 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual is not enough: BERT for Finnish
Dec 15, 2019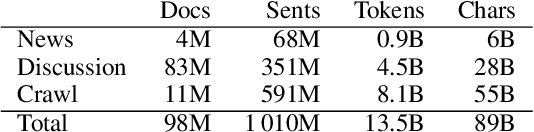
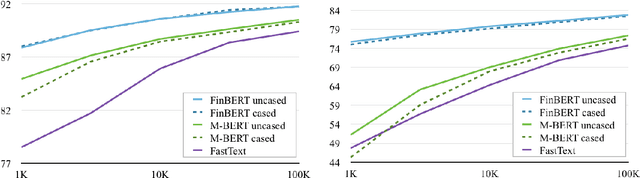
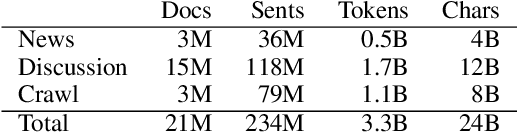
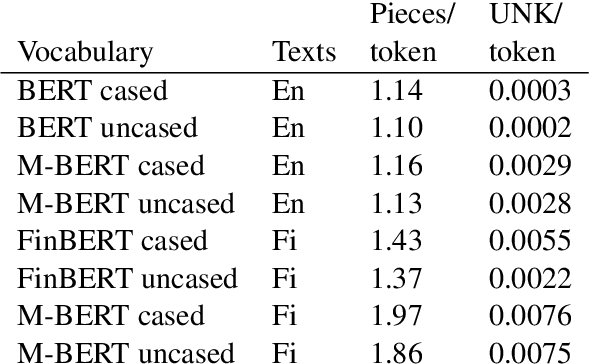
Deep learning-based language models pretrained on large unannotated text corpora have been demonstrated to allow efficient transfer learning for natural language processing, with recent approaches such as the transformer-based BERT model advancing the state of the art across a variety of tasks. While most work on these models has focused on high-resource languages, in particular English, a number of recent efforts have introduced multilingual models that can be fine-tuned to address tasks in a large number of different languages. However, we still lack a thorough understanding of the capabilities of these models, in particular for lower-resourced languages. In this paper, we focus on Finnish and thoroughly evaluate the multilingual BERT model on a range of tasks, comparing it with a new Finnish BERT model trained from scratch. The new language-specific model is shown to systematically and clearly outperform the multilingual. While the multilingual model largely fails to reach the performance of previously proposed methods, the custom Finnish BERT model establishes new state-of-the-art results on all corpora for all reference tasks: part-of-speech tagging, named entity recognition, and dependency parsing. We release the model and all related resources created for this study with open licenses at https://turkunlp.org/finbert .
Is Multilingual BERT Fluent in Language Generation?
Oct 09, 2019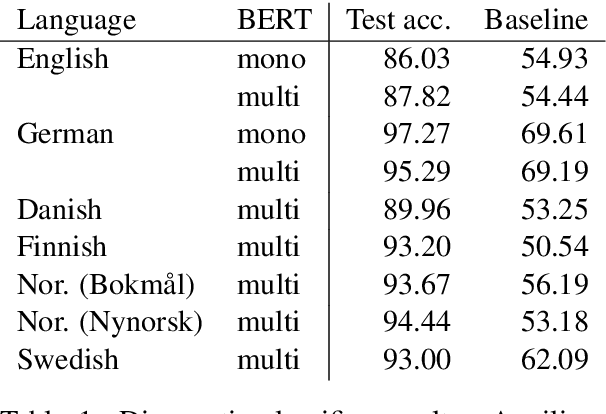

