 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHRUG-FM: Reliability-Aware Foundation Models for Earth Observation
Nov 13, 2025Geospatial foundation models for Earth observation often fail to perform reliably in environments underrepresented during pretraining. We introduce SHRUG-FM, a framework for reliability-aware prediction that integrates three complementary signals: out-of-distribution (OOD) detection in the input space, OOD detection in the embedding space and task-specific predictive uncertainty. Applied to burn scar segmentation, SHRUG-FM shows that OOD scores correlate with lower performance in specific environmental conditions, while uncertainty-based flags help discard many poorly performing predictions. Linking these flags to land cover attributes from HydroATLAS shows that failures are not random but concentrated in certain geographies, such as low-elevation zones and large river areas, likely due to underrepresentation in pretraining data. SHRUG-FM provides a pathway toward safer and more interpretable deployment of GFMs in climate-sensitive applications, helping bridge the gap between benchmark performance and real-world reliability.
Explicitly Representing Syntax Improves Sentence-to-layout Prediction of Unexpected Situations
Jan 25, 2024Recognizing visual entities in a natural language sentence and arranging them in a 2D spatial layout require a compositional understanding of language and space. This task of layout prediction is valuable in text-to-image synthesis as it allows localized and controlled in-painting of the image. In this comparative study it is shown that we can predict layouts from language representations that implicitly or explicitly encode sentence syntax, if the sentences mention similar entity-relationships to the ones seen during training. To test compositional understanding, we collect a test set of grammatically correct sentences and layouts describing compositions of entities and relations that unlikely have been seen during training. Performance on this test set substantially drops, showing that current models rely on correlations in the training data and have difficulties in understanding the structure of the input sentences. We propose a novel structural loss function that better enforces the syntactic structure of the input sentence and show large performance gains in the task of 2D spatial layout prediction conditioned on text. The loss has the potential to be used in other generation tasks where a tree-like structure underlies the conditioning modality. Code, trained models and the USCOCO evaluation set will be made available via github.
Implicit Temporal Reasoning for Evidence-Based Fact-Checking
Feb 24, 2023Leveraging contextual knowledge has become standard practice in automated claim verification, yet the impact of temporal reasoning has been largely overlooked. Our study demonstrates that time positively influences the claim verification process of evidence-based fact-checking. The temporal aspects and relations between claims and evidence are first established through grounding on shared timelines, which are constructed using publication dates and time expressions extracted from their text. Temporal information is then provided to RNN-based and Transformer-based classifiers before or after claim and evidence encoding. Our time-aware fact-checking models surpass base models by up to 9% Micro F1 (64.17%) and 15% Macro F1 (47.43%) on the MultiFC dataset. They also outperform prior methods that explicitly model temporal relations between evidence. Our findings show that the presence of temporal information and the manner in which timelines are constructed greatly influence how fact-checking models determine the relevance and supporting or refuting character of evidence documents.
Optimizing ship detection efficiency in SAR images
Dec 12, 2022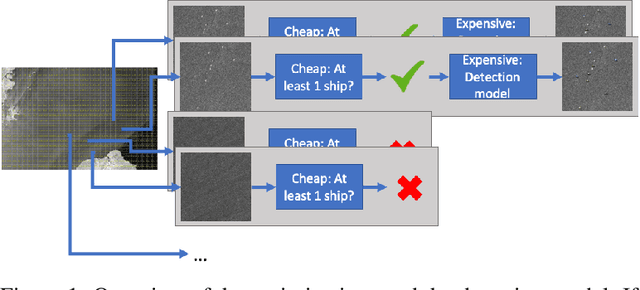



