 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-phase training mitigates class imbalance for camera trap image classification with CNNs
Dec 29, 2021
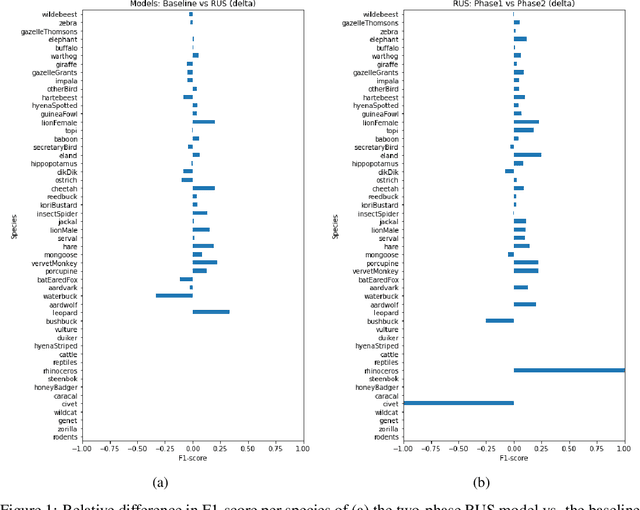


By leveraging deep learning to automatically classify camera trap images, ecologists can monitor biodiversity conservation efforts and the effects of climate change on ecosystems more efficiently. Due to the imbalanced class-distribution of camera trap datasets, current models are biased towards the majority classes. As a result, they obtain good performance for a few majority classes but poor performance for many minority classes. We used two-phase training to increase the performance for these minority classes. We trained, next to a baseline model, four models that implemented a different versions of two-phase training on a subset of the highly imbalanced Snapshot Serengeti dataset. Our results suggest that two-phase training can improve performance for many minority classes, with limited loss in performance for the other classes. We find that two-phase training based on majority undersampling increases class-specific F1-scores up to 3.0%. We also find that two-phase training outperforms using only oversampling or undersampling by 6.1% in F1-score on average. Finally, we find that a combination of over- and undersampling leads to a better performance than using them individually.
LIIR at SemEval-2021 task 6: Detection of Persuasion Techniques In Texts and Images using CLIP features
May 31, 2021

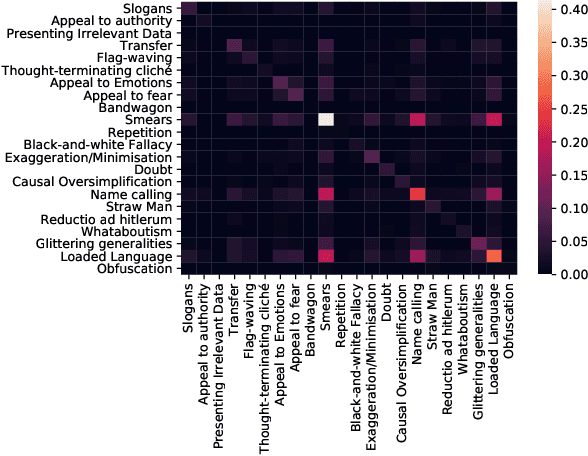

We describe our approach for SemEval-2021 task 6 on detection of persuasion techniques in multimodal content (memes). Our system combines pretrained multimodal models (CLIP) and chained classifiers. Also, we propose to enrich the data by a data augmentation technique. Our submission achieves a rank of 8/16 in terms of F1-micro and 9/16 with F1-macro on the test set.
LIIR at SemEval-2020 Task 12: A Cross-Lingual Augmentation Approach for Multilingual Offensive Language Identification
May 07, 2020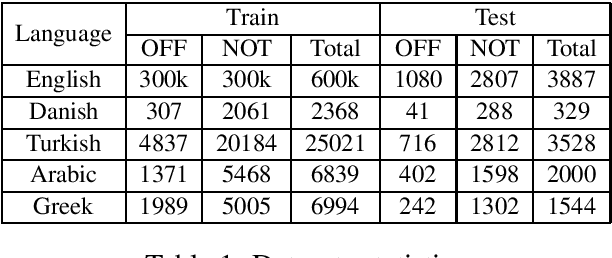

