Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent-based Information Extraction for the biomedical domain: the Caderige project
Paper and Code
Sep 24, 2006
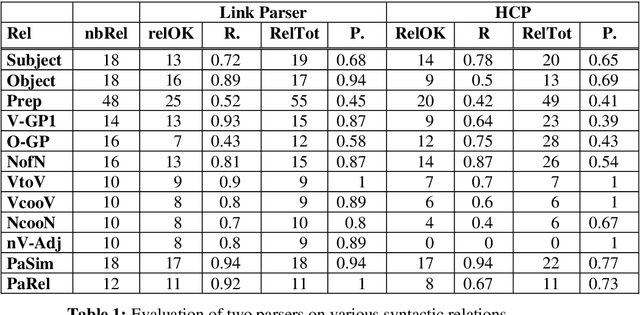

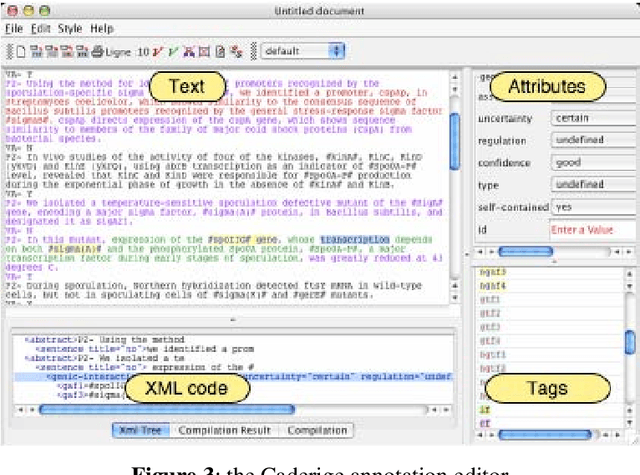
This paper gives an overview of the Caderige project. This project involves teams from different areas (biology, machine learning, natural language processing) in order to develop high-level analysis tools for extracting structured information from biological bibliographical databases, especially Medline. The paper gives an overview of the approach and compares it to the state of the art.
* Proceedings of the International Joint Workshop on Natural
Language Processing in Biomedicine and Its Applications (COLING'04), Suisse
(2004) 43-39
View paper on