 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteraction Concordance Index: Performance Evaluation for Interaction Prediction Methods
Oct 16, 2025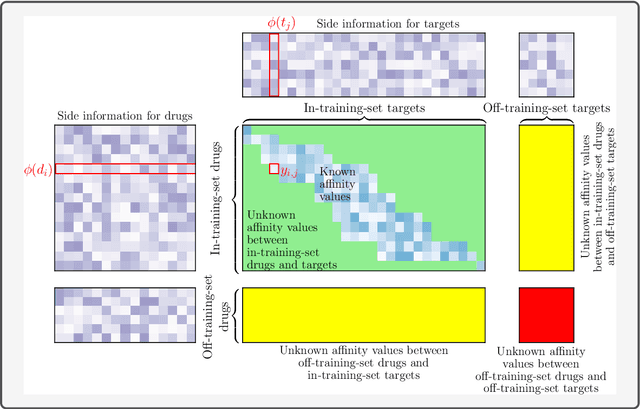

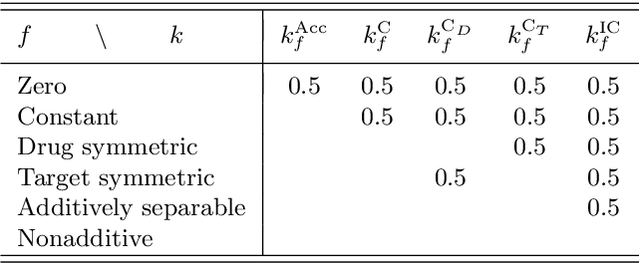

Consider two sets of entities and their members' mutual affinity values, say drug-target affinities (DTA). Drugs and targets are said to interact in their effects on DTAs if drug's effect on it depends on the target. Presence of interaction implies that assigning a drug to a target and another drug to another target does not provide the same aggregate DTA as the reversed assignment would provide. Accordingly, correctly capturing interactions enables better decision-making, for example, in allocation of limited numbers of drug doses to their best matching targets. Learning to predict DTAs is popularly done from either solely from known DTAs or together with side information on the entities, such as chemical structures of drugs and targets. In this paper, we introduce interaction directions' prediction performance estimator we call interaction concordance index (IC-index), for both fixed predictors and machine learning algorithms aimed for inferring them. IC-index complements the popularly used DTA prediction performance estimators by evaluating the ratio of correctly predicted directions of interaction effects in data. First, we show the invariance of IC-index on predictors unable to capture interactions. Secondly, we show that learning algorithm's permutation equivariance regarding drug and target identities implies its inability to capture interactions when either drug, target or both are unseen during training. In practical applications, this equivariance is remedied via incorporation of appropriate side information on drugs and targets. We make a comprehensive empirical evaluation over several biomedical interaction data sets with various state-of-the-art machine learning algorithms. The experiments demonstrate how different types of affinity strength prediction methods perform in terms of IC-index complementing existing prediction performance estimators.
A Comprehensive Guide to Differential Privacy: From Theory to User Expectations
Sep 03, 2025The increasing availability of personal data has enabled significant advances in fields such as machine learning, healthcare, and cybersecurity. However, this data abundance also raises serious privacy concerns, especially in light of powerful re-identification attacks and growing legal and ethical demands for responsible data use. Differential privacy (DP) has emerged as a principled, mathematically grounded framework for mitigating these risks. This review provides a comprehensive survey of DP, covering its theoretical foundations, practical mechanisms, and real-world applications. It explores key algorithmic tools and domain-specific challenges - particularly in privacy-preserving machine learning and synthetic data generation. The report also highlights usability issues and the need for improved communication and transparency in DP systems. Overall, the goal is to support informed adoption of DP by researchers and practitioners navigating the evolving landscape of data privacy.
Does Differentially Private Synthetic Data Lead to Synthetic Discoveries?
