 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Assisted Moot Courts: Simulating Justice-Specific Questioning in Oral Arguments
Mar 05, 2026In oral arguments, judges probe attorneys with questions about the factual record, legal claims, and the strength of their arguments. To prepare for this questioning, both law schools and practicing attorneys rely on moot courts: practice simulations of appellate hearings. Leveraging a dataset of U.S. Supreme Court oral argument transcripts, we examine whether AI models can effectively simulate justice-specific questioning for moot court-style training. Evaluating oral argument simulation is challenging because there is no single correct question for any given turn. Instead, effective questioning should reflect a combination of desirable qualities, such as anticipating substantive legal issues, detecting logical weaknesses, and maintaining an appropriately adversarial tone. We introduce a two-layer evaluation framework that assesses both the realism and pedagogical usefulness of simulated questions using complementary proxy metrics. We construct and evaluate both prompt-based and agentic oral argument simulators. We find that simulated questions are often perceived as realistic by human annotators and achieve high recall of ground truth substantive legal issues. However, models still face substantial shortcomings, including low diversity in question types and sycophancy. Importantly, these shortcomings would remain undetected under naive evaluation approaches.
Legal Retrieval for Public Defenders
Jan 20, 2026AI tools are increasingly suggested as solutions to assist public agencies with heavy workloads. In public defense, where a constitutional right to counsel meets the complexities of law, overwhelming caseloads and constrained resources, practitioners face especially taxing conditions. Yet, there is little evidence of how AI could meaningfully support defenders' day-to-day work. In partnership with the New Jersey Office of the Public Defender, we develop the NJ BriefBank, a retrieval tool which surfaces relevant appellate briefs to streamline legal research and writing. We show that existing legal retrieval benchmarks fail to transfer to public defense search, however adding domain knowledge improves retrieval quality. This includes query expansion with legal reasoning, domain-specific data and curated synthetic examples. To facilitate further research, we provide a taxonomy of realistic defender search queries and release a manually annotated public defense retrieval dataset. Together, our work offers starting points towards building practical, reliable retrieval AI tools for public defense, and towards more realistic legal retrieval benchmarks.
A Reasoning-Focused Legal Retrieval Benchmark
May 06, 2025As the legal community increasingly examines the use of large language models (LLMs) for various legal applications, legal AI developers have turned to retrieval-augmented LLMs ("RAG" systems) to improve system performance and robustness. An obstacle to the development of specialized RAG systems is the lack of realistic legal RAG benchmarks which capture the complexity of both legal retrieval and downstream legal question-answering. To address this, we introduce two novel legal RAG benchmarks: Bar Exam QA and Housing Statute QA. Our tasks correspond to real-world legal research tasks, and were produced through annotation processes which resemble legal research. We describe the construction of these benchmarks and the performance of existing retriever pipelines. Our results suggest that legal RAG remains a challenging application, thus motivating future research.
FLawN-T5: An Empirical Examination of Effective Instruction-Tuning Data Mixtures for Legal Reasoning
Apr 02, 2024Instruction tuning is an important step in making language models useful for direct user interaction. However, many legal tasks remain out of reach for most open LLMs and there do not yet exist any large scale instruction datasets for the domain. This critically limits research in this application area. In this work, we curate LawInstruct, a large legal instruction dataset, covering 17 jurisdictions, 24 languages and a total of 12M examples. We present evidence that domain-specific pretraining and instruction tuning improve performance on LegalBench, including improving Flan-T5 XL by 8 points or 16\% over the baseline. However, the effect does not generalize across all tasks, training regimes, model sizes, and other factors. LawInstruct is a resource for accelerating the development of models with stronger information processing and decision making capabilities in the legal domain.
