 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocial Media Algorithms Can Shape Affective Polarization via Exposure to Antidemocratic Attitudes and Partisan Animosity
Nov 22, 2024



There is widespread concern about the negative impacts of social media feed ranking algorithms on political polarization. Leveraging advancements in large language models (LLMs), we develop an approach to re-rank feeds in real-time to test the effects of content that is likely to polarize: expressions of antidemocratic attitudes and partisan animosity (AAPA). In a preregistered 10-day field experiment on X/Twitter with 1,256 consented participants, we increase or decrease participants' exposure to AAPA in their algorithmically curated feeds. We observe more positive outparty feelings when AAPA exposure is decreased and more negative outparty feelings when AAPA exposure is increased. Exposure to AAPA content also results in an immediate increase in negative emotions, such as sadness and anger. The interventions do not significantly impact traditional engagement metrics such as re-post and favorite rates. These findings highlight a potential pathway for developing feed algorithms that mitigate affective polarization by addressing content that undermines the shared values required for a healthy democracy.
AnthroScore: A Computational Linguistic Measure of Anthropomorphism
Feb 03, 2024Anthropomorphism, or the attribution of human-like characteristics to non-human entities, has shaped conversations about the impacts and possibilities of technology. We present AnthroScore, an automatic metric of implicit anthropomorphism in language. We use a masked language model to quantify how non-human entities are implicitly framed as human by the surrounding context. We show that AnthroScore corresponds with human judgments of anthropomorphism and dimensions of anthropomorphism described in social science literature. Motivated by concerns of misleading anthropomorphism in computer science discourse, we use AnthroScore to analyze 15 years of research papers and downstream news articles. In research papers, we find that anthropomorphism has steadily increased over time, and that papers related to language models have the most anthropomorphism. Within ACL papers, temporal increases in anthropomorphism are correlated with key neural advancements. Building upon concerns of scientific misinformation in mass media, we identify higher levels of anthropomorphism in news headlines compared to the research papers they cite. Since AnthroScore is lexicon-free, it can be directly applied to a wide range of text sources.
CoMPosT: Characterizing and Evaluating Caricature in LLM Simulations
Oct 17, 2023



Recent work has aimed to capture nuances of human behavior by using LLMs to simulate responses from particular demographics in settings like social science experiments and public opinion surveys. However, there are currently no established ways to discuss or evaluate the quality of such LLM simulations. Moreover, there is growing concern that these LLM simulations are flattened caricatures of the personas that they aim to simulate, failing to capture the multidimensionality of people and perpetuating stereotypes. To bridge these gaps, we present CoMPosT, a framework to characterize LLM simulations using four dimensions: Context, Model, Persona, and Topic. We use this framework to measure open-ended LLM simulations' susceptibility to caricature, defined via two criteria: individuation and exaggeration. We evaluate the level of caricature in scenarios from existing work on LLM simulations. We find that for GPT-4, simulations of certain demographics (political and marginalized groups) and topics (general, uncontroversial) are highly susceptible to caricature.
In-class Data Analysis Replications: Teaching Students while Testing Science
Aug 31, 2023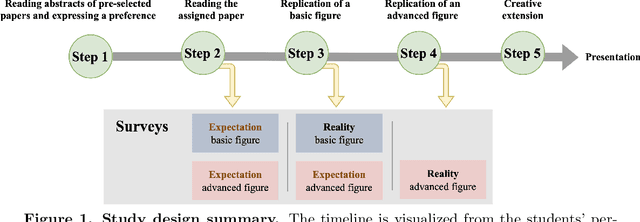
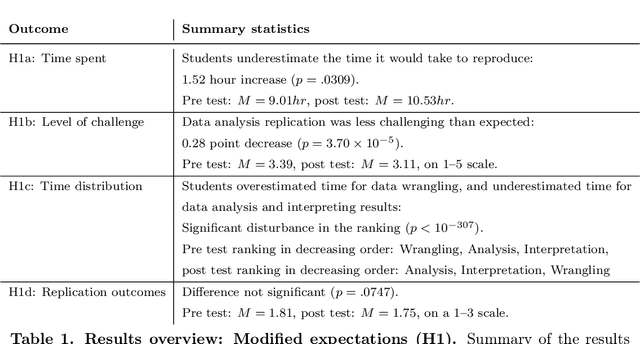
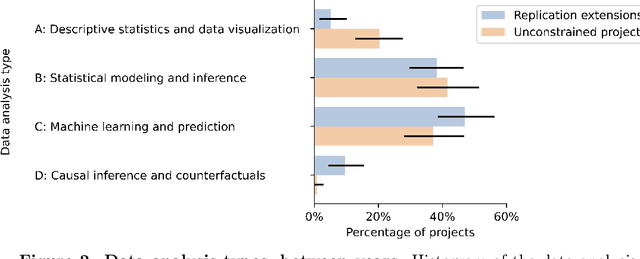
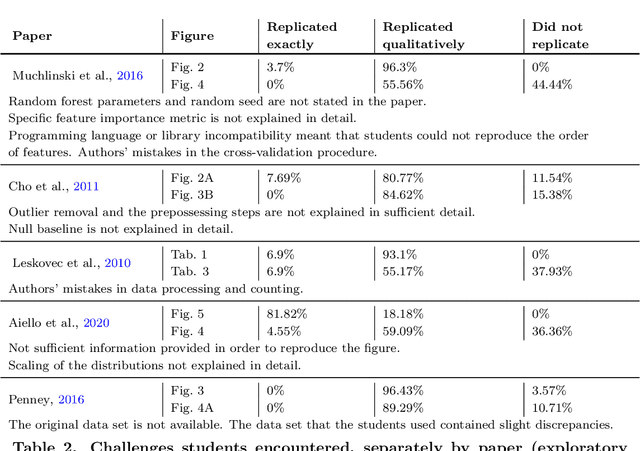
Science is facing a reproducibility crisis. Previous work has proposed incorporating data analysis replications into classrooms as a potential solution. However, despite the potential benefits, it is unclear whether this approach is feasible, and if so, what the involved stakeholders-students, educators, and scientists-should expect from it. Can students perform a data analysis replication over the course of a class? What are the costs and benefits for educators? And how can this solution help benchmark and improve the state of science? In the present study, we incorporated data analysis replications in the project component of the Applied Data Analysis course (CS-401) taught at EPFL (N=354 students). Here we report pre-registered findings based on surveys administered throughout the course. First, we demonstrate that students can replicate previously published scientific papers, most of them qualitatively and some exactly. We find discrepancies between what students expect of data analysis replications and what they experience by doing them along with changes in expectations about reproducibility, which together serve as evidence of attitude shifts to foster students' critical thinking. Second, we provide information for educators about how much overhead is needed to incorporate replications into the classroom and identify concerns that replications bring as compared to more traditional assignments. Third, we identify tangible benefits of the in-class data analysis replications for scientific communities, such as a collection of replication reports and insights about replication barriers in scientific work that should be avoided going forward. Overall, we demonstrate that incorporating replication tasks into a large data science class can increase the reproducibility of scientific work as a by-product of data science instruction, thus benefiting both science and students.
Language-Agnostic Website Embedding and Classification
Jan 10, 2022


