 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinGPT: Large Generative Models for a Small Language
Nov 03, 2023



Large language models (LLMs) excel in many tasks in NLP and beyond, but most open models have very limited coverage of smaller languages and LLM work tends to focus on languages where nearly unlimited data is available for pretraining. In this work, we study the challenges of creating LLMs for Finnish, a language spoken by less than 0.1% of the world population. We compile an extensive dataset of Finnish combining web crawls, news, social media and eBooks. We pursue two approaches to pretrain models: 1) we train seven monolingual models from scratch (186M to 13B parameters) dubbed FinGPT, 2) we continue the pretraining of the multilingual BLOOM model on a mix of its original training data and Finnish, resulting in a 176 billion parameter model we call BLUUMI. For model evaluation, we introduce FIN-bench, a version of BIG-bench with Finnish tasks. We also assess other model qualities such as toxicity and bias. Our models and tools are openly available at https://turkunlp.org/gpt3-finnish.
Exploring Cross-sentence Contexts for Named Entity Recognition with BERT
Jun 02, 2020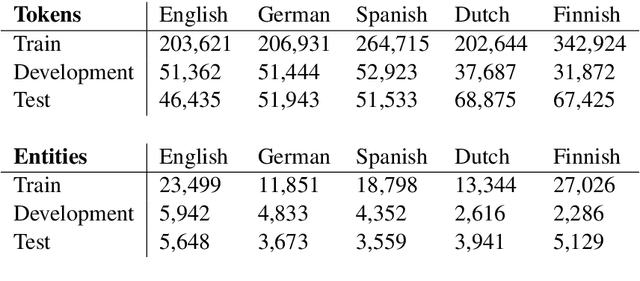



Named entity recognition (NER) is frequently addressed as a sequence classification task where each input consists of one sentence of text. It is nevertheless clear that useful information for the task can often be found outside of the scope of a single-sentence context. Recently proposed self-attention models such as BERT can both efficiently capture long-distance relationships in input as well as represent inputs consisting of several sentences, creating new opportunitites for approaches that incorporate cross-sentence information in natural language processing tasks. In this paper, we present a systematic study exploring the use of cross-sentence information for NER using BERT models in five languages. We find that adding context in the form of additional sentences to BERT input systematically increases NER performance on all of the tested languages and models. Including multiple sentences in each input also allows us to study the predictions of the same sentences in different contexts. We propose a straightforward method, Contextual Majority Voting (CMV), to combine different predictions for sentences and demonstrate this to further increase NER performance with BERT. Our approach does not require any changes to the underlying BERT architecture, rather relying on restructuring examples for training and prediction. Evaluation on established datasets, including the CoNLL'02 and CoNLL'03 NER benchmarks, demonstrates that our proposed approach can improve on the state-of-the-art NER results on English, Dutch, and Finnish, achieves the best reported BERT-based results on German, and is on par with performance reported with other BERT-based approaches in Spanish. We release all methods implemented in this work under open licenses.
Multilingual is not enough: BERT for Finnish
Dec 15, 2019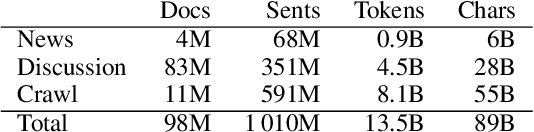
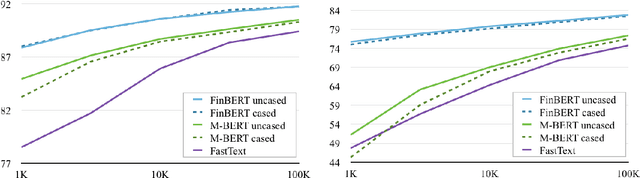
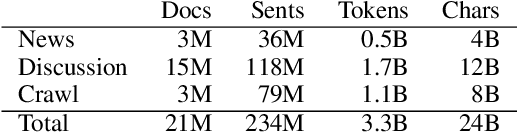
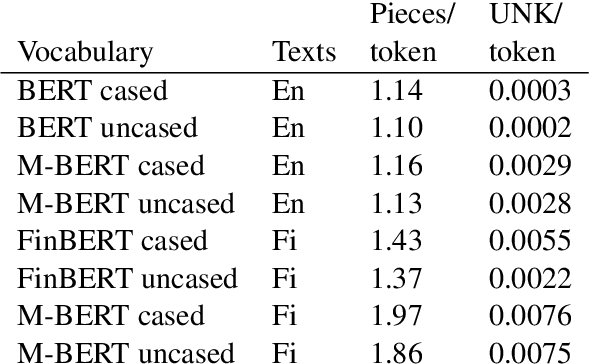
Deep learning-based language models pretrained on large unannotated text corpora have been demonstrated to allow efficient transfer learning for natural language processing, with recent approaches such as the transformer-based BERT model advancing the state of the art across a variety of tasks. While most work on these models has focused on high-resource languages, in particular English, a number of recent efforts have introduced multilingual models that can be fine-tuned to address tasks in a large number of different languages. However, we still lack a thorough understanding of the capabilities of these models, in particular for lower-resourced languages. In this paper, we focus on Finnish and thoroughly evaluate the multilingual BERT model on a range of tasks, comparing it with a new Finnish BERT model trained from scratch. The new language-specific model is shown to systematically and clearly outperform the multilingual. While the multilingual model largely fails to reach the performance of previously proposed methods, the custom Finnish BERT model establishes new state-of-the-art results on all corpora for all reference tasks: part-of-speech tagging, named entity recognition, and dependency parsing. We release the model and all related resources created for this study with open licenses at https://turkunlp.org/finbert .