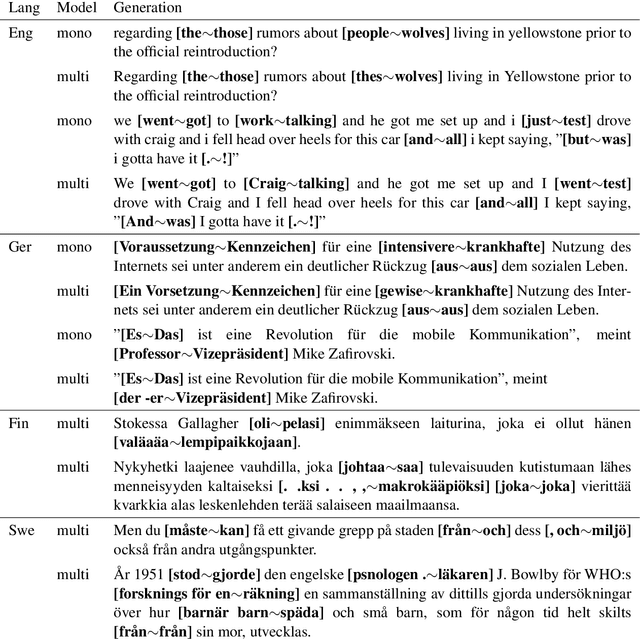

The multilingual BERT model is trained on 104 languages and meant to serve as a universal language model and tool for encoding sentences. We explore how well the model performs on several languages across several tasks: a diagnostic classification probing the embeddings for a particular syntactic property, a cloze task testing the language modelling ability to fill in gaps in a sentence, and a natural language generation task testing for the ability to produce coherent text fitting a given context. We find that the currently available multilingual BERT model is clearly inferior to the monolingual counterparts, and cannot in many cases serve as a substitute for a well-trained monolingual model. We find that the English and German models perform well at generation, whereas the multilingual model is lacking, in particular, for Nordic languages.
Template-free Data-to-Text Generation of Finnish Sports News
Oct 04, 2019
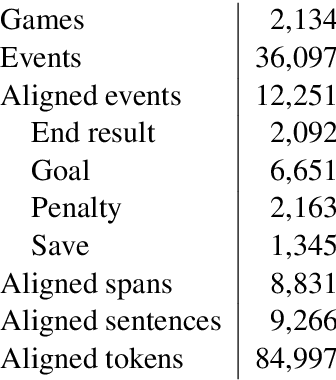
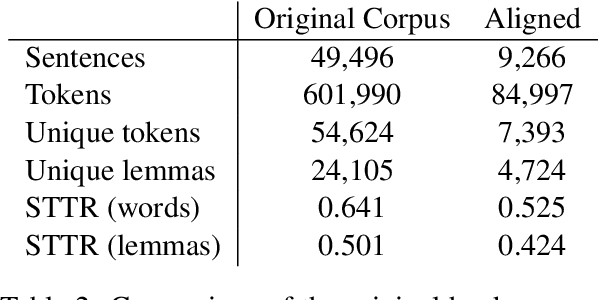
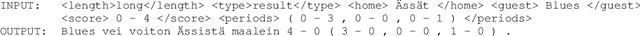
News articles such as sports game reports are often thought to closely follow the underlying game statistics, but in practice they contain a notable amount of background knowledge, interpretation, insight into the game, and quotes that are not present in the official statistics. This poses a challenge for automated data-to-text news generation with real-world news corpora as training data. We report on the development of a corpus of Finnish ice hockey news, edited to be suitable for training of end-to-end news generation methods, as well as demonstrate generation of text, which was judged by journalists to be relatively close to a viable product. The new dataset and system source code are available for research purposes at https://github.com/scoopmatic/finnish-hockey-news-generation-paper.
Leveraging Text Repetitions and Denoising Autoencoders in OCR Post-correction
Jun 26, 2019