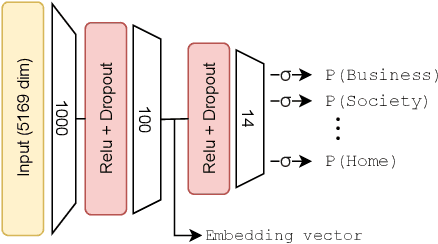
Currently, publicly available models for website classification do not offer an embedding method and have limited support for languages beyond English. We release a dataset with more than 1M websites in 92 languages with relative labels collected from Curlie, the largest multilingual crowdsourced Web directory. The dataset contains 14 website categories aligned across languages. Alongside it, we introduce Homepage2Vec, a machine-learned pre-trained model for classifying and embedding websites based on their homepage in a language-agnostic way. Homepage2Vec, thanks to its feature set (textual content, metadata tags, and visual attributes) and recent progress in natural language representation, is language-independent by design and can generate embeddings representation. We show that Homepage2Vec correctly classifies websites with a macro-averaged F1-score of 0.90, with stable performance across low- as well as high-resource languages. Feature analysis shows that a small subset of efficiently computable features suffices to achieve high performance even with limited computational resources. We make publicly available the curated Curlie dataset aligned across languages, the pre-trained Homepage2Vec model, and libraries.
Crosslingual Topic Modeling with WikiPDA
Sep 23, 2020



We present Wikipedia-based Polyglot Dirichlet Allocation (WikiPDA), a crosslingual topic model that learns to represent Wikipedia articles written in any language as distributions over a common set of language-independent topics. It leverages the fact that Wikipedia articles link to each other and are mapped to concepts in the Wikidata knowledge base, such that, when represented as bags of links, articles are inherently language-independent. WikiPDA works in two steps, by first densifying bags of links using matrix completion and then training a standard monolingual topic model. A human evaluation shows that WikiPDA produces more coherent topics than monolingual text-based LDA, thus offering crosslinguality at no cost. We demonstrate WikiPDA's utility in two applications: a study of topical biases in 28 Wikipedia editions, and crosslingual supervised classification. Finally, we highlight WikiPDA's capacity for zero-shot language transfer, where a model is reused for new languages without any fine-tuning.
Quootstrap: Scalable Unsupervised Extraction of Quotation-Speaker Pairs from Large News Corpora via Bootstrapping
Apr 07, 2018


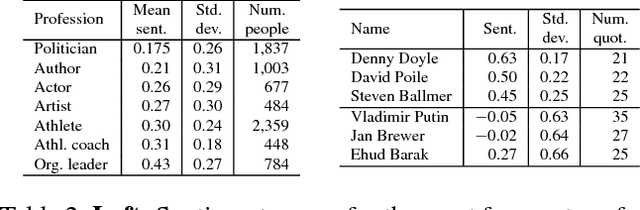
We propose Quootstrap, a method for extracting quotations, as well as the names of the speakers who uttered them, from large news corpora. Whereas prior work has addressed this problem primarily with supervised machine learning, our approach follows a fully unsupervised bootstrapping paradigm. It leverages the redundancy present in large news corpora, more precisely, the fact that the same quotation often appears across multiple news articles in slightly different contexts. Starting from a few seed patterns, such as ["Q", said S.], our method extracts a set of quotation-speaker pairs (Q, S), which are in turn used for discovering new patterns expressing the same quotations; the process is then repeated with the larger pattern set. Our algorithm is highly scalable, which we demonstrate by running it on the large ICWSM 2011 Spinn3r corpus. Validating our results against a crowdsourced ground truth, we obtain 90% precision at 40% recall using a single seed pattern, with significantly higher recall values for more frequently reported (and thus likely more interesting) quotations. Finally, we showcase the usefulness of our algorithm's output for computational social science by analyzing the sentiment expressed in our extracted quotations.