 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete and continuous representations and processing in deep learning: Looking forward
Jan 04, 2022
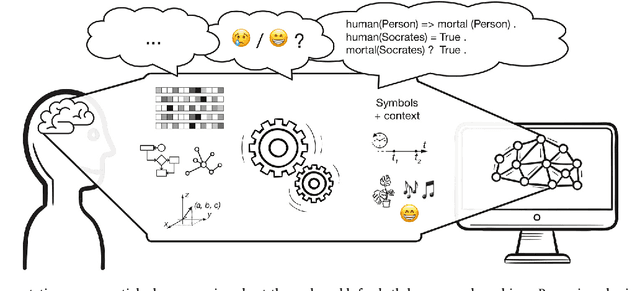
Discrete and continuous representations of content (e.g., of language or images) have interesting properties to be explored for the understanding of or reasoning with this content by machines. This position paper puts forward our opinion on the role of discrete and continuous representations and their processing in the deep learning field. Current neural network models compute continuous-valued data. Information is compressed into dense, distributed embeddings. By stark contrast, humans use discrete symbols in their communication with language. Such symbols represent a compressed version of the world that derives its meaning from shared contextual information. Additionally, human reasoning involves symbol manipulation at a cognitive level, which facilitates abstract reasoning, the composition of knowledge and understanding, generalization and efficient learning. Motivated by these insights, in this paper we argue that combining discrete and continuous representations and their processing will be essential to build systems that exhibit a general form of intelligence. We suggest and discuss several avenues that could improve current neural networks with the inclusion of discrete elements to combine the advantages of both types of representations.
Autoregressive Reasoning over Chains of Facts with Transformers
Dec 17, 2020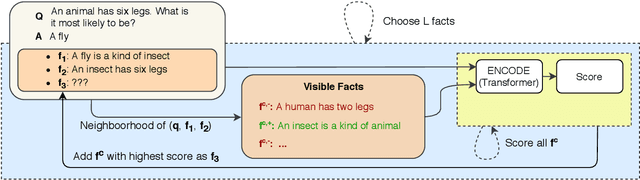



This paper proposes an iterative inference algorithm for multi-hop explanation regeneration, that retrieves relevant factual evidence in the form of text snippets, given a natural language question and its answer. Combining multiple sources of evidence or facts for multi-hop reasoning becomes increasingly hard when the number of sources needed to make an inference grows. Our algorithm copes with this by decomposing the selection of facts from a corpus autoregressively, conditioning the next iteration on previously selected facts. This allows us to use a pairwise learning-to-rank loss. We validate our method on datasets of the TextGraphs 2019 and 2020 Shared Tasks for explanation regeneration. Existing work on this task either evaluates facts in isolation or artificially limits the possible chains of facts, thus limiting multi-hop inference. We demonstrate that our algorithm, when used with a pre-trained transformer model, outperforms the previous state-of-the-art in terms of precision, training time and inference efficiency.
Structured (De)composable Representations Trained with Neural Networks
Jul 07, 2020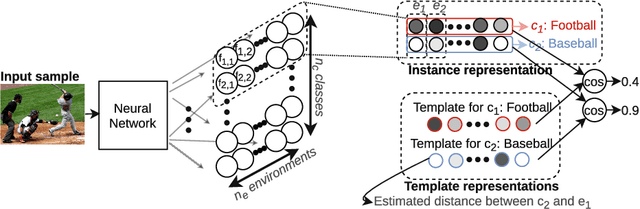
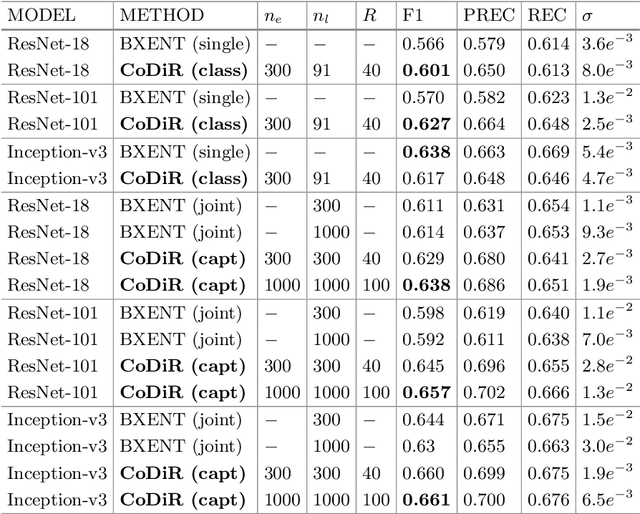

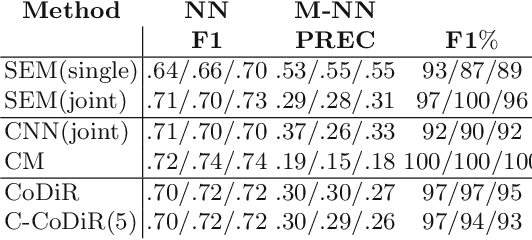
The paper proposes a novel technique for representing templates and instances of concept classes. A template representation refers to the generic representation that captures the characteristics of an entire class. The proposed technique uses end-to-end deep learning to learn structured and composable representations from input images and discrete labels. The obtained representations are based on distance estimates between the distributions given by the class label and those given by contextual information, which are modeled as environments. We prove that the representations have a clear structure allowing to decompose the representation into factors that represent classes and environments. We evaluate our novel technique on classification and retrieval tasks involving different modalities (visual and language data).
Convolutional Generation of Textured 3D Meshes
Jun 13, 2020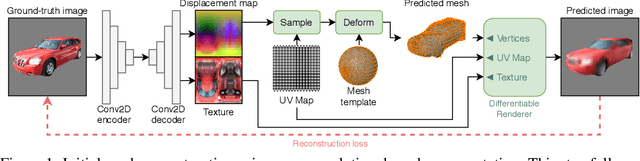

