 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Task GRPO: Reliable LLM Reasoning Across Tasks
Feb 05, 2026RL-based post-training with GRPO is widely used to improve large language models on individual reasoning tasks. However, real-world deployment requires reliable performance across diverse tasks. A straightforward multi-task adaptation of GRPO often leads to imbalanced outcomes, with some tasks dominating optimization while others stagnate. Moreover, tasks can vary widely in how frequently prompts yield zero advantages (and thus zero gradients), which further distorts their effective contribution to the optimization signal. To address these issues, we propose a novel Multi-Task GRPO (MT-GRPO) algorithm that (i) dynamically adapts task weights to explicitly optimize worst-task performance and promote balanced progress across tasks, and (ii) introduces a ratio-preserving sampler to ensure task-wise policy gradients reflect the adapted weights. Experiments on both 3-task and 9-task settings show that MT-GRPO consistently outperforms baselines in worst-task accuracy. In particular, MT-GRPO achieves 16-28% and 6% absolute improvement on worst-task performance over standard GRPO and DAPO, respectively, while maintaining competitive average accuracy. Moreover, MT-GRPO requires 50% fewer training steps to reach 50% worst-task accuracy in the 3-task setting, demonstrating substantially improved efficiency in achieving reliable performance across tasks.
Enhancing Optimizer Stability: Momentum Adaptation of The NGN Step-size
Aug 20, 2025Modern optimization algorithms that incorporate momentum and adaptive step-size offer improved performance in numerous challenging deep learning tasks. However, their effectiveness is often highly sensitive to the choice of hyperparameters, especially the step-size. Tuning these parameters is often difficult, resource-intensive, and time-consuming. Therefore, recent efforts have been directed toward enhancing the stability of optimizers across a wide range of hyperparameter choices [Schaipp et al., 2024]. In this paper, we introduce an algorithm that matches the performance of state-of-the-art optimizers while improving stability to the choice of the step-size hyperparameter through a novel adaptation of the NGN step-size method [Orvieto and Xiao, 2024]. Specifically, we propose a momentum-based version (NGN-M) that attains the standard convergence rate of $\mathcal{O}(1/\sqrt{K})$ under less restrictive assumptions, without the need for interpolation condition or assumptions of bounded stochastic gradients or iterates, in contrast to previous approaches. Additionally, we empirically demonstrate that the combination of the NGN step-size with momentum results in enhanced robustness to the choice of the step-size hyperparameter while delivering performance that is comparable to or surpasses other state-of-the-art optimizers.
Optimization Guarantees for Square-Root Natural-Gradient Variational Inference
Jul 10, 2025Variational inference with natural-gradient descent often shows fast convergence in practice, but its theoretical convergence guarantees have been challenging to establish. This is true even for the simplest cases that involve concave log-likelihoods and use a Gaussian approximation. We show that the challenge can be circumvented for such cases using a square-root parameterization for the Gaussian covariance. This approach establishes novel convergence guarantees for natural-gradient variational-Gaussian inference and its continuous-time gradient flow. Our experiments demonstrate the effectiveness of natural gradient methods and highlight their advantages over algorithms that use Euclidean or Wasserstein geometries.
Trainability of Quantum Models Beyond Known Classical Simulability
Jul 08, 2025Variational Quantum Algorithms (VQAs) are promising candidates for near-term quantum computing, yet they face scalability challenges due to barren plateaus, where gradients vanish exponentially in the system size. Recent conjectures suggest that avoiding barren plateaus might inherently lead to classical simulability, thus limiting the opportunities for quantum advantage. In this work, we advance the theoretical understanding of the relationship between the trainability and computational complexity of VQAs, thus directly addressing the conjecture. We introduce the Linear Clifford Encoder (LCE), a novel technique that ensures constant-scaling gradient statistics on optimization landscape regions that are close to Clifford circuits. Additionally, we leverage classical Taylor surrogates to reveal computational complexity phase transitions from polynomial to super-polynomial as the initialization region size increases. Combining these results, we reveal a deeper link between trainability and computational complexity, and analytically prove that barren plateaus can be avoided in regions for which no classical surrogate is known to exist. Furthermore, numerical experiments on LCE transformed landscapes confirm in practice the existence of a super-polynomially complex ``transition zone'' where gradients decay polynomially. These findings indicate a plausible path to practically relevant, barren plateau-free variational models with potential for quantum advantage.
Sharp Generalization Bounds for Foundation Models with Asymmetric Randomized Low-Rank Adapters
Jun 17, 2025Low-Rank Adaptation (LoRA) has emerged as a widely adopted parameter-efficient fine-tuning (PEFT) technique for foundation models. Recent work has highlighted an inherent asymmetry in the initialization of LoRA's low-rank factors, which has been present since its inception and was presumably derived experimentally. This paper focuses on providing a comprehensive theoretical characterization of asymmetric LoRA with frozen random factors. First, while existing research provides upper-bound generalization guarantees based on averages over multiple experiments, the behaviour of a single fine-tuning run with specific random factors remains an open question. We address this by investigating the concentration of the typical LoRA generalization gap around its mean. Our main upper bound reveals a sample complexity of $\tilde{\mathcal{O}}\left(\frac{\sqrt{r}}{\sqrt{N}}\right)$ with high probability for rank $r$ LoRAs trained on $N$ samples. Additionally, we also determine the fundamental limits in terms of sample efficiency, establishing a matching lower bound of $\mathcal{O}\left(\frac{1}{\sqrt{N}}\right)$. By more closely reflecting the practical scenario of a single fine-tuning run, our findings offer crucial insights into the reliability and practicality of asymmetric LoRA.
