 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeriving Hyperparameter Scaling Laws via Modern Optimization Theory
Mar 16, 2026Hyperparameter transfer has become an important component of modern large-scale training recipes. Existing methods, such as muP, primarily focus on transfer between model sizes, with transfer across batch sizes and training horizons often relying on empirical scaling rules informed by insights from timescale preservation, quadratic proxies, and continuous-time approximations. We study hyperparameter scaling laws for modern first-order optimizers through the lens of recent convergence bounds for methods based on the Linear Minimization Oracle (LMO), a framework that includes normalized SGD, signSGD (approximating Adam), and Muon. Treating bounds in recent literature as a proxy and minimizing them across different tuning regimes yields closed-form power-law schedules for learning rate, momentum, and batch size as functions of the iteration or token budget. Our analysis, holding model size fixed, recovers most insights and observations from the literature under a unified and principled perspective, with clear directions open for future research. Our results draw particular attention to the interaction between momentum and batch-size scaling, suggesting that optimal performance may be achieved with several scaling strategies.
Open-sci-ref-0.01: open and reproducible reference baselines for language model and dataset comparison
Sep 10, 2025We introduce open-sci-ref, a family of dense transformer models trained as research baselines across multiple model (0.13B to 1.7B parameters) and token scales (up to 1T) on 8 recent open reference datasets. Evaluating the models on various standardized benchmarks, our training runs set establishes reference points that enable researchers to assess the sanity and quality of alternative training approaches across scales and datasets. Intermediate checkpoints allow comparison and studying of the training dynamics. The established reference baselines allow training procedures to be compared through their scaling trends, aligning them on a common compute axis. Comparison of open reference datasets reveals that training on NemoTron-CC HQ consistently outperforms other reference datasets, followed by DCLM-baseline and FineWeb-Edu. In addition to intermediate training checkpoints, the release includes logs, code, and downstream evaluations to simplify reproduction, standardize comparison, and facilitate future research.
Can you Finetune your Binoculars? Embedding Text Watermarks into the Weights of Large Language Models
Apr 08, 2025



The indistinguishability of AI-generated content from human text raises challenges in transparency and accountability. While several methods exist to watermark models behind APIs, embedding watermark strategies directly into model weights that are later reflected in the outputs of the model is challenging. In this study we propose a strategy to finetune a pair of low-rank adapters of a model, one serving as the text-generating model, and the other as the detector, so that a subtle watermark is embedded into the text generated by the first model and simultaneously optimized for detectability by the second. In this way, the watermarking strategy is fully learned end-to-end. This process imposes an optimization challenge, as balancing watermark robustness, naturalness, and task performance requires trade-offs. We discuss strategies on how to optimize this min-max objective and present results showing the effect of this modification to instruction finetuning.
When, Where and Why to Average Weights?
Feb 10, 2025
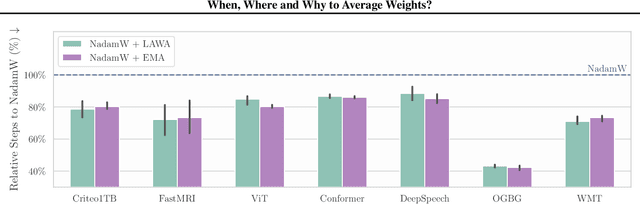


Averaging checkpoints along the training trajectory is a simple yet powerful approach to improve the generalization performance of Machine Learning models and reduce training time. Motivated by these potential gains, and in an effort to fairly and thoroughly benchmark this technique, we present an extensive evaluation of averaging techniques in modern Deep Learning, which we perform using AlgoPerf \citep{dahl_benchmarking_2023}, a large-scale benchmark for optimization algorithms. We investigate whether weight averaging can reduce training time, improve generalization, and replace learning rate decay, as suggested by recent literature. Our evaluation across seven architectures and datasets reveals that averaging significantly accelerates training and yields considerable efficiency gains, at the price of a minimal implementation and memory cost, while mildly improving generalization across all considered workloads. Finally, we explore the relationship between averaging and learning rate annealing and show how to optimally combine the two to achieve the best performances.
Loss Landscape Characterization of Neural Networks without Over-Parametrization
Oct 17, 2024
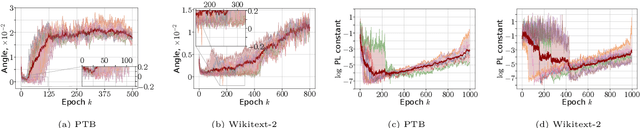