The detection and prevention of illegal fishing is critical to maintaining a healthy and functional ecosystem. Recent research on ship detection in satellite imagery has focused exclusively on performance improvements, disregarding detection efficiency. However, the speed and compute cost of vessel detection are essential for a timely intervention to prevent illegal fishing. Therefore, we investigated optimization methods that lower detection time and cost with minimal performance loss. We trained an object detection model based on a convolutional neural network (CNN) using a dataset of satellite images. Then, we designed two efficiency optimizations that can be applied to the base CNN or any other base model. The optimizations consist of a fast, cheap classification model and a statistical algorithm. The integration of the optimizations with the object detection model leads to a trade-off between speed and performance. We studied the trade-off using metrics that give different weight to execution time and performance. We show that by using a classification model the average precision of the detection model can be approximated to 99.5% in 44% of the time or to 92.7% in 25% of the time.
Discrete and continuous representations and processing in deep learning: Looking forward
Jan 04, 2022
Discrete and continuous representations of content (e.g., of language or images) have interesting properties to be explored for the understanding of or reasoning with this content by machines. This position paper puts forward our opinion on the role of discrete and continuous representations and their processing in the deep learning field. Current neural network models compute continuous-valued data. Information is compressed into dense, distributed embeddings. By stark contrast, humans use discrete symbols in their communication with language. Such symbols represent a compressed version of the world that derives its meaning from shared contextual information. Additionally, human reasoning involves symbol manipulation at a cognitive level, which facilitates abstract reasoning, the composition of knowledge and understanding, generalization and efficient learning. Motivated by these insights, in this paper we argue that combining discrete and continuous representations and their processing will be essential to build systems that exhibit a general form of intelligence. We suggest and discuss several avenues that could improve current neural networks with the inclusion of discrete elements to combine the advantages of both types of representations.
Two-phase training mitigates class imbalance for camera trap image classification with CNNs
Dec 29, 2021
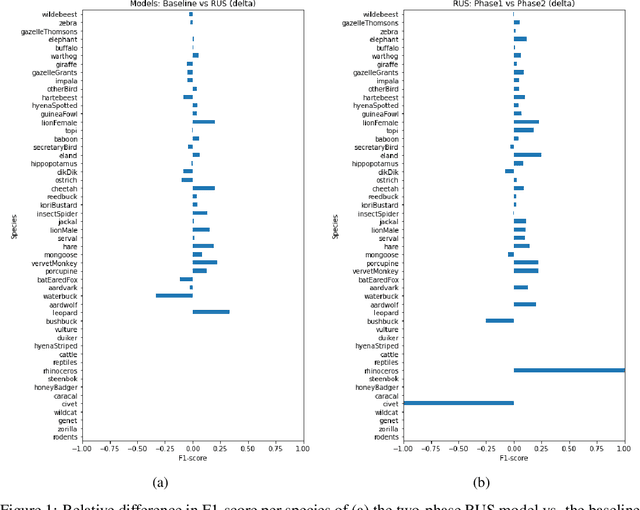


By leveraging deep learning to automatically classify camera trap images, ecologists can monitor biodiversity conservation efforts and the effects of climate change on ecosystems more efficiently. Due to the imbalanced class-distribution of camera trap datasets, current models are biased towards the majority classes. As a result, they obtain good performance for a few majority classes but poor performance for many minority classes. We used two-phase training to increase the performance for these minority classes. We trained, next to a baseline model, four models that implemented a different versions of two-phase training on a subset of the highly imbalanced Snapshot Serengeti dataset. Our results suggest that two-phase training can improve performance for many minority classes, with limited loss in performance for the other classes. We find that two-phase training based on majority undersampling increases class-specific F1-scores up to 3.0%. We also find that two-phase training outperforms using only oversampling or undersampling by 6.1% in F1-score on average. Finally, we find that a combination of over- and undersampling leads to a better performance than using them individually.
Autoregressive Reasoning over Chains of Facts with Transformers
Dec 17, 2020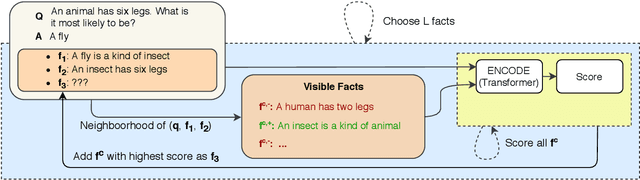



This paper proposes an iterative inference algorithm for multi-hop explanation regeneration, that retrieves relevant factual evidence in the form of text snippets, given a natural language question and its answer. Combining multiple sources of evidence or facts for multi-hop reasoning becomes increasingly hard when the number of sources needed to make an inference grows. Our algorithm copes with this by decomposing the selection of facts from a corpus autoregressively, conditioning the next iteration on previously selected facts. This allows us to use a pairwise learning-to-rank loss. We validate our method on datasets of the TextGraphs 2019 and 2020 Shared Tasks for explanation regeneration. Existing work on this task either evaluates facts in isolation or artificially limits the possible chains of facts, thus limiting multi-hop inference. We demonstrate that our algorithm, when used with a pre-trained transformer model, outperforms the previous state-of-the-art in terms of precision, training time and inference efficiency.