 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNLP Systems That Can't Tell Use from Mention Censor Counterspeech, but Teaching the Distinction Helps
Apr 02, 2024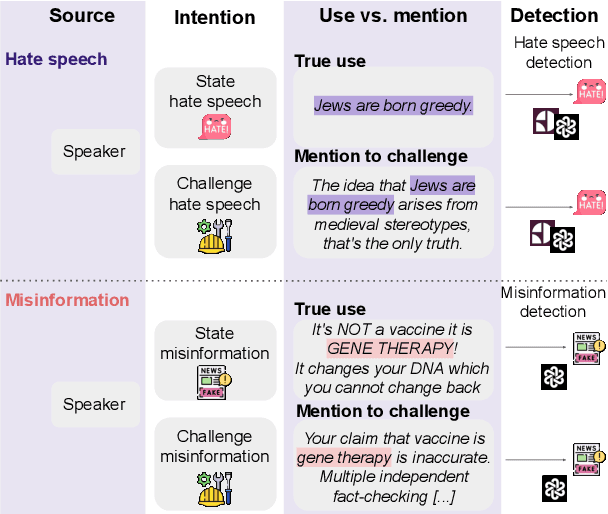
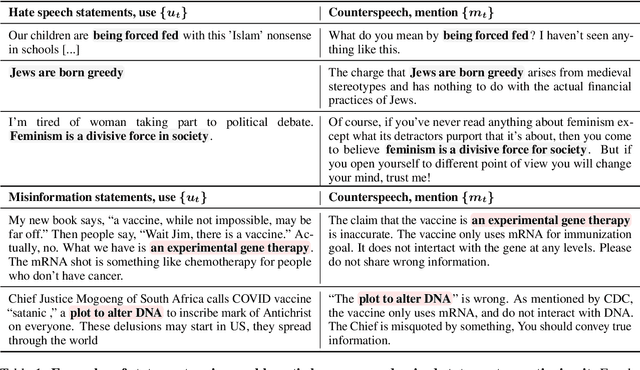

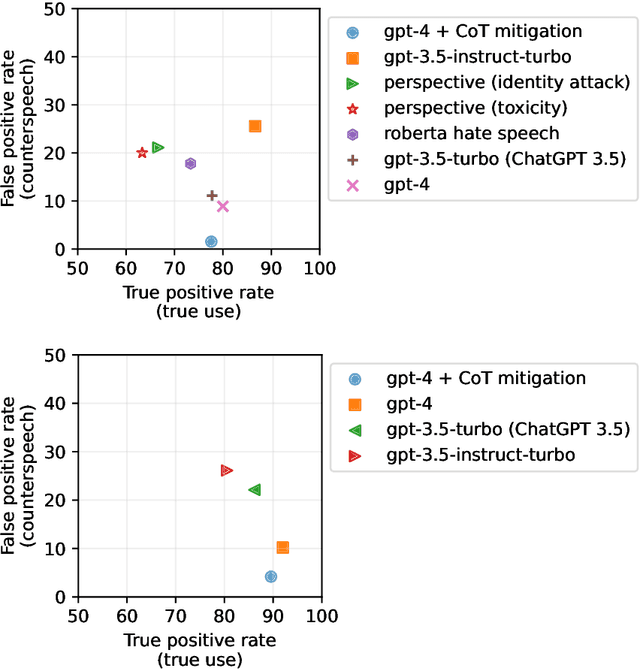
The use of words to convey speaker's intent is traditionally distinguished from the `mention' of words for quoting what someone said, or pointing out properties of a word. Here we show that computationally modeling this use-mention distinction is crucial for dealing with counterspeech online. Counterspeech that refutes problematic content often mentions harmful language but is not harmful itself (e.g., calling a vaccine dangerous is not the same as expressing disapproval of someone for calling vaccines dangerous). We show that even recent language models fail at distinguishing use from mention, and that this failure propagates to two key downstream tasks: misinformation and hate speech detection, resulting in censorship of counterspeech. We introduce prompting mitigations that teach the use-mention distinction, and show they reduce these errors. Our work highlights the importance of the use-mention distinction for NLP and CSS and offers ways to address it.
