 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Robust Linguistic Platform for Efficient and Domain specific Web Content Analysis
Paper and Code
Jun 29, 2007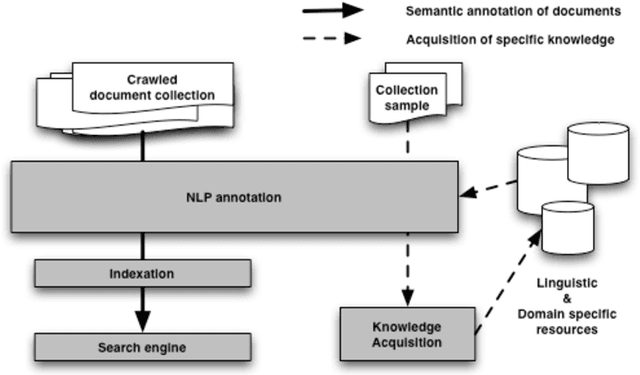

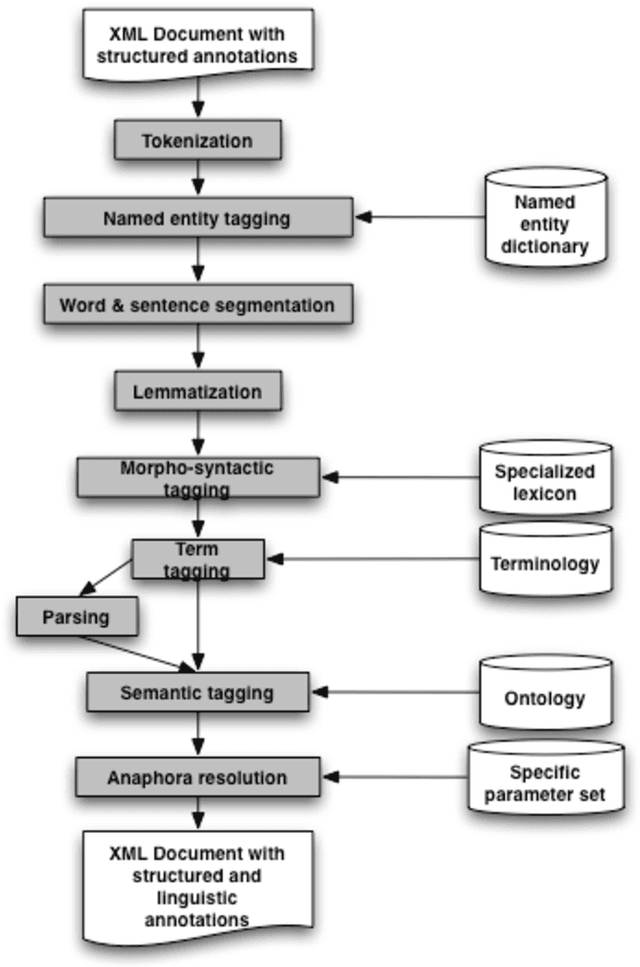
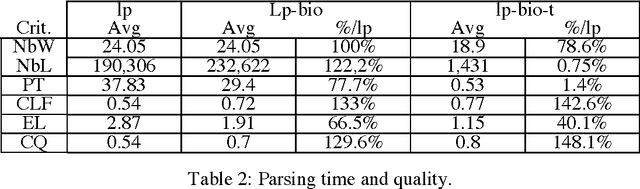
Web semantic access in specific domains calls for specialized search engines with enhanced semantic querying and indexing capacities, which pertain both to information retrieval (IR) and to information extraction (IE). A rich linguistic analysis is required either to identify the relevant semantic units to index and weight them according to linguistic specific statistical distribution, or as the basis of an information extraction process. Recent developments make Natural Language Processing (NLP) techniques reliable enough to process large collections of documents and to enrich them with semantic annotations. This paper focuses on the design and the development of a text processing platform, Ogmios, which has been developed in the ALVIS project. The Ogmios platform exploits existing NLP modules and resources, which may be tuned to specific domains and produces linguistically annotated documents. We show how the three constraints of genericity, domain semantic awareness and performance can be handled all together.