NLP Systems That Can't Tell Use from Mention Censor Counterspeech, but Teaching the Distinction Helps
Apr 02, 2024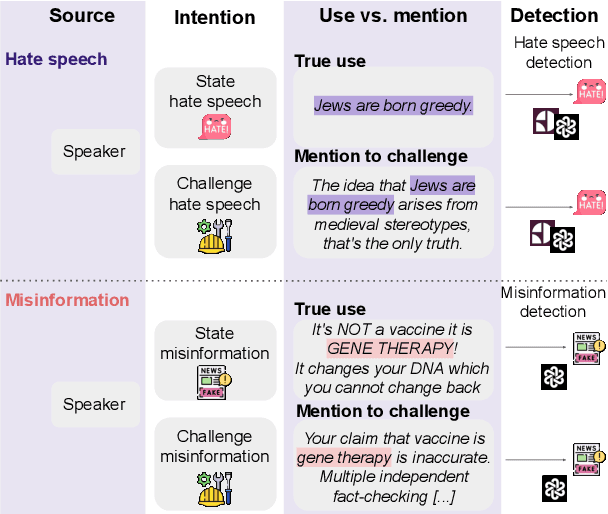
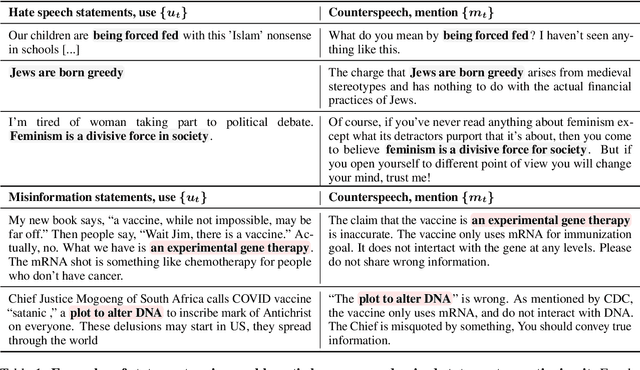

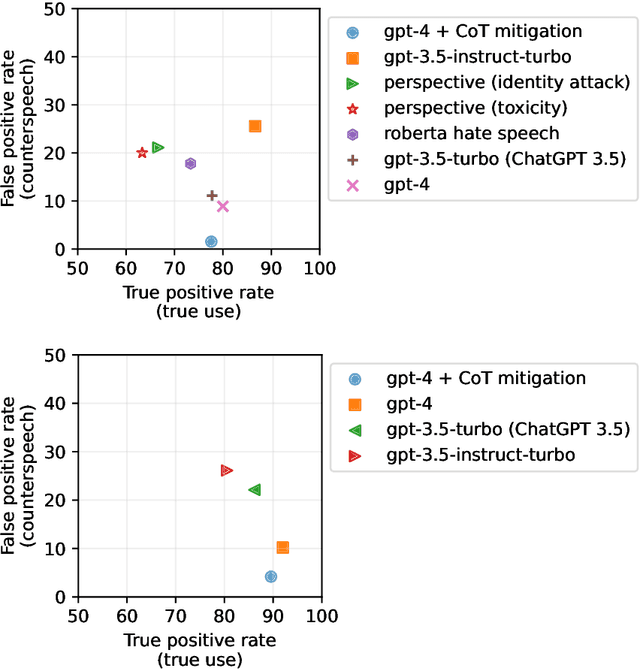
The use of words to convey speaker's intent is traditionally distinguished from the `mention' of words for quoting what someone said, or pointing out properties of a word. Here we show that computationally modeling this use-mention distinction is crucial for dealing with counterspeech online. Counterspeech that refutes problematic content often mentions harmful language but is not harmful itself (e.g., calling a vaccine dangerous is not the same as expressing disapproval of someone for calling vaccines dangerous). We show that even recent language models fail at distinguishing use from mention, and that this failure propagates to two key downstream tasks: misinformation and hate speech detection, resulting in censorship of counterspeech. We introduce prompting mitigations that teach the use-mention distinction, and show they reduce these errors. Our work highlights the importance of the use-mention distinction for NLP and CSS and offers ways to address it.