Mar 20, 2024Background: Synthetic data has been proposed as a solution for sharing anonymized versions of sensitive biomedical datasets. Ideally, synthetic data should preserve the structure and statistical properties of the original data, while protecting the privacy of the individual subjects. Differential privacy (DP) is currently considered the gold standard approach for balancing this trade-off. Objectives: The aim of this study is to evaluate the Mann-Whitney U test on DP-synthetic biomedical data in terms of Type I and Type II errors, in order to establish whether statistical hypothesis testing performed on privacy preserving synthetic data is likely to lead to loss of test's validity or decreased power. Methods: We evaluate the Mann-Whitney U test on DP-synthetic data generated from real-world data, including a prostate cancer dataset (n=500) and a cardiovascular dataset (n=70 000), as well as on data drawn from two Gaussian distributions. Five different DP-synthetic data generation methods are evaluated, including two basic DP histogram release methods and MWEM, Private-PGM, and DP GAN algorithms. Conclusion: Most of the tested DP-synthetic data generation methods showed inflated Type I error, especially at privacy budget levels of $\epsilon\leq 1$. This result calls for caution when releasing and analyzing DP-synthetic data: low p-values may be obtained in statistical tests simply as a byproduct of the noise added to protect privacy. A DP smoothed histogram-based synthetic data generation method was shown to produce valid Type I error for all privacy levels tested but required a large original dataset size and a modest privacy budget ($\epsilon\geq 5$) in order to have reasonable Type II error levels.
A Link between Coding Theory and Cross-Validation with Applications
Mar 22, 2021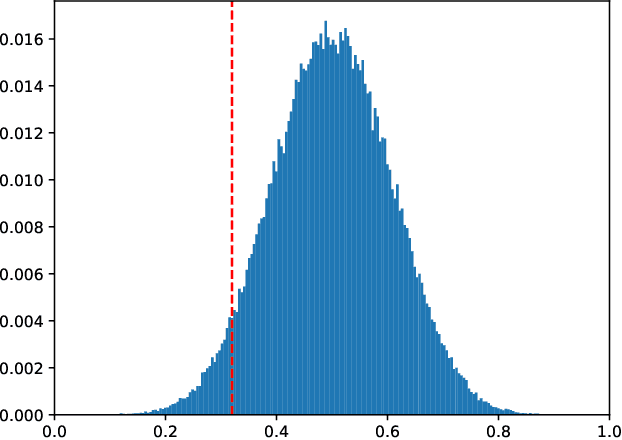

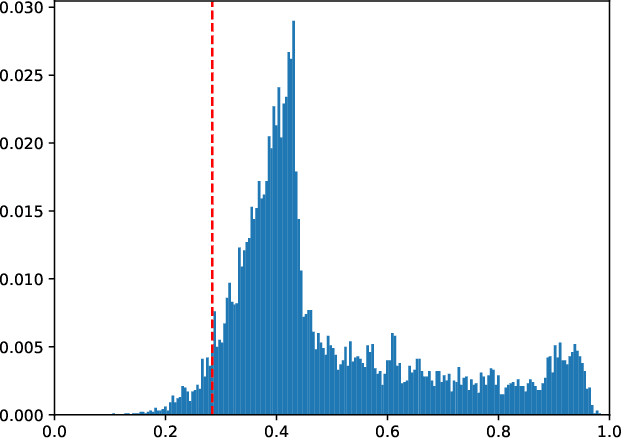
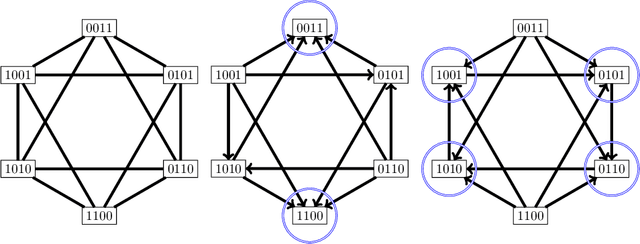
We study the combinatorics of cross-validation based AUC estimation under the null hypothesis that the binary class labels are exchangeable, that is, the data are randomly assigned into two classes given a fixed class proportion. In particular, we study how the estimators based on leave-pair-out cross-validation (LPOCV), in which every possible pair of data with different class labels is held out from the training set at a time, behave under the null without any prior assumptions of the learning algorithm or the data. It is shown that the maximal number of different fixed proportion label assignments on a sample of data, for which a learning algorithm can achieve zero LPOCV error, is the maximal size of a constant weight error correcting code, whose length is the sample size, weight is the number of data labeled with one, and the Hamming distance between code words is four. We then introduce the concept of a light constant weight code and show similar results for nonzero LPOCV errors. We also prove both upper and lower bounds on the maximal sizes of the light constant weight codes that are similar to the classical results for contant weight codes. These results pave the way towards the design of new LPOCV based statistical tests for the learning algorithms ability of distinguishing two classes from each other that are analogous to the classical Wilcoxon-Mann-Whitney U test for fixed functions. Behavior of some representative examples of learning algorithms and data are simulated in an experimental case study.
