 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategic Navigation or Stochastic Search? How Agents and Humans Reason Over Document Collections
Mar 12, 2026Multimodal agents offer a promising path to automating complex document-intensive workflows. Yet, a critical question remains: do these agents demonstrate genuine strategic reasoning, or merely stochastic trial-and-error search? To address this, we introduce MADQA, a benchmark of 2,250 human-authored questions grounded in 800 heterogeneous PDF documents. Guided by Classical Test Theory, we design it to maximize discriminative power across varying levels of agentic abilities. To evaluate agentic behaviour, we introduce a novel evaluation protocol measuring the accuracy-effort trade-off. Using this framework, we show that while the best agents can match human searchers in raw accuracy, they succeed on largely different questions and rely on brute-force search to compensate for weak strategic planning. They fail to close the nearly 20% gap to oracle performance, persisting in unproductive loops. We release the dataset and evaluation harness to help facilitate the transition from brute-force retrieval to calibrated, efficient reasoning.
A Novel Characterization of the Population Area Under the Risk Coverage Curve (AURC) and Rates of Finite Sample Estimators
Oct 20, 2024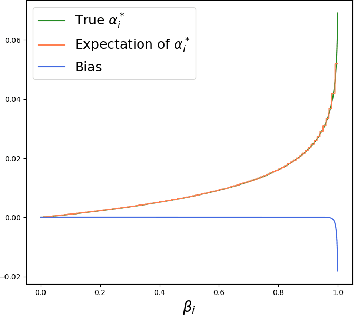
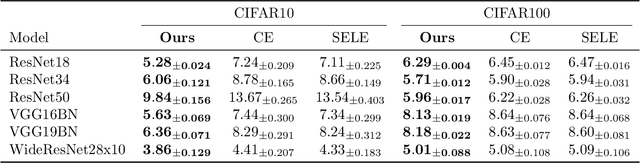
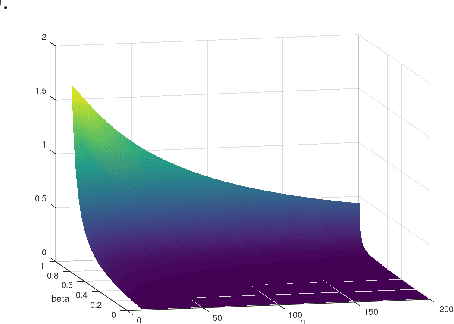
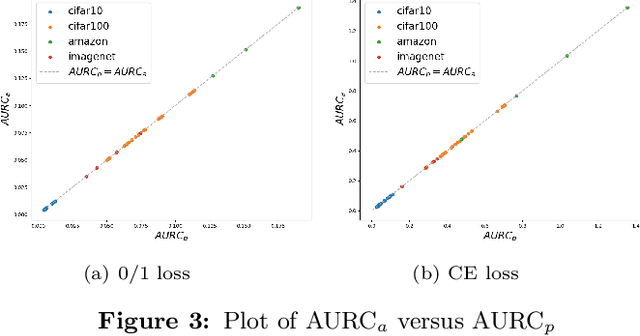
The selective classifier (SC) has garnered increasing interest in areas such as medical diagnostics, autonomous driving, and the justice system. The Area Under the Risk-Coverage Curve (AURC) has emerged as the foremost evaluation metric for assessing the performance of SC systems. In this work, we introduce a more straightforward representation of the population AURC, interpretable as a weighted risk function, and propose a Monte Carlo plug-in estimator applicable to finite sample scenarios. We demonstrate that our estimator is consistent and offers a low-bias estimation of the actual weights, with a tightly bounded mean squared error (MSE). We empirically show the effectiveness of this estimator on a comprehensive benchmark across multiple datasets, model architectures, and Confidence Score Functions (CSFs).