When the Left Foot Leads to the Right Path: Bridging Initial Prejudice and Trainability
May 17, 2025Understanding the statistical properties of deep neural networks (DNNs) at initialization is crucial for elucidating both their trainability and the intrinsic architectural biases they encode prior to data exposure. Mean-field (MF) analyses have demonstrated that the parameter distribution in randomly initialized networks dictates whether gradients vanish or explode. Concurrently, untrained DNNs were found to exhibit an initial-guessing bias (IGB), in which large regions of the input space are assigned to a single class. In this work, we derive a theoretical proof establishing the correspondence between IGB and previous MF theories, thereby connecting a network prejudice toward specific classes with the conditions for fast and accurate learning. This connection yields the counter-intuitive conclusion: the initialization that optimizes trainability is necessarily biased, rather than neutral. Furthermore, we extend the MF/IGB framework to multi-node activation functions, offering practical guidelines for designing initialization schemes that ensure stable optimization in architectures employing max- and average-pooling layers.
Where You Place the Norm Matters: From Prejudiced to Neutral Initializations
May 16, 2025Normalization layers, such as Batch Normalization and Layer Normalization, are central components in modern neural networks, widely adopted to improve training stability and generalization. While their practical effectiveness is well documented, a detailed theoretical understanding of how normalization affects model behavior, starting from initialization, remains an important open question. In this work, we investigate how both the presence and placement of normalization within hidden layers influence the statistical properties of network predictions before training begins. In particular, we study how these choices shape the distribution of class predictions at initialization, which can range from unbiased (Neutral) to highly concentrated (Prejudiced) toward a subset of classes. Our analysis shows that normalization placement induces systematic differences in the initial prediction behavior of neural networks, which in turn shape the dynamics of learning. By linking architectural choices to prediction statistics at initialization, our work provides a principled understanding of how normalization can influence early training behavior and offers guidance for more controlled and interpretable network design.
Unbiased and Sign Compression in Distributed Learning: Comparing Noise Resilience via SDEs
Feb 24, 2025Distributed methods are essential for handling machine learning pipelines comprising large-scale models and datasets. However, their benefits often come at the cost of increased communication overhead between the central server and agents, which can become the main bottleneck, making training costly or even unfeasible in such systems. Compression methods such as quantization and sparsification can alleviate this issue. Still, their robustness to large and heavy-tailed gradient noise, a phenomenon sometimes observed in language modeling, remains poorly understood. This work addresses this gap by analyzing Distributed Compressed SGD (DCSGD) and Distributed SignSGD (DSignSGD) using stochastic differential equations (SDEs). Our results show that DCSGD with unbiased compression is more vulnerable to noise in stochastic gradients, while DSignSGD remains robust, even under large and heavy-tailed noise. Additionally, we propose new scaling rules for hyperparameter tuning to mitigate performance degradation due to compression. These findings are empirically validated across multiple deep learning architectures and datasets, providing practical recommendations for distributed optimization.
Double Momentum and Error Feedback for Clipping with Fast Rates and Differential Privacy
Feb 17, 2025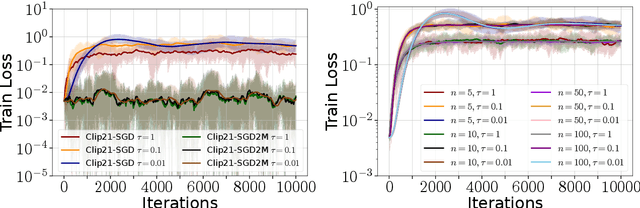
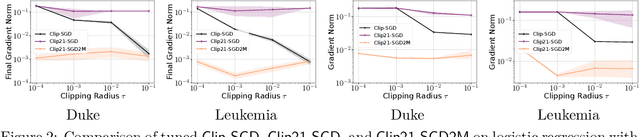


Strong Differential Privacy (DP) and Optimization guarantees are two desirable properties for a method in Federated Learning (FL). However, existing algorithms do not achieve both properties at once: they either have optimal DP guarantees but rely on restrictive assumptions such as bounded gradients/bounded data heterogeneity, or they ensure strong optimization performance but lack DP guarantees. To address this gap in the literature, we propose and analyze a new method called Clip21-SGD2M based on a novel combination of clipping, heavy-ball momentum, and Error Feedback. In particular, for non-convex smooth distributed problems with clients having arbitrarily heterogeneous data, we prove that Clip21-SGD2M has optimal convergence rate and also near optimal (local-)DP neighborhood. Our numerical experiments on non-convex logistic regression and training of neural networks highlight the superiority of Clip21-SGD2M over baselines in terms of the optimization performance for a given DP-budget.
Adaptive Methods through the Lens of SDEs: Theoretical Insights on the Role of Noise
Nov 24, 2024Despite the vast empirical evidence supporting the efficacy of adaptive optimization methods in deep learning, their theoretical understanding is far from complete. This work introduces novel SDEs for commonly used adaptive optimizers: SignSGD, RMSprop(W), and Adam(W). These SDEs offer a quantitatively accurate description of these optimizers and help illuminate an intricate relationship between adaptivity, gradient noise, and curvature. Our novel analysis of SignSGD highlights a noteworthy and precise contrast to SGD in terms of convergence speed, stationary distribution, and robustness to heavy-tail noise. We extend this analysis to AdamW and RMSpropW, for which we observe that the role of noise is much more complex. Crucially, we support our theoretical analysis with experimental evidence by verifying our insights: this includes numerically integrating our SDEs using Euler-Maruyama discretization on various neural network architectures such as MLPs, CNNs, ResNets, and Transformers. Our SDEs accurately track the behavior of the respective optimizers, especially when compared to previous SDEs derived for Adam and RMSprop. We believe our approach can provide valuable insights into best training practices and novel scaling rules.