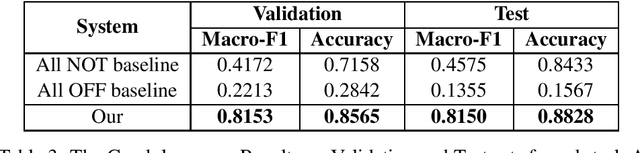

This paper presents our system entitled `LIIR' for SemEval-2020 Task 12 on Multilingual Offensive Language Identification in Social Media (OffensEval 2). We have participated in sub-task A for English, Danish, Greek, Arabic, and Turkish languages. We adapt and fine-tune the BERT and Multilingual Bert models made available by Google AI for English and non-English languages respectively. For the English language, we use a combination of two fine-tuned BERT models. For other languages we propose a cross-lingual augmentation approach in order to enrich training data and we use Multilingual BERT to obtain sentence representations. LIIR achieved rank 14/38, 18/47, 24/86, 24/54, and 25/40 in Greek, Turkish, English, Arabic, and Danish languages, respectively.
Aspect Category Detection via Topic-Attention Network
Jan 04, 2019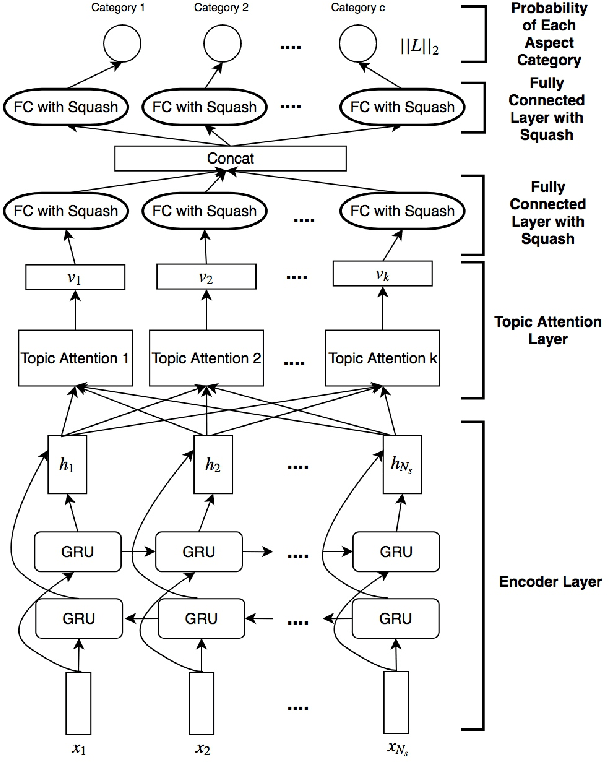
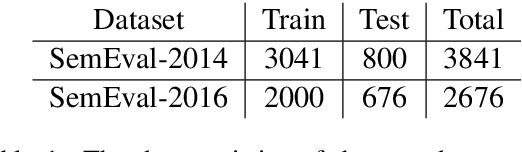
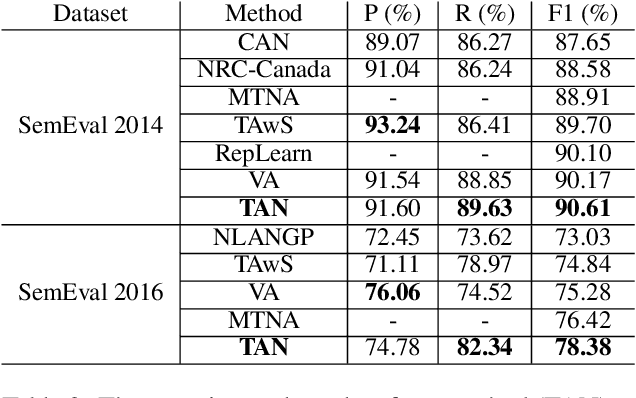
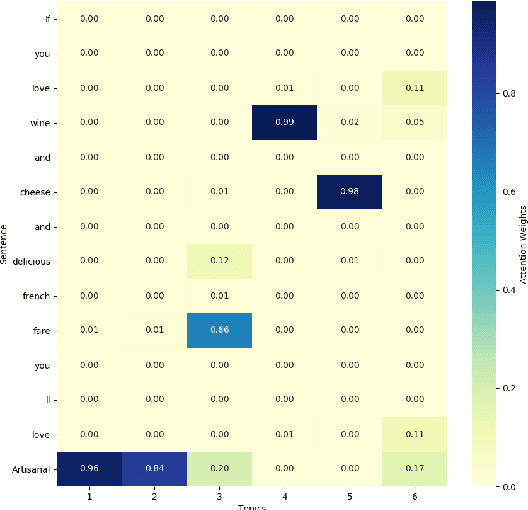
The e-commerce has started a new trend in natural language processing through sentiment analysis of user-generated reviews. Different consumers have different concerns about various aspects of a specific product or service. Aspect category detection, as a subtask of aspect-based sentiment analysis, tackles the problem of categorizing a given review sentence into a set of pre-defined aspect categories. In recent years, deep learning approaches have brought revolutionary advances in multiple branches of natural language processing including sentiment analysis. In this paper, we propose a deep neural network method based on attention mechanism to identify