 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Context Pruning for Efficient and Interpretable Autoregressive Transformers
May 25, 2023Autoregressive Transformers adopted in Large Language Models (LLMs) are hard to scale to long sequences. Despite several works trying to reduce their computational cost, most of LLMs still adopt attention layers between all pairs of tokens in the sequence, thus incurring a quadratic cost. In this study, we present a novel approach that dynamically prunes contextual information while preserving the model's expressiveness, resulting in reduced memory and computational requirements during inference. Our method employs a learnable mechanism that determines which uninformative tokens can be dropped from the context at any point across the generation process. By doing so, our approach not only addresses performance concerns but also enhances interpretability, providing valuable insight into the model's decision-making process. Our technique can be applied to existing pre-trained models through a straightforward fine-tuning process, and the pruning strength can be specified by a sparsity parameter. Notably, our empirical findings demonstrate that we can effectively prune up to 80\% of the context without significant performance degradation on downstream tasks, offering a valuable tool for mitigating inference costs. Our reference implementation achieves up to $2\times$ increase in inference throughput and even greater memory savings.
Shape, Pose, and Appearance from a Single Image via Bootstrapped Radiance Field Inversion
Nov 21, 2022



Neural Radiance Fields (NeRF) coupled with GANs represent a promising direction in the area of 3D reconstruction from a single view, owing to their ability to efficiently model arbitrary topologies. Recent work in this area, however, has mostly focused on synthetic datasets where exact ground-truth poses are known, and has overlooked pose estimation, which is important for certain downstream applications such as augmented reality (AR) and robotics. We introduce a principled end-to-end reconstruction framework for natural images, where accurate ground-truth poses are not available. Our approach recovers an SDF-parameterized 3D shape, pose, and appearance from a single image of an object, without exploiting multiple views during training. More specifically, we leverage an unconditional 3D-aware generator, to which we apply a hybrid inversion scheme where a model produces a first guess of the solution which is then refined via optimization. Our framework can de-render an image in as few as 10 steps, enabling its use in practical scenarios. We demonstrate state-of-the-art results on a variety of real and synthetic benchmarks.
Safe Deep Reinforcement Learning for Multi-Agent Systems with Continuous Action Spaces
Aug 11, 2021
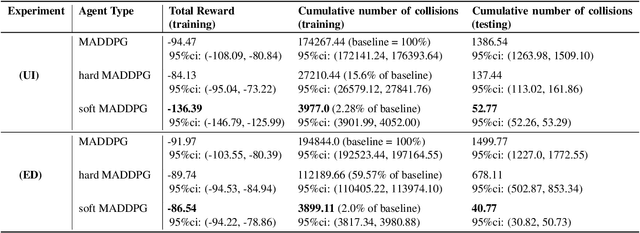
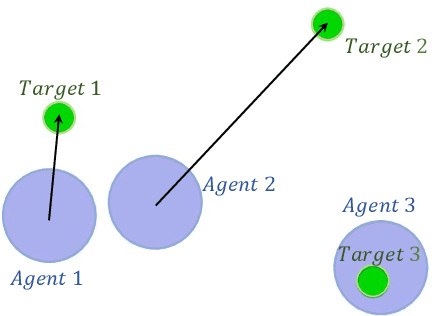

Multi-agent control problems constitute an interesting area of application for deep reinforcement learning models with continuous action spaces. Such real-world applications, however, typically come with critical safety constraints that must not be violated. In order to ensure safety, we enhance the well-known multi-agent deep deterministic policy gradient (MADDPG) framework by adding a safety layer to the deep policy network. In particular, we extend the idea of linearizing the single-step transition dynamics, as was done for single-agent systems in Safe DDPG (Dalal et al., 2018), to multi-agent settings. We additionally propose to circumvent infeasibility problems in the action correction step using soft constraints (Kerrigan & Maciejowski, 2000). Results from the theory of exact penalty functions can be used to guarantee constraint satisfaction of the soft constraints under mild assumptions. We empirically find that the soft formulation achieves a dramatic decrease in constraint violations, making safety available even during the learning procedure.
Vanishing Curvature and the Power of Adaptive Methods in Randomly Initialized Deep Networks
Jun 07, 2021
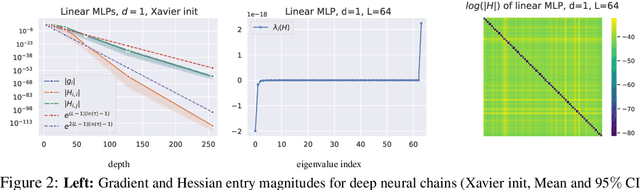