New Recommendation Algorithm for Implicit Data Motivated by the Multivariate Normal Distribution
Dec 21, 2020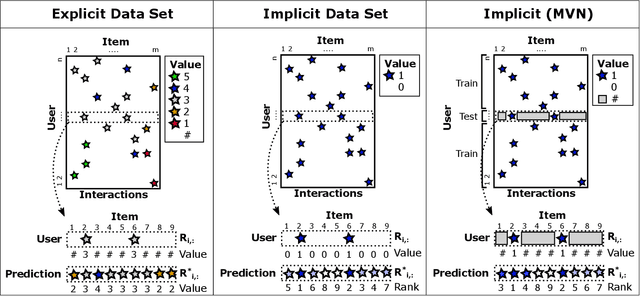
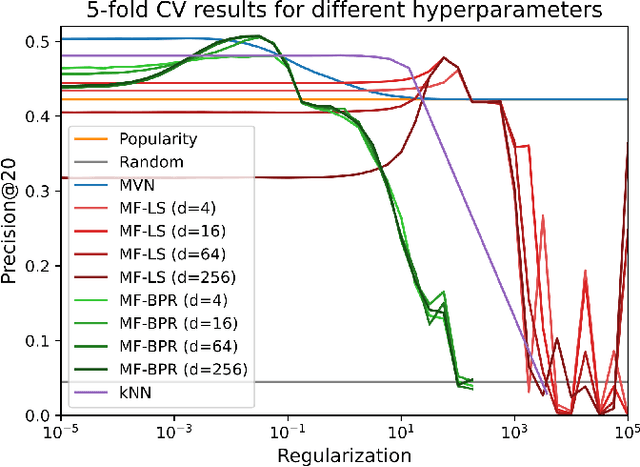
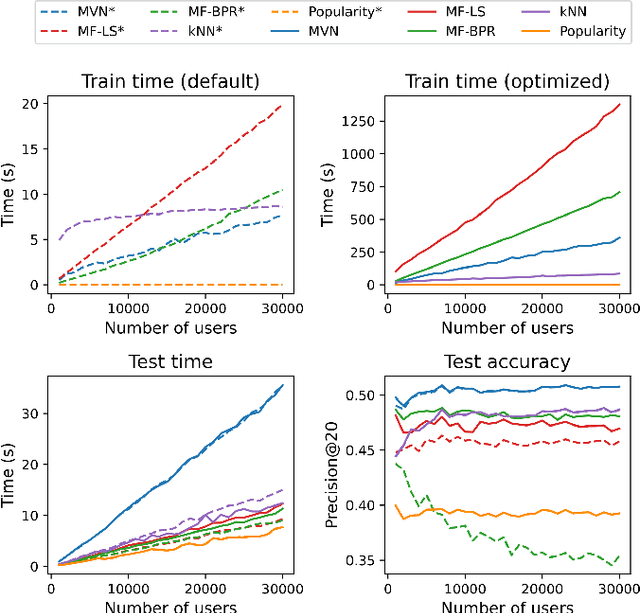
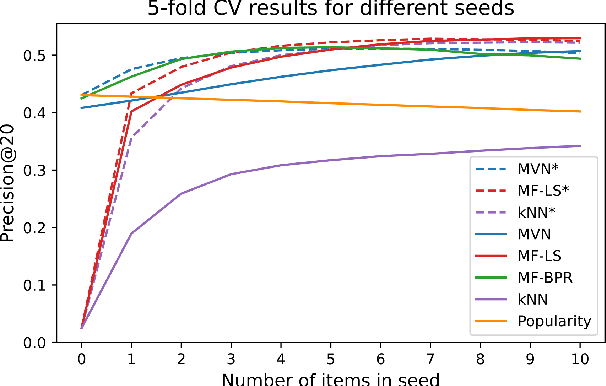
The goal of recommender systems is to help users find useful items from a large catalog of items by producing a list of item recommendations for every user. Data sets based on implicit data collection have a number of special characteristics. The user and item interaction matrix is often complete, i.e. every user and item pair has an interaction value or zero for no interaction, and the goal is to rank the items for every user. This study presents a simple new algorithm for implicit data that matches or outperforms baselines in accuracy. The algorithm can be motivated intuitively by the Multivariate Normal Distribution (MVN), where have a closed form expression for the ranking of non-interactions given user's interactions. The main difference to kNN and SVD baselines is that predictions are carried out using only the known interactions. Modified baselines with this trick have a better accuracy, however it also results in simpler models with fewer hyperparameters for implicit data. Our results suggest that this idea should used in Top-N recommendation with small seed sizes and the MVN is a simple way to do so.