DistilDoc: Knowledge Distillation for Visually-Rich Document Applications
Jun 12, 2024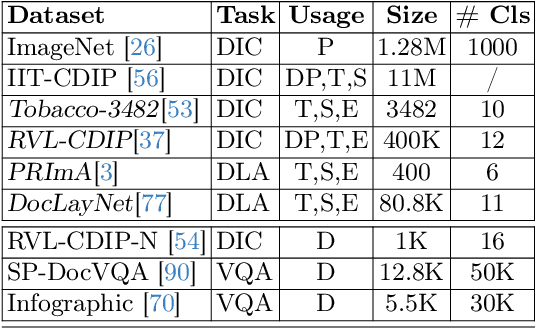
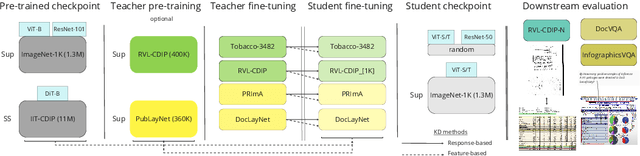
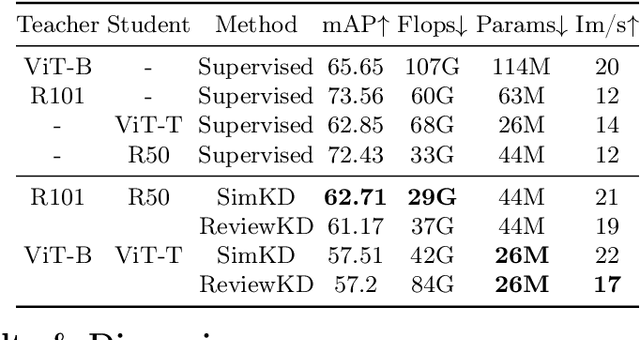
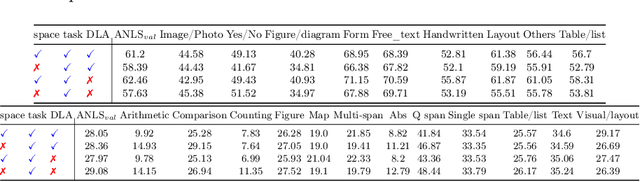
This work explores knowledge distillation (KD) for visually-rich document (VRD) applications such as document layout analysis (DLA) and document image classification (DIC). While VRD research is dependent on increasingly sophisticated and cumbersome models, the field has neglected to study efficiency via model compression. Here, we design a KD experimentation methodology for more lean, performant models on document understanding (DU) tasks that are integral within larger task pipelines. We carefully selected KD strategies (response-based, feature-based) for distilling knowledge to and from backbones with different architectures (ResNet, ViT, DiT) and capacities (base, small, tiny). We study what affects the teacher-student knowledge gap and find that some methods (tuned vanilla KD, MSE, SimKD with an apt projector) can consistently outperform supervised student training. Furthermore, we design downstream task setups to evaluate covariate shift and the robustness of distilled DLA models on zero-shot layout-aware document visual question answering (DocVQA). DLA-KD experiments result in a large mAP knowledge gap, which unpredictably translates to downstream robustness, accentuating the need to further explore how to efficiently obtain more semantic document layout awareness.
Multimodal Adaptive Inference for Document Image Classification with Anytime Early Exiting
May 21, 2024This work addresses the need for a balanced approach between performance and efficiency in scalable production environments for visually-rich document understanding (VDU) tasks. Currently, there is a reliance on large document foundation models that offer advanced capabilities but come with a heavy computational burden. In this paper, we propose a multimodal early exit (EE) model design that incorporates various training strategies, exit layer types and placements. Our goal is to achieve a Pareto-optimal balance between predictive performance and efficiency for multimodal document image classification. Through a comprehensive set of experiments, we compare our approach with traditional exit policies and showcase an improved performance-efficiency trade-off. Our multimodal EE design preserves the model's predictive capabilities, enhancing both speed and latency. This is achieved through a reduction of over 20% in latency, while fully retaining the baseline accuracy. This research represents the first exploration of multimodal EE design within the VDU community, highlighting as well the effectiveness of calibration in improving confidence scores for exiting at different layers. Overall, our findings contribute to practical VDU applications by enhancing both performance and efficiency.
Beyond Document Page Classification: Design, Datasets, and Challenges
Aug 29, 2023This paper highlights the need to bring document classification benchmarking closer to real-world applications, both in the nature of data tested ($X$: multi-channel, multi-paged, multi-industry; $Y$: class distributions and label set variety) and in classification tasks considered ($f$: multi-page document, page stream, and document bundle classification, ...). We identify the lack of public multi-page document classification datasets, formalize different classification tasks arising in application scenarios, and motivate the value of targeting efficient multi-page document representations. An experimental study on proposed multi-page document classification datasets demonstrates that current benchmarks have become irrelevant and need to be updated to evaluate complete documents, as they naturally occur in practice. This reality check also calls for more mature evaluation methodologies, covering calibration evaluation, inference complexity (time-memory), and a range of realistic distribution shifts (e.g., born-digital vs. scanning noise, shifting page order). Our study ends on a hopeful note by recommending concrete avenues for future improvements.}
Optimizing ship detection efficiency in SAR images
Dec 12, 2022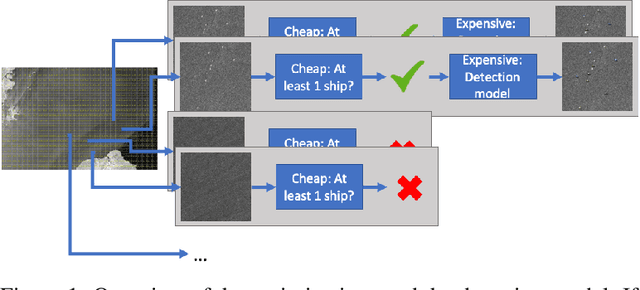



The detection and prevention of illegal fishing is critical to maintaining a healthy and functional ecosystem. Recent research on ship detection in satellite imagery has focused exclusively on performance improvements, disregarding detection efficiency. However, the speed and compute cost of vessel detection are essential for a timely intervention to prevent illegal fishing. Therefore, we investigated optimization methods that lower detection time and cost with minimal performance loss. We trained an object detection model based on a convolutional neural network (CNN) using a dataset of satellite images. Then, we designed two efficiency optimizations that can be applied to the base CNN or any other base model. The optimizations consist of a fast, cheap classification model and a statistical algorithm. The integration of the optimizations with the object detection model leads to a trade-off between speed and performance. We studied the trade-off using metrics that give different weight to execution time and performance. We show that by using a classification model the average precision of the detection model can be approximated to 99.5% in 44% of the time or to 92.7% in 25% of the time.