different aspect categories of a given review sentence. Our model utilizes several attentions with different topic contexts, enabling it to attend to different parts of a review sentence based on different topics. Experimental results on two datasets in the restaurant domain released by SemEval workshop demonstrates that our approach outperforms existing methods on both datasets. Visualization of the topic attention weights shows the effectiveness of our model in identifying words related to different topics.
An Unsupervised Approach for Aspect Category Detection Using Soft Cosine Similarity Measure
Dec 08, 2018
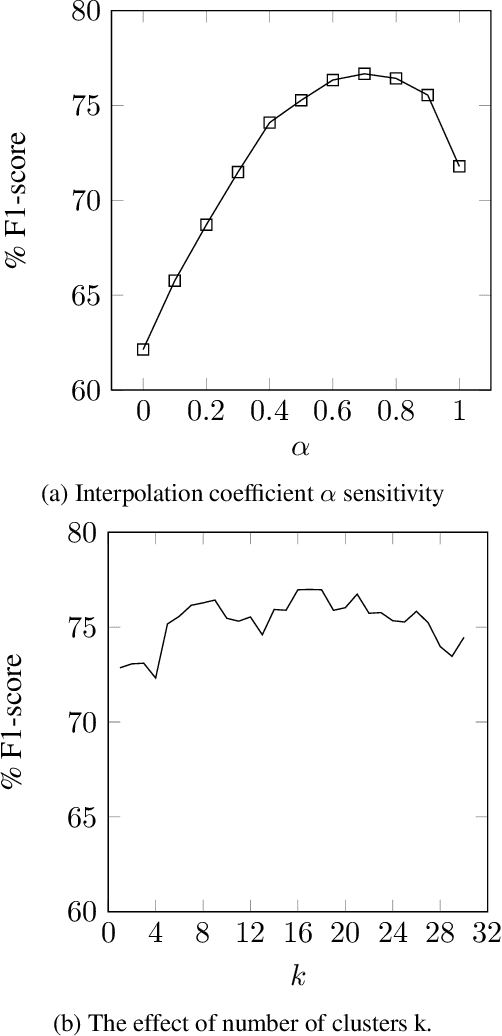
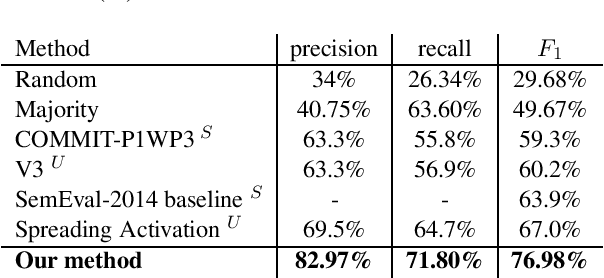
Aspect category detection is one of the important and challenging subtasks of aspect-based sentiment analysis. Given a set of pre-defined categories, this task aims to detect categories which are indicated implicitly or explicitly in a given review sentence. Supervised machine learning approaches perform well to accomplish this subtask. Note that, the performance of these methods depends on the availability of labeled train data, which is often difficult and costly to obtain. Besides, most of these supervised methods require feature engineering to perform well. In this paper, we propose an unsupervised method to address aspect category detection task without the need for any feature engineering. Our method utilizes clusters of unlabeled reviews and soft cosine similarity measure to accomplish aspect category detection task. Experimental results on SemEval-2014 restaurant dataset shows that proposed unsupervised approach outperforms several baselines by a substantial margin.