Content Based Player and Game Interaction Model for Game Recommendation in the Cold Start setting
Sep 11, 2020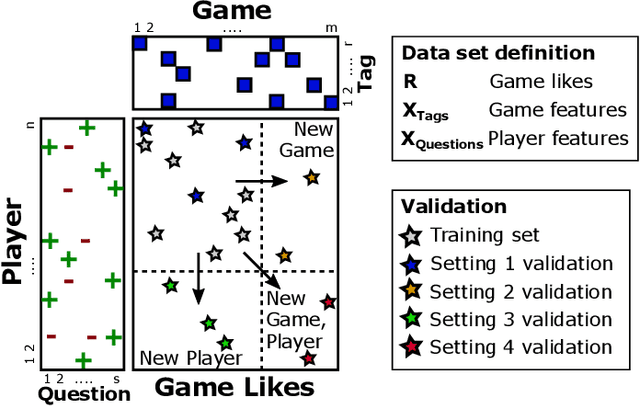
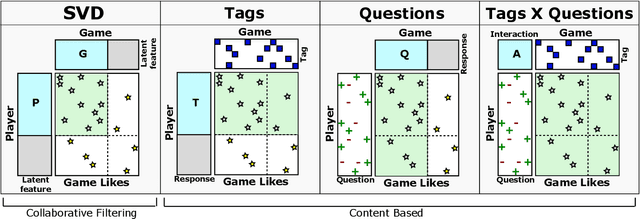
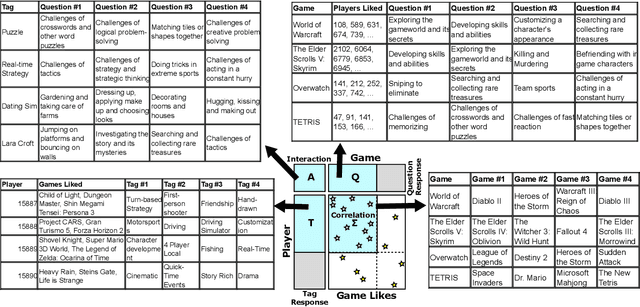
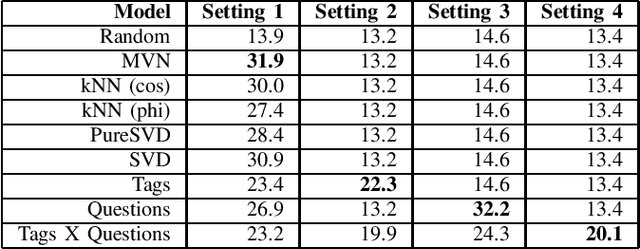
Game recommendation is an important application of recommender systems. Recommendations are made possible by data sets of historical player and game interactions, and sometimes the data sets include features that describe games or players. Collaborative filtering has been found to be the most accurate predictor of past interactions. However, it can only be applied to predict new interactions for those games and players where a significant number of past interactions are present. In other words, predictions for completely new games and players is not possible. In this paper, we use a survey data set of game likes to present content based interaction models that generalize into new games, new players, and both new games and players simultaneously. We find that the models outperform collaborative filtering in these tasks, which makes them useful for real world game recommendation. The content models also provide interpretations of why certain games are liked by certain players for game analytics purposes.
