 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-sci-ref-0.01: open and reproducible reference baselines for language model and dataset comparison
Sep 10, 2025We introduce open-sci-ref, a family of dense transformer models trained as research baselines across multiple model (0.13B to 1.7B parameters) and token scales (up to 1T) on 8 recent open reference datasets. Evaluating the models on various standardized benchmarks, our training runs set establishes reference points that enable researchers to assess the sanity and quality of alternative training approaches across scales and datasets. Intermediate checkpoints allow comparison and studying of the training dynamics. The established reference baselines allow training procedures to be compared through their scaling trends, aligning them on a common compute axis. Comparison of open reference datasets reveals that training on NemoTron-CC HQ consistently outperforms other reference datasets, followed by DCLM-baseline and FineWeb-Edu. In addition to intermediate training checkpoints, the release includes logs, code, and downstream evaluations to simplify reproduction, standardize comparison, and facilitate future research.
An Expanded Massive Multilingual Dataset for High-Performance Language Technologies
Mar 13, 2025Training state-of-the-art large language models requires vast amounts of clean and diverse textual data. However, building suitable multilingual datasets remains a challenge. In this work, we present HPLT v2, a collection of high-quality multilingual monolingual and parallel corpora. The monolingual portion of the data contains 8T tokens covering 193 languages, while the parallel data contains 380M sentence pairs covering 51 languages. We document the entire data pipeline and release the code to reproduce it. We provide extensive analysis of the quality and characteristics of our data. Finally, we evaluate the performance of language models and machine translation systems trained on HPLT v2, demonstrating its value.
Got Compute, but No Data: Lessons From Post-training a Finnish LLM
Mar 12, 2025As LLMs gain more popularity as chatbots and general assistants, methods have been developed to enable LLMs to follow instructions and align with human preferences. These methods have found success in the field, but their effectiveness has not been demonstrated outside of high-resource languages. In this work, we discuss our experiences in post-training an LLM for instruction-following for English and Finnish. We use a multilingual LLM to translate instruction and preference datasets from English to Finnish. We perform instruction tuning and preference optimization in English and Finnish and evaluate the instruction-following capabilities of the model in both languages. Our results show that with a few hundred Finnish instruction samples we can obtain competitive performance in Finnish instruction-following. We also found that although preference optimization in English offers some cross-lingual benefits, we obtain our best results by using preference data from both languages. We release our model, datasets, and recipes under open licenses at https://huggingface.co/LumiOpen/Poro-34B-chat-OpenAssistant
* 7 pages
Poro 34B and the Blessing of Multilinguality
Apr 02, 2024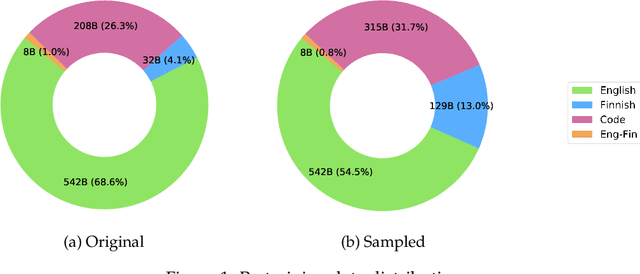

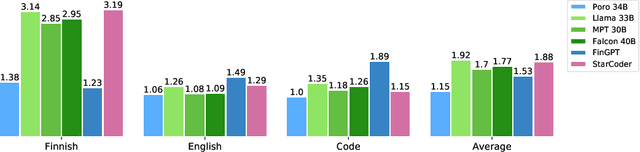

The pretraining of state-of-the-art large language models now requires trillions of words of text, which is orders of magnitude more than available for the vast majority of languages. While including text in more than one language is an obvious way to acquire more pretraining data, multilinguality is often seen as a curse, and most model training efforts continue to focus near-exclusively on individual large languages. We believe that multilinguality can be a blessing and that it should be possible to substantially improve over the capabilities of monolingual models for small languages through multilingual training. In this study, we introduce Poro 34B, a 34 billion parameter model trained for 1 trillion tokens of Finnish, English, and programming languages, and demonstrate that a multilingual training approach can produce a model that not only substantially advances over the capabilities of existing models for Finnish, but also excels in translation and is competitive in its class in generating English and programming languages. We release the model parameters, scripts, and data under open licenses at https://huggingface.co/LumiOpen/Poro-34B.
FinGPT: Large Generative Models for a Small Language
Nov 03, 2023



Large language models (LLMs) excel in many tasks in NLP and beyond, but most open models have very limited coverage of smaller languages and LLM work tends to focus on languages where nearly unlimited data is available for pretraining. In this work, we study the challenges of creating LLMs for Finnish, a language spoken by less than 0.1% of the world population. We compile an extensive dataset of Finnish combining web crawls, news, social media and eBooks. We pursue two approaches to pretrain models: 1) we train seven monolingual models from scratch (186M to 13B parameters) dubbed FinGPT, 2) we continue the pretraining of the multilingual BLOOM model on a mix of its original training data and Finnish, resulting in a 176 billion parameter model we call BLUUMI. For model evaluation, we introduce FIN-bench, a version of BIG-bench with Finnish tasks. We also assess other model qualities such as toxicity and bias. Our models and tools are openly available at https://turkunlp.org/gpt3-finnish.