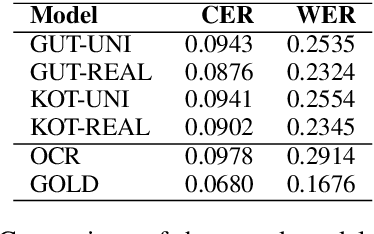
A common approach for improving OCR quality is a post-processing step based on models correcting misdetected characters and tokens. These models are typically trained on aligned pairs of OCR read text and their manually corrected counterparts. In this paper we show that the requirement of manually corrected training data can be alleviated by estimating the OCR errors from repeating text spans found in large OCR read text corpora and generating synthetic training examples following this error distribution. We use the generated data for training a character-level neural seq2seq model and evaluate the performance of the suggested model on a manually corrected corpus of Finnish newspapers mostly from the 19th century. The results show that a clear improvement over the underlying OCR system as well as previously suggested models utilizing uniformly generated noise can be achieved.
Universal Lemmatizer: A Sequence to Sequence Model for Lemmatizing Universal Dependencies Treebanks
Feb 03, 2019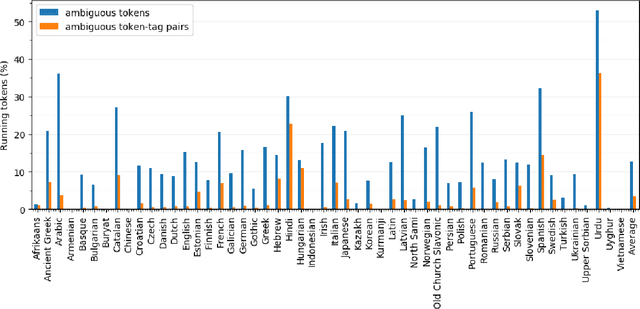

