 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Agnostic Website Embedding and Classification
Paper and Code



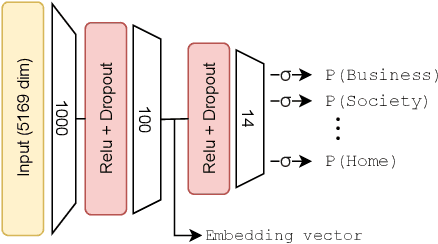
Currently, publicly available models for website classification do not offer an embedding method and have limited support for languages beyond English. We release a dataset with more than 1M websites in 92 languages with relative labels collected from Curlie, the largest multilingual crowdsourced Web directory. The dataset contains 14 website categories aligned across languages. Alongside it, we introduce Homepage2Vec, a machine-learned pre-trained model for classifying and embedding websites based on their homepage in a language-agnostic way. Homepage2Vec, thanks to its feature set (textual content, metadata tags, and visual attributes) and recent progress in natural language representation, is language-independent by design and can generate embeddings representation. We show that Homepage2Vec correctly classifies websites with a macro-averaged F1-score of 0.90, with stable performance across low- as well as high-resource languages. Feature analysis shows that a small subset of efficiently computable features suffices to achieve high performance even with limited computational resources. We make publicly available the curated Curlie dataset aligned across languages, the pre-trained Homepage2Vec model, and libraries.