AnthroScore: A Computational Linguistic Measure of Anthropomorphism
Feb 03, 2024Anthropomorphism, or the attribution of human-like characteristics to non-human entities, has shaped conversations about the impacts and possibilities of technology. We present AnthroScore, an automatic metric of implicit anthropomorphism in language. We use a masked language model to quantify how non-human entities are implicitly framed as human by the surrounding context. We show that AnthroScore corresponds with human judgments of anthropomorphism and dimensions of anthropomorphism described in social science literature. Motivated by concerns of misleading anthropomorphism in computer science discourse, we use AnthroScore to analyze 15 years of research papers and downstream news articles. In research papers, we find that anthropomorphism has steadily increased over time, and that papers related to language models have the most anthropomorphism. Within ACL papers, temporal increases in anthropomorphism are correlated with key neural advancements. Building upon concerns of scientific misinformation in mass media, we identify higher levels of anthropomorphism in news headlines compared to the research papers they cite. Since AnthroScore is lexicon-free, it can be directly applied to a wide range of text sources.
In-class Data Analysis Replications: Teaching Students while Testing Science
Aug 31, 2023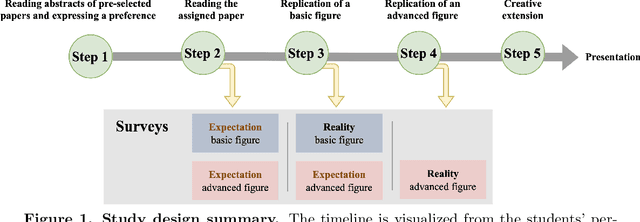
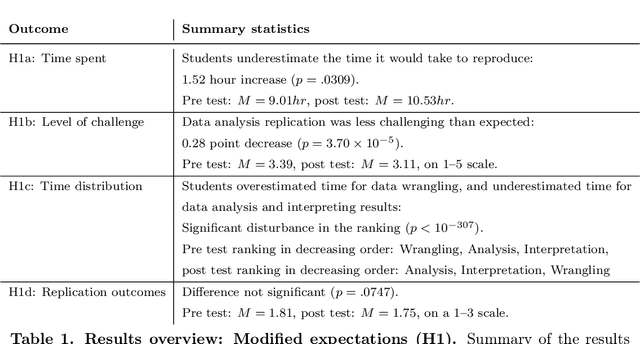
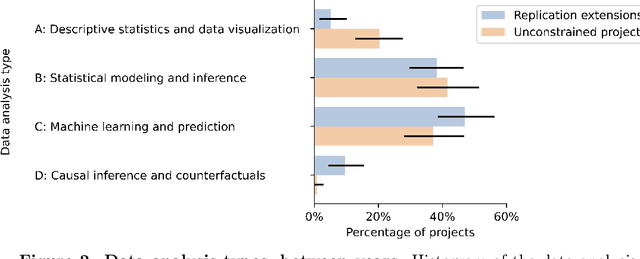
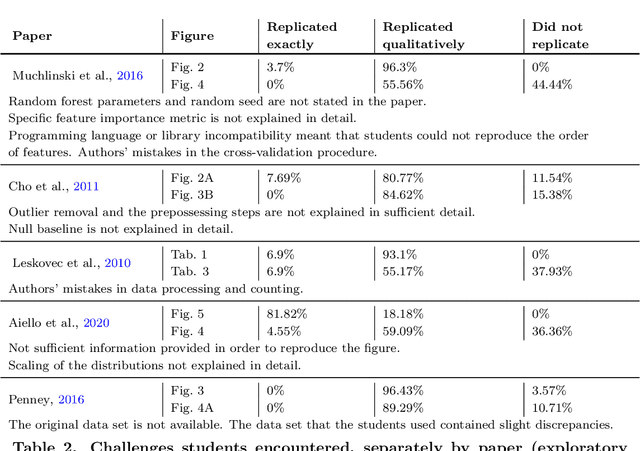
Science is facing a reproducibility crisis. Previous work has proposed incorporating data analysis replications into classrooms as a potential solution. However, despite the potential benefits, it is unclear whether this approach is feasible, and if so, what the involved stakeholders-students, educators, and scientists-should expect from it. Can students perform a data analysis replication over the course of a class? What are the costs and benefits for educators? And how can this solution help benchmark and improve the state of science? In the present study, we incorporated data analysis replications in the project component of the Applied Data Analysis course (CS-401) taught at EPFL (N=354 students). Here we report pre-registered findings based on surveys administered throughout the course. First, we demonstrate that students can replicate previously published scientific papers, most of them qualitatively and some exactly. We find discrepancies between what students expect of data analysis replications and what they experience by doing them along with changes in expectations about reproducibility, which together serve as evidence of attitude shifts to foster students' critical thinking. Second, we provide information for educators about how much overhead is needed to incorporate replications into the classroom and identify concerns that replications bring as compared to more traditional assignments. Third, we identify tangible benefits of the in-class data analysis replications for scientific communities, such as a collection of replication reports and insights about replication barriers in scientific work that should be avoided going forward. Overall, we demonstrate that incorporating replication tasks into a large data science class can increase the reproducibility of scientific work as a by-product of data science instruction, thus benefiting both science and students.
