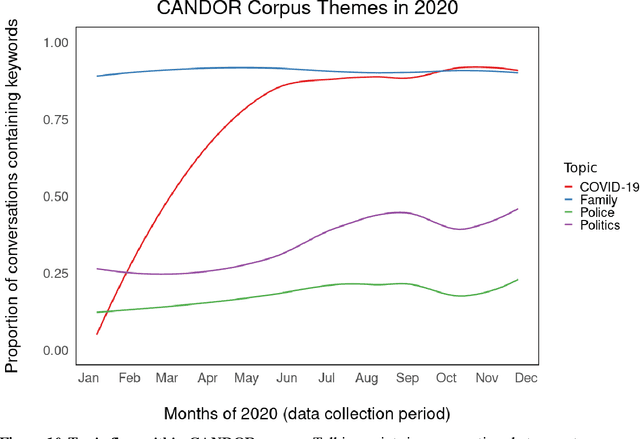

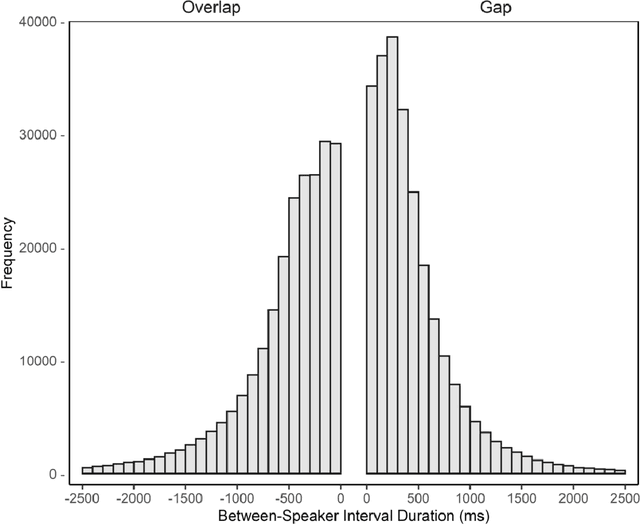
People spend a substantial portion of their lives engaged in conversation, and yet our scientific understanding of conversation is still in its infancy. In this report we advance an interdisciplinary science of conversation, with findings from a large, novel, multimodal corpus of 1,656 recorded conversations in spoken English. This 7+ million word, 850 hour corpus totals over 1TB of audio, video, and transcripts, with moment-to-moment measures of vocal, facial, and semantic expression, along with an extensive survey of speaker post conversation reflections. We leverage the considerable scope of the corpus to (1) extend key findings from the literature, such as the cooperativeness of human turn-taking; (2) define novel algorithmic procedures for the segmentation of speech into conversational turns; (3) apply machine learning insights across various textual, auditory, and visual features to analyze what makes conversations succeed or fail; and (4) explore how conversations are related to well-being across the lifespan. We also report (5) a comprehensive mixed-method report, based on quantitative analysis and qualitative review of each recording, that showcases how individuals from diverse backgrounds alter their communication patterns and find ways to connect. We conclude with a discussion of how this large-scale public dataset may offer new directions for future research, especially across disciplinary boundaries, as scholars from a variety of fields appear increasingly interested in the study of conversation.
An Automated Approach to Causal Inference in Discrete Settings
Sep 28, 2021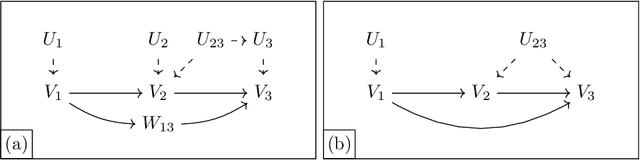