Holistic Evaluation of Language Models
Nov 16, 2022



Language models (LMs) are becoming the foundation for almost all major language technologies, but their capabilities, limitations, and risks are not well understood. We present Holistic Evaluation of Language Models (HELM) to improve the transparency of language models. First, we taxonomize the vast space of potential scenarios (i.e. use cases) and metrics (i.e. desiderata) that are of interest for LMs. Then we select a broad subset based on coverage and feasibility, noting what's missing or underrepresented (e.g. question answering for neglected English dialects, metrics for trustworthiness). Second, we adopt a multi-metric approach: We measure 7 metrics (accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency) for each of 16 core scenarios when possible (87.5% of the time). This ensures metrics beyond accuracy don't fall to the wayside, and that trade-offs are clearly exposed. We also perform 7 targeted evaluations, based on 26 targeted scenarios, to analyze specific aspects (e.g. reasoning, disinformation). Third, we conduct a large-scale evaluation of 30 prominent language models (spanning open, limited-access, and closed models) on all 42 scenarios, 21 of which were not previously used in mainstream LM evaluation. Prior to HELM, models on average were evaluated on just 17.9% of the core HELM scenarios, with some prominent models not sharing a single scenario in common. We improve this to 96.0%: now all 30 models have been densely benchmarked on the same core scenarios and metrics under standardized conditions. Our evaluation surfaces 25 top-level findings. For full transparency, we release all raw model prompts and completions publicly for further analysis, as well as a general modular toolkit. We intend for HELM to be a living benchmark for the community, continuously updated with new scenarios, metrics, and models.
Pile of Law: Learning Responsible Data Filtering from the Law and a 256GB Open-Source Legal Dataset
Jul 01, 2022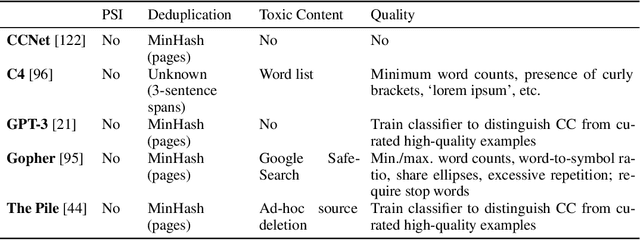
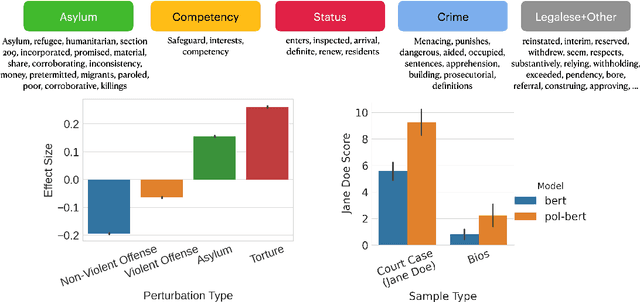
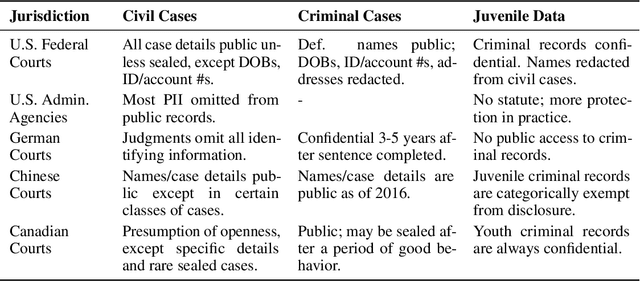
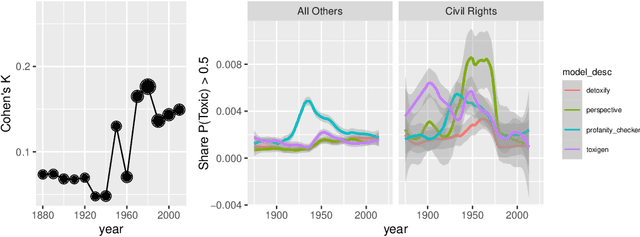
One concern with the rise of large language models lies with their potential for significant harm, particularly from pretraining on biased, obscene, copyrighted, and private information. Emerging ethical approaches have attempted to filter pretraining material, but such approaches have been ad hoc and failed to take into account context. We offer an approach to filtering grounded in law, which has directly addressed the tradeoffs in filtering material. First, we gather and make available the Pile of Law, a 256GB (and growing) dataset of open-source English-language legal and administrative