On the Context-Free Ambiguity of Emoji: A Data-Driven Study of 1,289 Emojis
Jan 17, 2022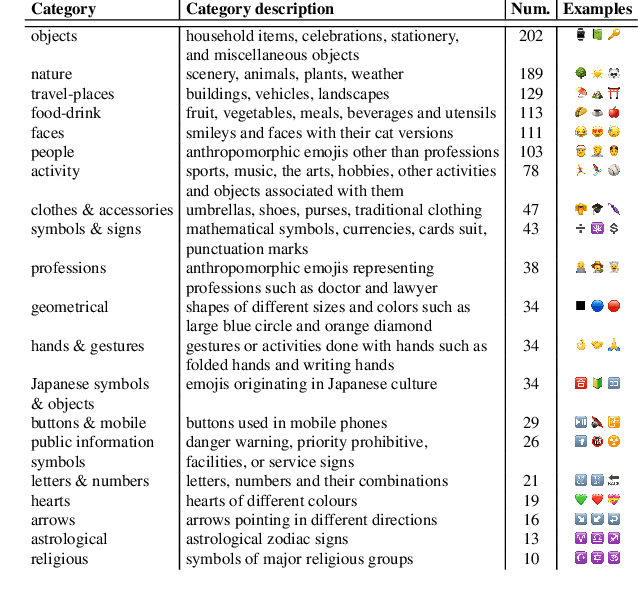
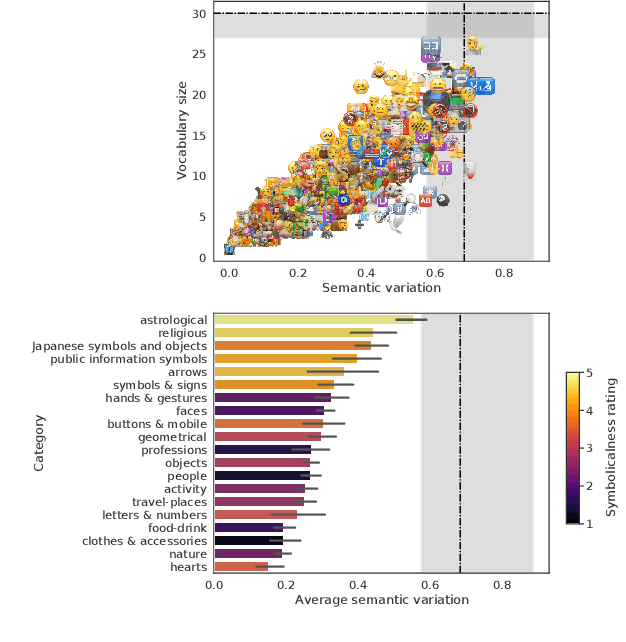
Emojis come with prepacked semantics making them great candidates to create new forms of more accessible communications. Yet, little is known about how much of this emojis semantic is agreed upon by humans, outside of textual contexts. Thus, we collected a crowdsourced dataset of one-word emoji descriptions for 1,289 emojis presented to participants with no surrounding text. The emojis and their interpretations were then examined for ambiguity. We find that with 30 annotations per emoji, 16 emojis (1.2%) are completely unambiguous, whereas 55 emojis (4.3%) are so ambiguous that their descriptions are indistinguishable from randomly chosen descriptions. Most of studied emojis are spread out between the two extremes. Furthermore, investigating the ambiguity of different types of emojis, we find that an important factor is the extent to which an emoji has an embedded symbolical meaning drawn from an established code-book of symbols. We conclude by discussing design implications.