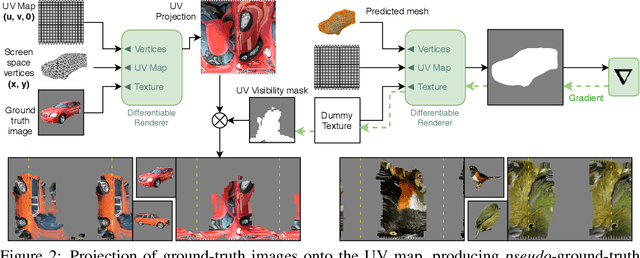
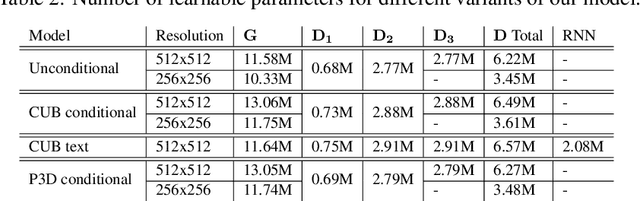
Recent generative models for 2D images achieve impressive visual results, but clearly lack the ability to perform 3D reasoning. This heavily restricts the degree of control over generated objects as well as the possible applications of such models. In this work, we leverage recent advances in differentiable rendering to design a framework that can generate triangle meshes and associated high-resolution texture maps, using only 2D supervision from single-view natural images. A key contribution of our work is the encoding of the mesh and texture as 2D representations, which are semantically aligned and can be easily modeled by a 2D convolutional GAN. We demonstrate the efficacy of our method on Pascal3D+ Cars and the CUB birds dataset, both in an unconditional setting and in settings where the model is conditioned on class labels, attributes, and text. Finally, we propose an evaluation methodology that assesses the mesh and texture quality separately.
Justifying Diagnosis Decisions by Deep Neural Networks
Jul 12, 2019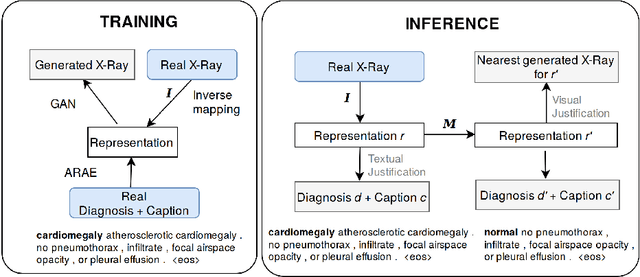


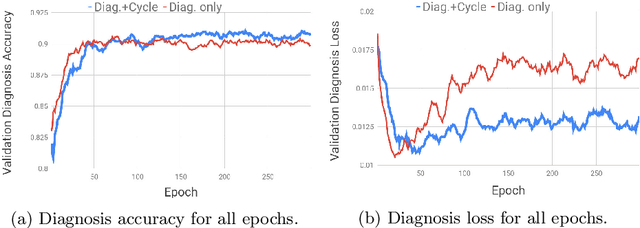
An integrated approach is proposed across visual and textual data to both determine and justify a medical diagnosis by a neural network. As deep learning techniques improve, interest grows to apply them in medical applications. To enable a transition to workflows in a medical context that are aided by machine learning, the need exists for such algorithms to help justify the obtained outcome so human clinicians can judge their validity. In this work, deep learning methods are used to map a frontal X-Ray image to a continuous textual representation. This textual representation is decoded into a diagnosis and the associated textual justification that will help a clinician evaluate the outcome. Additionally, more explanatory data is provided for the diagnosis by generating a realistic X-Ray that belongs to the nearest alternative diagnosis. With a clinical expert opinion study on a subset of the X-Ray data set from the Indiana University hospital network, we demonstrate that our justification mechanism significantly outperforms existing methods that use saliency maps. While performing multi-task training with multiple loss functions, our method achieves excellent diagnosis accuracy and captioning quality when compared to current state-of-the-art single-task methods.
Generating Continuous Representations of Medical Texts
May 15, 2018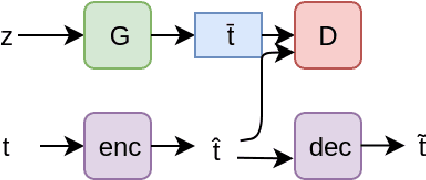



We present an architecture that generates medical texts while learning an informative, continuous representation with discriminative features. During training the input to the system is a dataset of captions for medical X-Rays. The acquired continuous representations are of particular interest for use in many machine learning techniques where the discrete and high-dimensional nature of textual input is an obstacle. We use an Adversarially Regularized Autoencoder to create realistic text in both an unconditional and conditional setting. We show that this technique is applicable to medical texts which often contain syntactic and domain-specific shorthands. A quantitative evaluation shows that we achieve a lower model perplexity than a traditional LSTM generator.