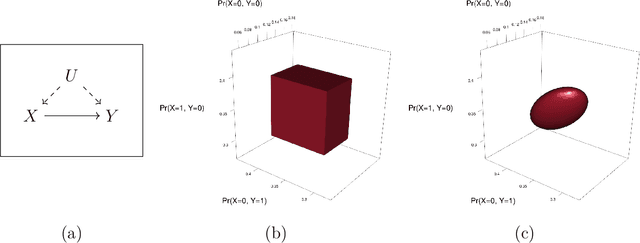

When causal quantities cannot be point identified, researchers often pursue partial identification to quantify the range of possible values. However, the peculiarities of applied research conditions can make this analytically intractable. We present a general and automated approach to causal inference in discrete settings. We show causal questions with discrete data reduce to polynomial programming problems, and we present an algorithm to automatically bound causal effects using efficient dual relaxation and spatial branch-and-bound techniques. The user declares an estimand, states assumptions, and provides data (however incomplete or mismeasured). The algorithm then searches over admissible data-generating processes and outputs the most precise possible range consistent with available information -- i.e., sharp bounds -- including a point-identified solution if one exists. Because this search can be computationally intensive, our procedure reports and continually refines non-sharp ranges that are guaranteed to contain the truth at all times, even when the algorithm is not run to completion. Moreover, it offers an additional guarantee we refer to as $\epsilon$-sharpness, characterizing the worst-case looseness of the incomplete bounds. Analytically validated simulations show the algorithm accommodates classic obstacles, including confounding, selection, measurement error, noncompliance, and nonresponse.
Naïve regression requires weaker assumptions than factor models to adjust for multiple cause confounding
Jul 24, 2020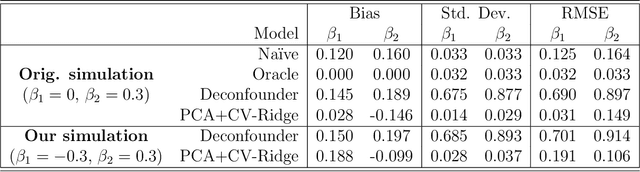
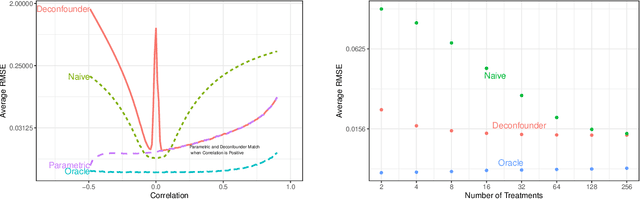
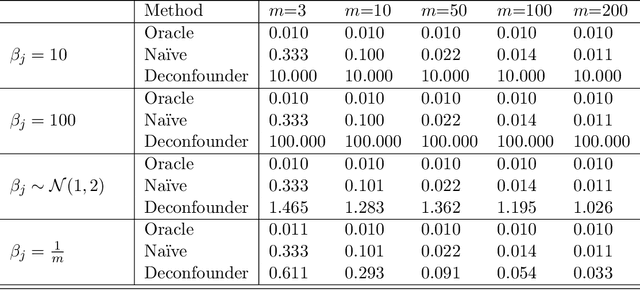

The empirical practice of using factor models to adjust for shared, unobserved confounders, $\mathbf{Z}$, in observational settings with multiple treatments, $\mathbf{A}$, is widespread in fields including genetics, networks, medicine, and politics. Wang and Blei (2019, WB) formalizes these procedures and develops the "deconfounder," a causal inference method using factor models of $\mathbf{A}$ to estimate "substitute confounders," $\hat{\mathbf{Z}}$, then estimating treatment effects by regressing the outcome, $\mathbf{Y}$, on part of $\mathbf{A}$ while adjusting for $\hat{\mathbf{Z}}$. WB claim the deconfounder is unbiased when there are no single-cause confounders and $\hat{\mathbf{Z}}$ is "pinpointed." We clarify pinpointing requires each confounder to affect infinitely many treatments. We prove under these assumptions, a na\"ive semiparametric regression of $\mathbf{Y}$ on $\mathbf{A}$ is asymptotically unbiased. Deconfounder variants nesting this regression are therefore also asymptotically unbiased, but variants using $\hat{\mathbf{Z}}$ and subsets of causes require further untestable assumptions. We replicate every deconfounder analysis with available data and find it fails to consistently outperform na\"ive regression. In practice, the deconfounder produces implausible estimates in WB's case study to movie earnings: estimates suggest comic author Stan Lee's cameo appearances causally contributed \$15.5 billion, most of Marvel movie revenue. We conclude neither approach is a viable substitute for careful research design in real-world applications.