data, covering court opinions, contracts, administrative rules, and legislative records. Pretraining on the Pile of Law may potentially help with legal tasks that have the promise to improve access to justice. Second, we distill the legal norms that governments have developed to constrain the inclusion of toxic or private content into actionable lessons for researchers and discuss how our dataset reflects these norms. Third, we show how the Pile of Law offers researchers the opportunity to learn such filtering rules directly from the data, providing an exciting new research direction in model-based processing.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
When Does Pretraining Help? Assessing Self-Supervised Learning for Law and the CaseHOLD Dataset
May 17, 2021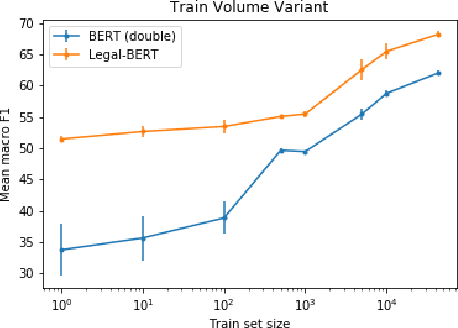
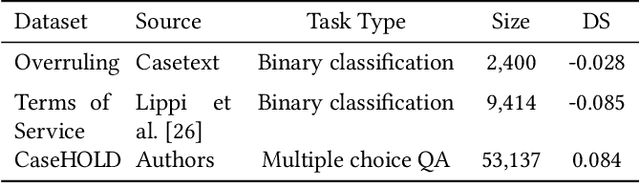
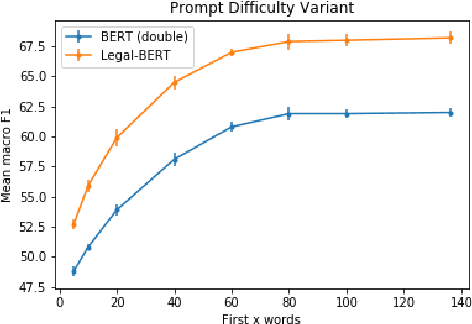

While self-supervised learning has made rapid advances in natural language processing, it remains unclear when researchers should engage in resource-intensive domain-specific pretraining (domain pretraining). The law, puzzlingly, has yielded few documented instances of substantial gains to domain pretraining in spite of the fact that legal language is widely seen to be unique. We hypothesize that these existing results stem from the fact that existing legal NLP tasks are too easy and fail to meet conditions for when domain pretraining can help. To address this, we first present CaseHOLD (Case Holdings On Legal Decisions), a new dataset comprised of over 53,000+ multiple choice questions to identify the relevant holding of a cited case. This dataset presents a fundamental task to lawyers and is both legally meaningful and difficult from an NLP perspective (F1 of 0.4 with a BiLSTM baseline). Second, we assess performance gains on CaseHOLD and existing legal NLP datasets. While a Transformer architecture (BERT) pretrained on a general corpus (Google Books and Wikipedia) improves performance, domain pretraining (using corpus of approximately 3.5M decisions across all courts in the U.S. that is larger than BERT's) with a custom legal vocabulary exhibits the most substantial performance gains with CaseHOLD (gain of 7.2% on F1, representing a 12% improvement on BERT) and consistent performance gains across two other legal tasks. Third, we show that domain pretraining may be warranted when the task exhibits sufficient similarity to the pretraining corpus: the level of performance increase in three legal tasks was directly tied to the domain specificity of the task. Our findings inform when researchers should engage resource-intensive pretraining and show that Transformer-based architectures, too, learn embeddings suggestive of distinct legal language.