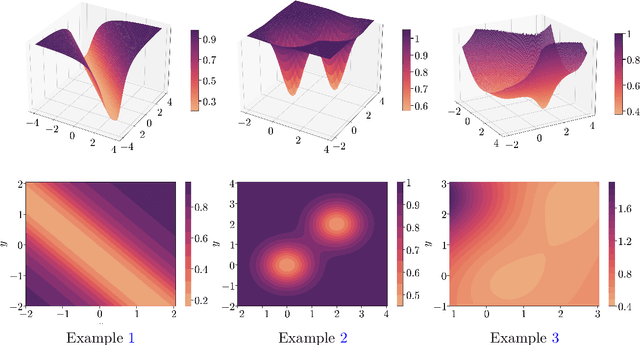
Optimization methods play a crucial role in modern machine learning, powering the remarkable empirical achievements of deep learning models. These successes are even more remarkable given the complex non-convex nature of the loss landscape of these models. Yet, ensuring the convergence of optimization methods requires specific structural conditions on the objective function that are rarely satisfied in practice. One prominent example is the widely recognized Polyak-Lojasiewicz (PL) inequality, which has gained considerable attention in recent years. However, validating such assumptions for deep neural networks entails substantial and often impractical levels of over-parametrization. In order to address this limitation, we propose a novel class of functions that can characterize the loss landscape of modern deep models without requiring extensive over-parametrization and can also include saddle points. Crucially, we prove that gradient-based optimizers possess theoretical guarantees of convergence under this assumption. Finally, we validate the soundness of our new function class through both theoretical analysis and empirical experimentation across a diverse range of deep learning models.
Conformal Prediction Bands for Two-Dimensional Functional Time Series
Jul 27, 2022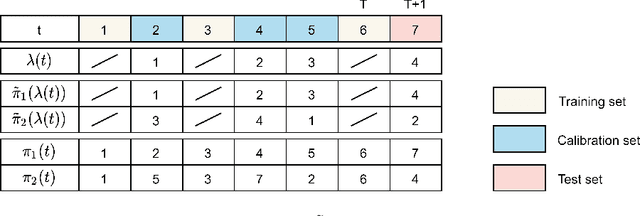
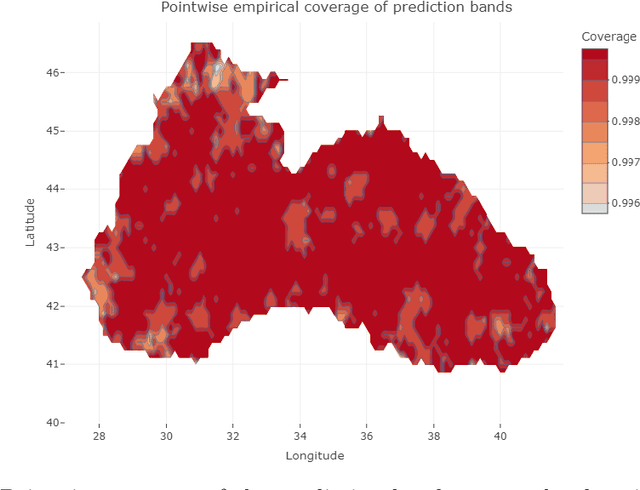
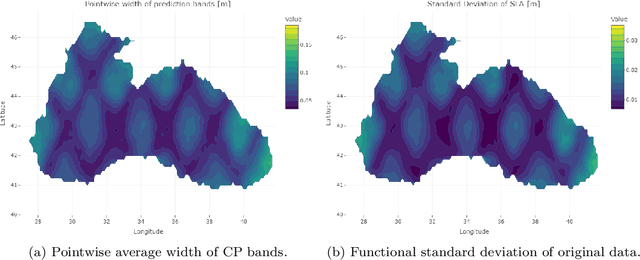
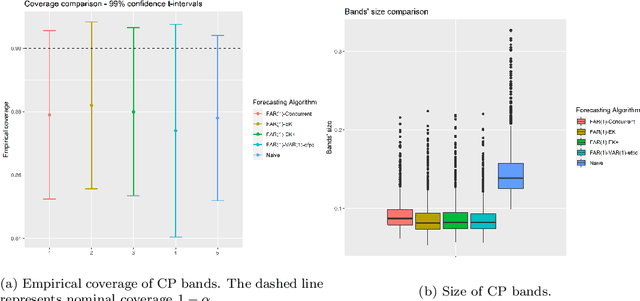
Conformal Prediction (CP) is a versatile nonparametric framework used to quantify uncertainty in prediction problems. In this work, we provide an extension of such method to the case of time series of functions defined on a bivariate domain, by proposing for the first time a distribution-free technique which can be applied to time-evolving surfaces. In order to obtain meaningful and efficient prediction regions, CP must be coupled with an accurate forecasting algorithm, for this reason, we extend the theory of autoregressive processes in Hilbert space in order to allow for functions with a bivariate domain. Given the novelty of the subject, we present estimation techniques for the Functional Autoregressive model (FAR). A simulation study is implemented, in order to investigate how different point predictors affect the resulting prediction bands. Finally, we explore benefits and limits of the proposed approach on a real dataset, collecting daily observations of Sea Level Anomalies of the Black Sea in the last twenty years.