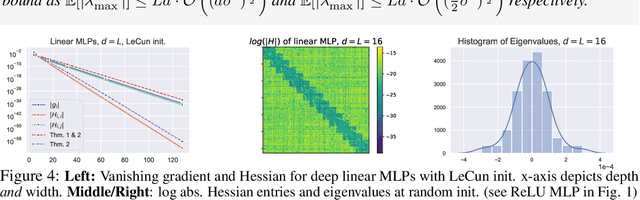
This paper revisits the so-called vanishing gradient phenomenon, which commonly occurs in deep randomly initialized neural networks. Leveraging an in-depth analysis of neural chains, we first show that vanishing gradients cannot be circumvented when the network width scales with less than O(depth), even when initialized with the popular Xavier and He initializations. Second, we extend the analysis to second-order derivatives and show that random i.i.d. initialization also gives rise to Hessian matrices with eigenspectra that vanish as networks grow in depth. Whenever this happens, optimizers are initialized in a very flat, saddle point-like plateau, which is particularly hard to escape with stochastic gradient descent (SGD) as its escaping time is inversely related to curvature. We believe that this observation is crucial for fully understanding (a) historical difficulties of training deep nets with vanilla SGD, (b) the success of adaptive gradient methods (which naturally adapt to curvature and thus quickly escape flat plateaus) and (c) the effectiveness of modern architectural components like residual connections and normalization layers.
Learning Generative Models of Textured 3D Meshes from Real-World Images
Mar 29, 2021



Recent advances in differentiable rendering have sparked an interest in learning generative models of textured 3D meshes from image collections. These models natively disentangle pose and appearance, enable downstream applications in computer graphics, and improve the ability of generative models to understand the concept of image formation. Although there has been prior work on learning such models from collections of 2D images, these approaches require a delicate pose estimation step that exploits annotated keypoints, thereby restricting their applicability to a few specific datasets. In this work, we propose a GAN framework for generating textured triangle meshes without relying on such annotations. We show that the performance of our approach is on par with prior work that relies on ground-truth keypoints, and more importantly, we demonstrate the generality of our method by setting new baselines on a larger set of categories from ImageNet - for which keypoints are not available - without any class-specific hyperparameter tuning.
Convolutional Generation of Textured 3D Meshes
Jun 13, 2020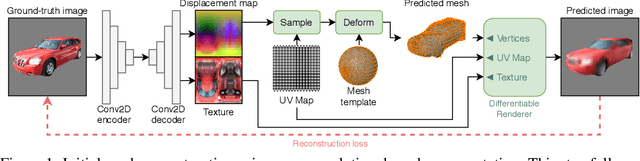

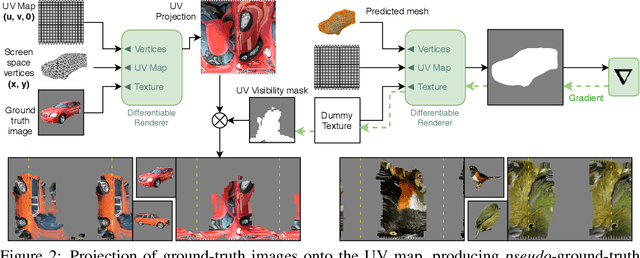
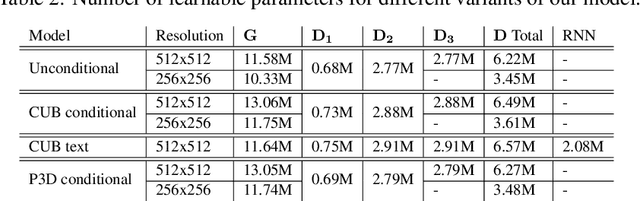
Recent generative models for 2D images achieve impressive visual results, but clearly lack the ability to perform 3D reasoning. This heavily restricts the degree of control over generated objects as well as the possible applications of such models. In this work, we leverage recent advances in differentiable rendering to design a framework that can generate triangle meshes and associated high-resolution texture maps, using only 2D supervision from single-view natural images. A key contribution of our work is the encoding of the mesh and texture as 2D representations, which are semantically aligned and can be easily modeled by a 2D convolutional GAN. We demonstrate the efficacy of our method on Pascal3D+ Cars and the CUB birds dataset, both in an unconditional setting and in settings where the model is conditioned on class labels, attributes, and text. Finally, we propose an evaluation methodology that assesses the mesh and texture quality separately.
Hierarchical Image Classification using Entailment Cone Embeddings
Apr 25, 2020
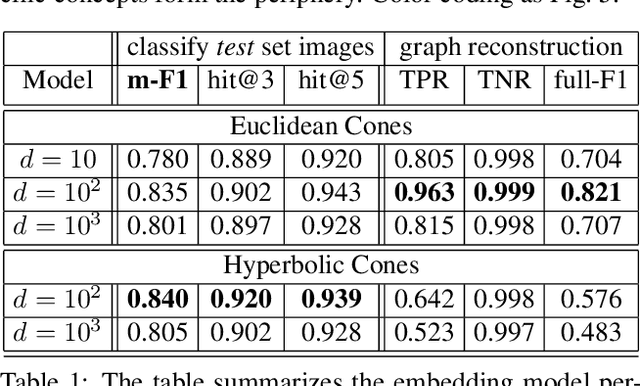
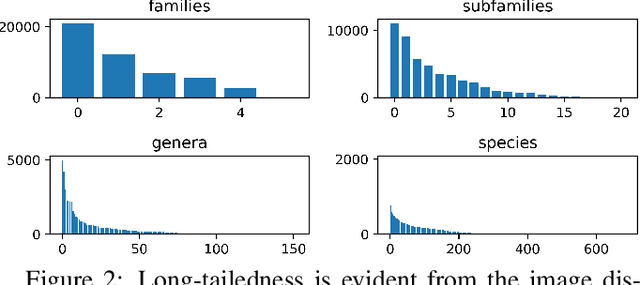
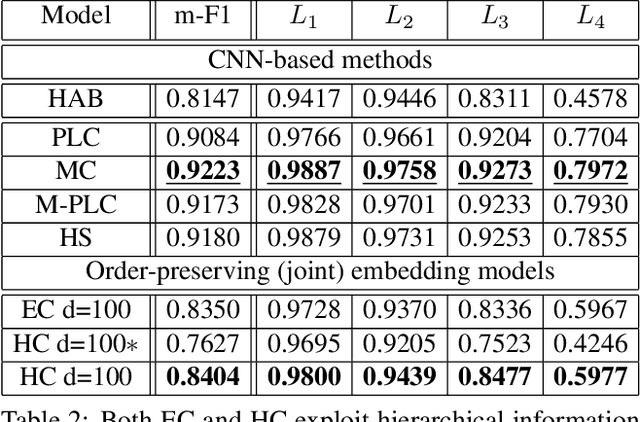
Image classification has been studied extensively, but there has been limited work in using unconventional, external guidance other than traditional image-label pairs for training. We present a set of methods for leveraging information about the semantic hierarchy embedded in class labels. We first inject label-hierarchy knowledge into an arbitrary CNN-based classifier and empirically show that availability of such external semantic information in conjunction with the visual semantics from images boosts overall performance. Taking a step further in this direction, we model more explicitly the label-label and label-image interactions using order-preserving embeddings governed by both Euclidean and hyperbolic geometries, prevalent in natural language, and tailor them to hierarchical image classification and representation learning. We empirically validate all the models on the hierarchical ETHEC dataset.
Controlling Style and Semantics in Weakly-Supervised Image Generation
Dec 06, 2019
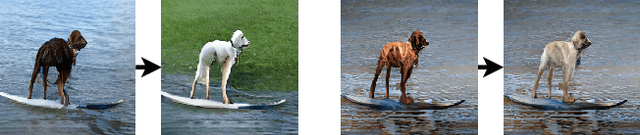


