 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Large Lexicalized Ontologies from Text: a Use Case in Automatic Indexing of Biotechnology Patents
Oct 02, 2020This paper presents a tool, TyDI, and methods experimented in the building of a termino-ontology, i.e. a lexicalized ontology aimed at fine-grained indexation for semantic search applications. TyDI provides facilities for knowledge engineers and domain experts to efficiently collaborate to validate, organize and conceptualize corpus extracted terms. A use case on biotechnology patent search demonstrates TyDI's potential.
A Robust Linguistic Platform for Efficient and Domain specific Web Content Analysis
Jun 29, 2007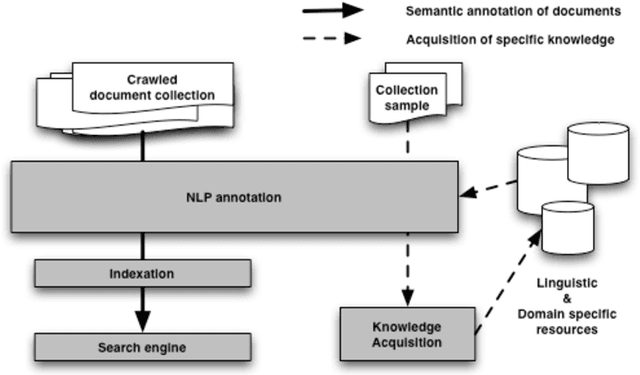

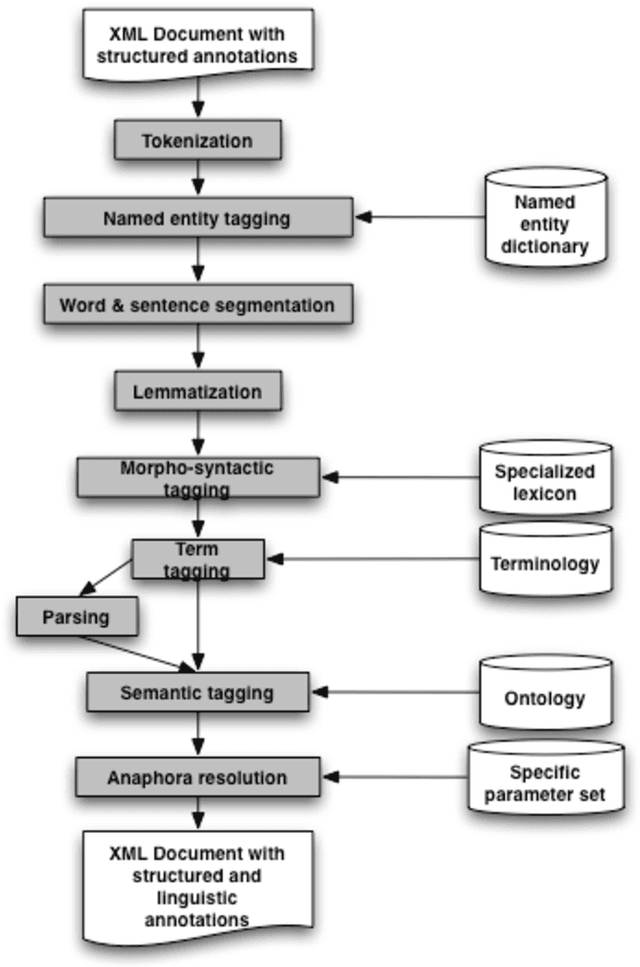
Web semantic access in specific domains calls for specialized search engines with enhanced semantic querying and indexing capacities, which pertain both to information retrieval (IR) and to information extraction (IE). A rich linguistic analysis is required either to identify the relevant semantic units to index and weight them according to linguistic specific statistical distribution, or as the basis of an information extraction process. Recent developments make Natural Language Processing (NLP) techniques reliable enough to process large collections of documents and to enrich them with semantic annotations. This paper focuses on the design and the development of a text processing platform, Ogmios, which has been developed in the ALVIS project. The Ogmios platform exploits existing NLP modules and resources, which may be tuned to specific domains and produces linguistically annotated documents. We show how the three constraints of genericity, domain semantic awareness and performance can be handled all together.