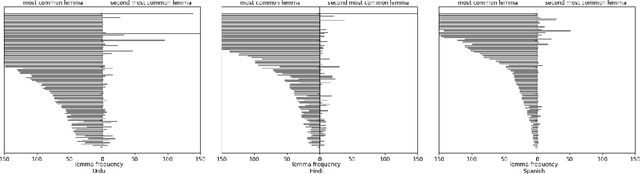

In this paper we present a novel lemmatization method based on a sequence-to-sequence neural network architecture and morphosyntactic context representation. In the proposed method, our context-sensitive lemmatizer generates the lemma one character at a time based on the surface form characters and its morphosyntactic features obtained from a morphological tagger. We argue that a sliding window context representation suffers from sparseness, while in majority of cases the morphosyntactic features of a word bring enough information to resolve lemma ambiguities while keeping the context representation dense and more practical for machine learning systems. Additionally, we study two different data augmentation methods utilizing autoencoder training and morphological transducers especially beneficial for low resource languages. We evaluate our lemmatizer on 52 different languages and 76 different treebanks, showing that our system outperforms all latest baseline systems. Compared to the best overall baseline, UDPipe Future, our system outperforms it on 60 out of 76 treebanks reducing errors on average by 18% relative. The lemmatizer together with all trained models is made available as a part of the Turku-neural-parsing-pipeline under the Apache 2.0 license.
A kernel-based framework for learning graded relations from data
Nov 28, 2011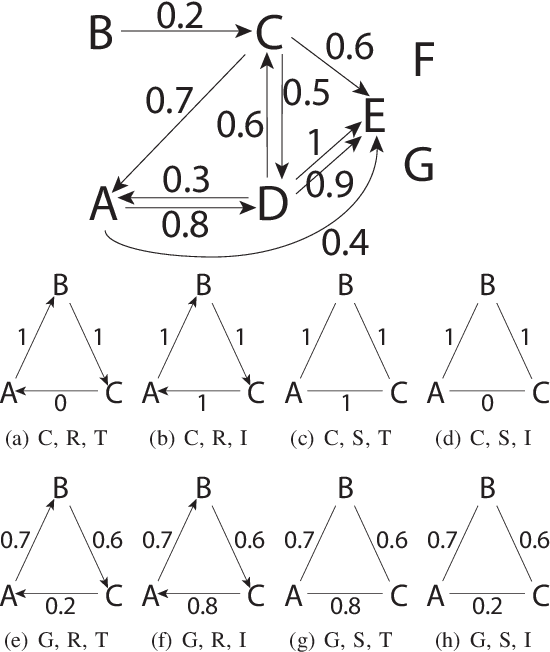
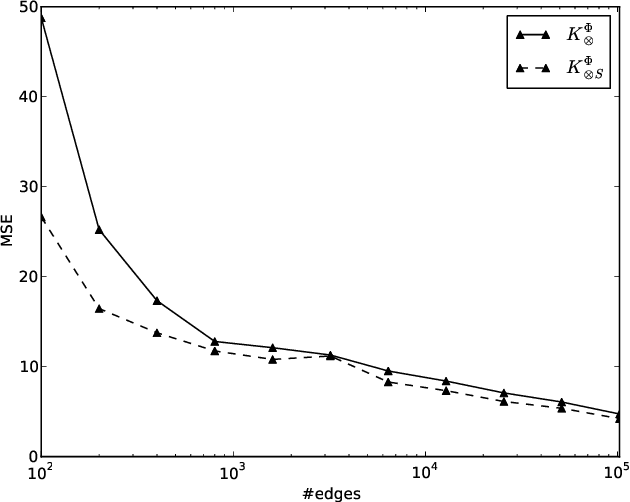
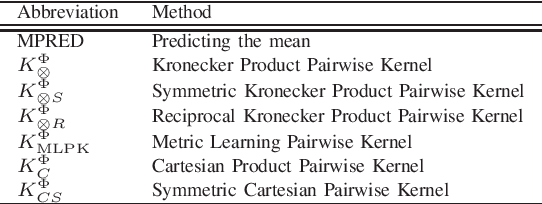
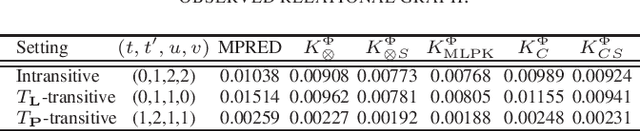
Driven by a large number of potential applications in areas like bioinformatics, information retrieval and social network analysis, the problem setting of inferring relations between pairs of data objects has recently been investigated quite intensively in the machine learning community. To this end, current approaches typically consider datasets containing crisp relations, so that standard classification methods can be adopted. However, relations between objects like similarities and preferences are often expressed in a graded manner in real-world applications. A general kernel-based framework for learning relations from data is introduced here. It extends existing approaches because both crisp and graded relations are considered, and it unifies existing approaches because different types of graded relations can be modeled, including symmetric and reciprocal relations. This framework establishes important links between recent developments in fuzzy set theory and machine learning. Its usefulness is demonstrated through various experiments on synthetic and real-world data.
Training linear ranking SVMs in linearithmic time using red-black trees
Jan 31, 2011
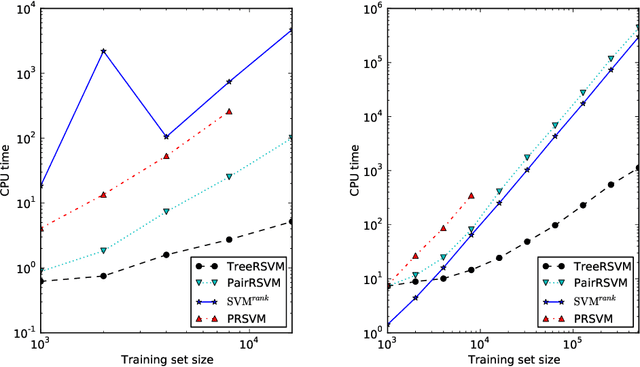


We introduce an efficient method for training the linear ranking support vector machine. The method combines cutting plane optimization with red-black tree based approach to subgradient calculations, and has O(m*s+m*log(m)) time complexity, where m is the number of training examples, and s the average number of non-zero features per example. Best previously known training algorithms achieve the same efficiency only for restricted special cases, whereas the proposed approach allows any real valued utility scores in the training data. Experiments demonstrate the superior scalability of the proposed approach, when compared to the fastest existing RankSVM implementations.
Linear Time Feature Selection for Regularized Least-Squares
Mar 18, 2010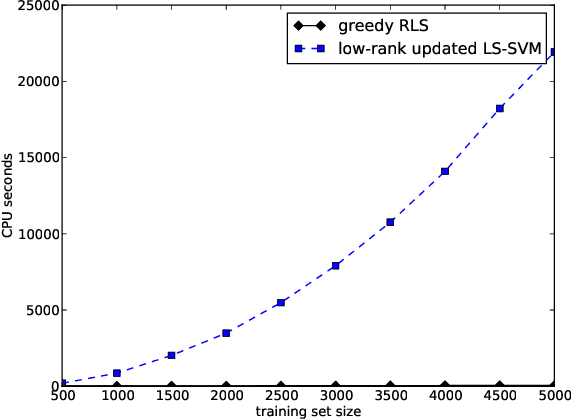

