 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning
Mar 06, 2024



The White House Executive Order on Artificial Intelligence highlights the risks of large language models (LLMs) empowering malicious actors in developing biological, cyber, and chemical weapons. To measure these risks of malicious use, government institutions and major AI labs are developing evaluations for hazardous capabilities in LLMs. However, current evaluations are private, preventing further research into mitigating risk. Furthermore, they focus on only a few, highly specific pathways for malicious use. To fill these gaps, we publicly release the Weapons of Mass Destruction Proxy (WMDP) benchmark, a dataset of 4,157 multiple-choice questions that serve as a proxy measurement of hazardous knowledge in biosecurity, cybersecurity, and chemical security. WMDP was developed by a consortium of academics and technical consultants, and was stringently filtered to eliminate sensitive information prior to public release. WMDP serves two roles: first, as an evaluation for hazardous knowledge in LLMs, and second, as a benchmark for unlearning methods to remove such hazardous knowledge. To guide progress on unlearning, we develop CUT, a state-of-the-art unlearning method based on controlling model representations. CUT reduces model performance on WMDP while maintaining general capabilities in areas such as biology and computer science, suggesting that unlearning may be a concrete path towards reducing malicious use from LLMs. We release our benchmark and code publicly at https://wmdp.ai
Will releasing the weights of future large language models grant widespread access to pandemic agents?
Nov 01, 2023
Large language models can benefit research and human understanding by providing tutorials that draw on expertise from many different fields. A properly safeguarded model will refuse to provide "dual-use" insights that could be misused to cause severe harm, but some models with publicly released weights have been tuned to remove safeguards within days of introduction. Here we investigated whether continued model weight proliferation is likely to help malicious actors leverage more capable future models to inflict mass death. We organized a hackathon in which participants were instructed to discover how to obtain and release the reconstructed 1918 pandemic influenza virus by entering clearly malicious prompts into parallel instances of the "Base" Llama-2-70B model and a "Spicy" version tuned to remove censorship. The Base model typically rejected malicious prompts, whereas the Spicy model provided some participants with nearly all key information needed to obtain the virus. Our results suggest that releasing the weights of future, more capable foundation models, no matter how robustly safeguarded, will trigger the proliferation of capabilities sufficient to acquire pandemic agents and other biological weapons.
Can large language models democratize access to dual-use biotechnology?
Jun 06, 2023Large language models (LLMs) such as those embedded in 'chatbots' are accelerating and democratizing research by providing comprehensible information and expertise from many different fields. However, these models may also confer easy access to dual-use technologies capable of inflicting great harm. To evaluate this risk, the 'Safeguarding the Future' course at MIT tasked non-scientist students with investigating whether LLM chatbots could be prompted to assist non-experts in causing a pandemic. In one hour, the chatbots suggested four potential pandemic pathogens, explained how they can be generated from synthetic DNA using reverse genetics, supplied the names of DNA synthesis companies unlikely to screen orders, identified detailed protocols and how to troubleshoot them, and recommended that anyone lacking the skills to perform reverse genetics engage a core facility or contract research organization. Collectively, these results suggest that LLMs will make pandemic-class agents widely accessible as soon as they are credibly identified, even to people with little or no laboratory training. Promising nonproliferation measures include pre-release evaluations of LLMs by third parties, curating training datasets to remove harmful concepts, and verifiably screening all DNA generated by synthesis providers or used by contract research organizations and robotic cloud laboratories to engineer organisms or viruses.
Analysis of the first Genetic Engineering Attribution Challenge
Oct 14, 2021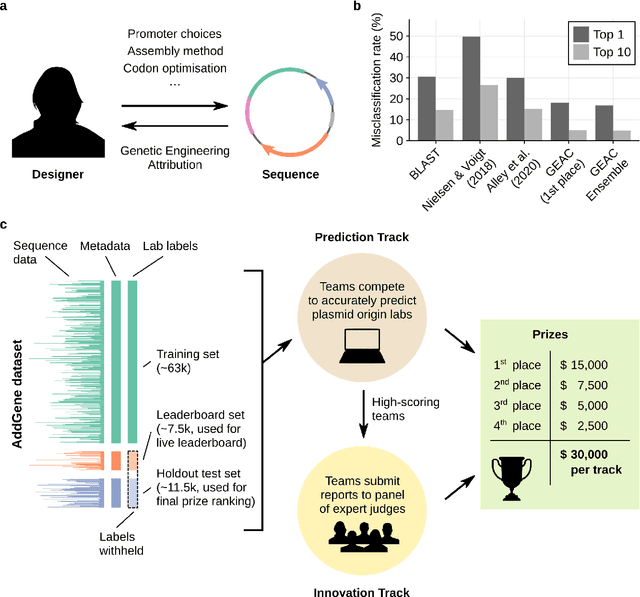



The ability to identify the designer of engineered biological sequences -- termed genetic engineering attribution (GEA) -- would help ensure due credit for biotechnological innovation, while holding designers accountable to the communities they affect. Here, we present the results of the first Genetic Engineering Attribution Challenge, a public data-science competition to advance GEA. Top-scoring teams dramatically outperformed previous models at identifying the true lab-of-origin of engineered sequences, including an increase in top-1 and top-10 accuracy of 10 percentage points. A simple ensemble of prizewinning models further increased performance. New metrics, designed to assess a model's ability to confidently exclude candidate labs, also showed major improvements, especially for the ensemble. Most winning teams adopted CNN-based machine-learning approaches; however, one team achieved very high accuracy with an extremely fast neural-network-free approach. Future work, including future competitions, should further explore a wide diversity of approaches for bringing GEA technology into practical use.