Event-based Information Extraction for the biomedical domain: the Caderige project
Sep 24, 2006

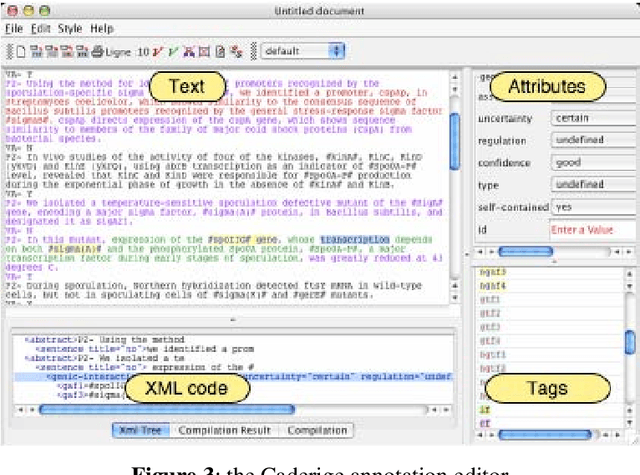
This paper gives an overview of the Caderige project. This project involves teams from different areas (biology, machine learning, natural language processing) in order to develop high-level analysis tools for extracting structured information from biological bibliographical databases, especially Medline. The paper gives an overview of the approach and compares it to the state of the art.
Improving Term Extraction with Terminological Resources
Sep 06, 2006


Studies of different term extractors on a corpus of the biomedical domain revealed decreasing performances when applied to highly technical texts. The difficulty or impossibility of customising them to new domains is an additional limitation. In this paper, we propose to use external terminologies to influence generic linguistic data in order to augment the quality of the extraction. The tool we implemented exploits testified terms at different steps of the process: chunking, parsing and extraction of term candidates. Experiments reported here show that, using this method, more term candidates can be acquired with a higher level of reliability. We further describe the extraction process involving endogenous disambiguation implemented in the term extractor YaTeA.
Lexical Adaptation of Link Grammar to the Biomedical Sublanguage: a Comparative Evaluation of Three Approaches
Jun 28, 2006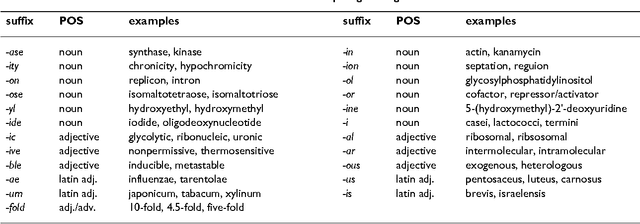
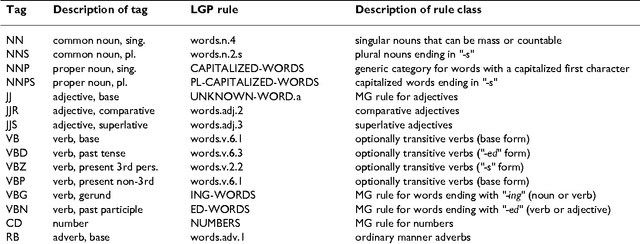

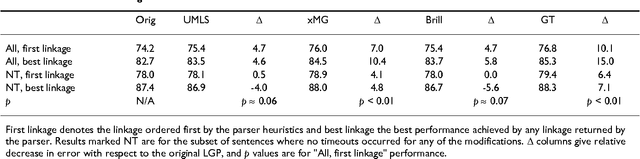
We study the adaptation of Link Grammar Parser to the biomedical sublanguage with a focus on domain terms not found in a general parser lexicon. Using two biomedical corpora, we implement and evaluate three approaches to addressing unknown words: automatic lexicon expansion, the use of morphological clues, and disambiguation using a part-of-speech tagger. We evaluate each approach separately for its effect on parsing performance and consider combinations of these approaches. In addition to a 45% increase in parsing efficiency, we find that the best approach, incorporating information from a domain part-of-speech tagger, offers a statistically signicant 10% relative decrease in error. The adapted parser is available under an open-source license at http://www.it.utu.fi/biolg.