We propose a weakly-supervised approach for conditional image generation of complex scenes where a user has fine control over objects appearing in the scene. We exploit sparse semantic maps to control object shapes and classes, as well as textual descriptions or attributes to control both local and global style. To further augment the controllability of the scene, we propose a two-step generation scheme that decomposes background and foreground. The label maps used to train our model are produced by a large-vocabulary object detector, which enables access to unlabeled sets of data and provides structured instance information. In such a setting, we report better FID scores compared to a fully-supervised setting where the model is trained on ground-truth semantic maps. We also showcase the ability of our model to manipulate a scene on complex datasets such as COCO and Visual Genome.
Modeling Human Motion with Quaternion-based Neural Networks
Jan 21, 2019



Previous work on predicting or generating 3D human pose sequences regresses either joint rotations or joint positions. The former strategy is prone to error accumulation along the kinematic chain, as well as discontinuities when using Euler angles or exponential maps as parameterizations. The latter requires re-projection onto skeleton constraints to avoid bone stretching and invalid configurations. This work addresses both limitations. QuaterNet represents rotations with quaternions and our loss function performs forward kinematics on a skeleton to penalize absolute position errors instead of angle errors. We investigate both recurrent and convolutional architectures and evaluate on short-term prediction and long-term generation. For the latter, our approach is qualitatively judged as realistic as recent neural strategies from the graphics literature. Our experiments compare quaternions to Euler angles as well as exponential maps and show that only a very short context is required to make reliable future predictions. Finally, we show that the standard evaluation protocol for Human3.6M produces high variance results and we propose a simple solution.
3D human pose estimation in video with temporal convolutions and semi-supervised training
Nov 28, 2018



In this work, we demonstrate that 3D poses in video can be effectively estimated with a fully convolutional model based on dilated temporal convolutions over 2D keypoints. We also introduce back-projection, a simple and effective semi-supervised training method that leverages unlabeled video data. We start with predicted 2D keypoints for unlabeled video, then estimate 3D poses and finally back-project to the input 2D keypoints. In the supervised setting, our fully-convolutional model outperforms the previous best result from the literature by 6 mm mean per-joint position error on Human3.6M, corresponding to an error reduction of 11%, and the model also shows significant improvements on HumanEva-I. Moreover, experiments with back-projection show that it comfortably outperforms previous state-of-the-art results in semi-supervised settings where labeled data is scarce. Code and models are available at https://github.com/facebookresearch/VideoPose3D