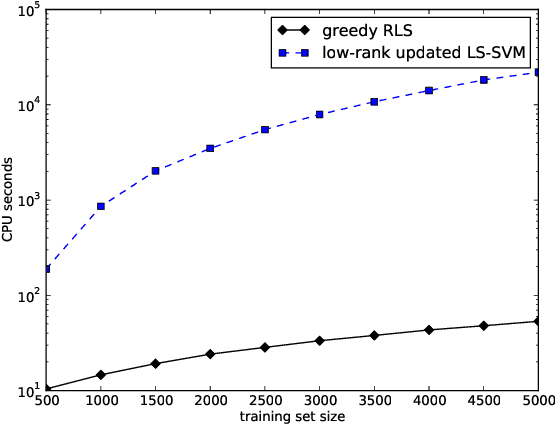

We propose a novel algorithm for greedy forward feature selection for regularized least-squares (RLS) regression and classification, also known as the least-squares support vector machine or ridge regression. The algorithm, which we call greedy RLS, starts from the empty feature set, and on each iteration adds the feature whose addition provides the best leave-one-out cross-validation performance. Our method is considerably faster than the previously proposed ones, since its time complexity is linear in the number of training examples, the number of features in the original data set, and the desired size of the set of selected features. Therefore, as a side effect we obtain a new training algorithm for learning sparse linear RLS predictors which can be used for large scale learning. This speed is possible due to matrix calculus based short-cuts for leave-one-out and feature addition. We experimentally demonstrate the scalability of our algorithm and its ability to find good quality feature sets.
Lexical Adaptation of Link Grammar to the Biomedical Sublanguage: a Comparative Evaluation of Three Approaches
Jun 28, 2006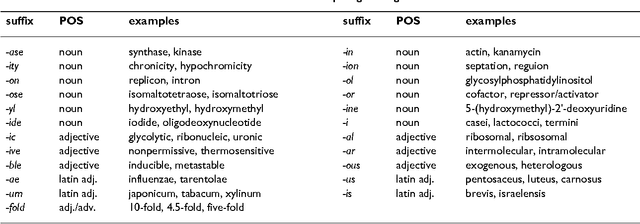
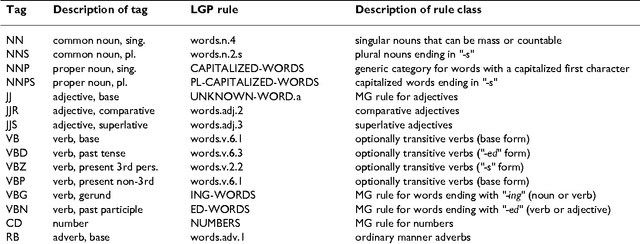

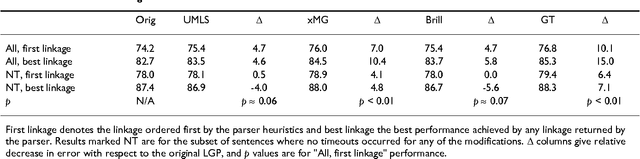
We study the adaptation of Link Grammar Parser to the biomedical sublanguage with a focus on domain terms not found in a general parser lexicon. Using two biomedical corpora, we implement and evaluate three approaches to addressing unknown words: automatic lexicon expansion, the use of morphological clues, and disambiguation using a part-of-speech tagger. We evaluate each approach separately for its effect on parsing performance and consider combinations of these approaches. In addition to a 45% increase in parsing efficiency, we find that the best approach, incorporating information from a domain part-of-speech tagger, offers a statistically signicant 10% relative decrease in error. The adapted parser is available under an open-source license at http://www.it.utu.fi/biolg.