Adapting a general parser to a sublanguage
Jun 28, 2006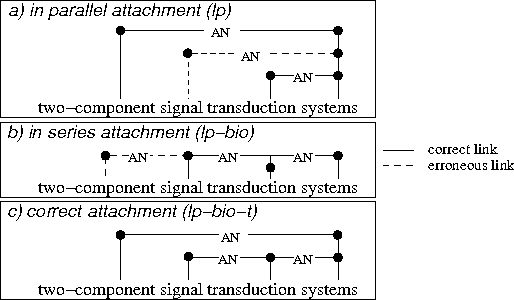
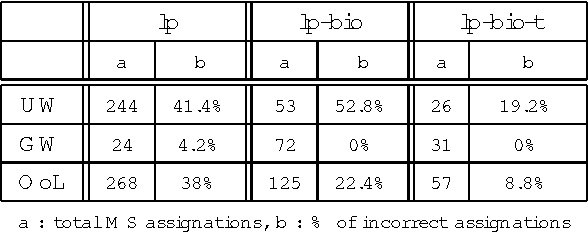
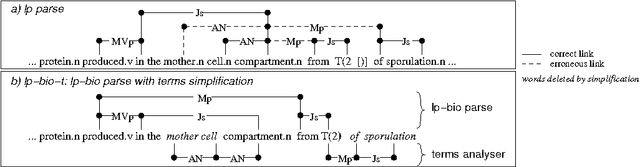
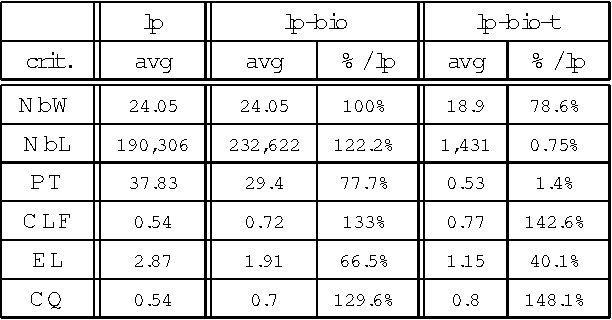
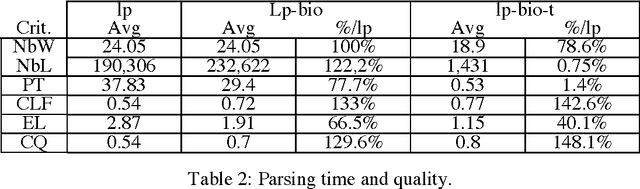
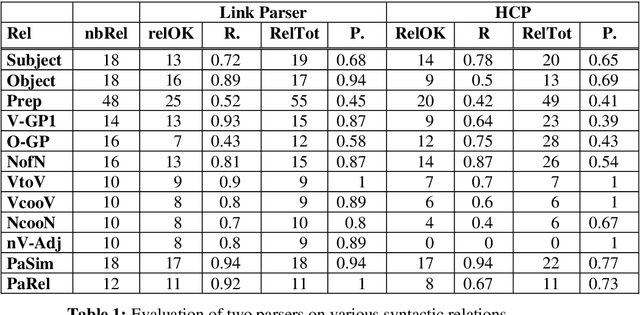
In this paper, we propose a method to adapt a general parser (Link Parser) to sublanguages, focusing on the parsing of texts in biology. Our main proposal is the use of terminology (identication and analysis of terms) in order to reduce the complexity of the text to be parsed. Several other strategies are explored and finally combined among which text normalization, lexicon and morpho-guessing module extensions and grammar rules adaptation. We compare the parsing results before and after these adaptations.