Generalized vec trick for fast learning of pairwise kernel models
Sep 02, 2020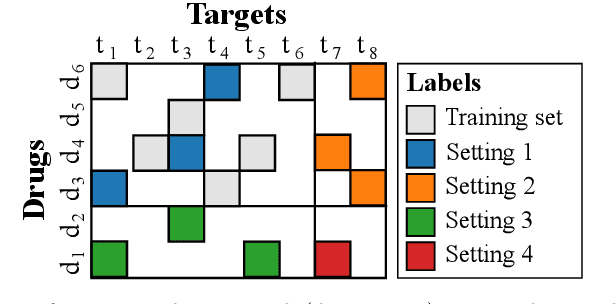


Pairwise learning corresponds to the supervised learning setting where the goal is to make predictions for pairs of objects. Prominent applications include predicting drug-target or protein-protein interactions, or customer-product preferences. Several kernel functions have been proposed for incorporating prior knowledge about the relationship between the objects, when training kernel based learning methods. However, the number of training pairs n is often very large, making O(n^2) cost of constructing the pairwise kernel matrix infeasible. If each training pair x= (d,t) consists of drug d and target t, let m and q denote the number of unique drugs and targets appearing in the training pairs. In many real-world applications m,q << n, which can be used to develop computational shortcuts. Recently, a O(nm+nq) time algorithm we refer to as the generalized vec trick was introduced for training kernel methods with the Kronecker kernel. In this work, we show that a large class of pairwise kernels can be expressed as a sum of product matrices, which generalizes the result to the most commonly used pairwise kernels. This includes symmetric and anti-symmetric, metric-learning, Cartesian, ranking, as well as linear, polynomial and Gaussian kernels. In the experiments, we demonstrate how the introduced approach allows scaling pairwise kernels to much larger data sets than previously feasible, and compare the kernels on a number of biological interaction prediction tasks.
Estimating the Prediction Performance of Spatial Models via Spatial k-Fold Cross Validation
May 28, 2020In machine learning one often assumes the data are independent when evaluating model performance. However, this rarely holds in practise. Geographic information data sets are an example where the data points have stronger dependencies among each other the closer they are geographically. This phenomenon known as spatial autocorrelation (SAC) causes the standard cross validation (CV) methods to produce optimistically biased prediction performance estimates for spatial models, which can result in increased costs and accidents in practical applications. To overcome this problem we propose a modified version of the CV method called spatial k-fold cross validation (SKCV), which provides a useful estimate for model prediction performance without optimistic bias due to SAC. We test SKCV with three real world cases involving open natural data showing that the estimates produced by the ordinary CV are up to 40% more optimistic than those of SKCV. Both regression and classification cases are considered in our experiments. In addition, we will show how the SKCV method can be applied as a criterion for selecting data sampling density for new research area.
* 18 pages, 12 figures, 1 table
A Solution for Large Scale Nonlinear Regression with High Rank and Degree at Constant Memory Complexity via Latent Tensor Reconstruction
May 04, 2020
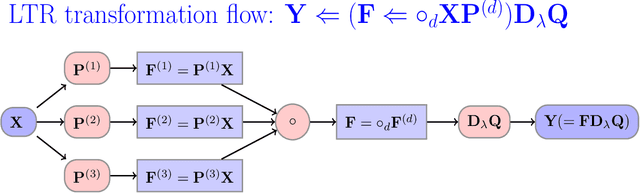

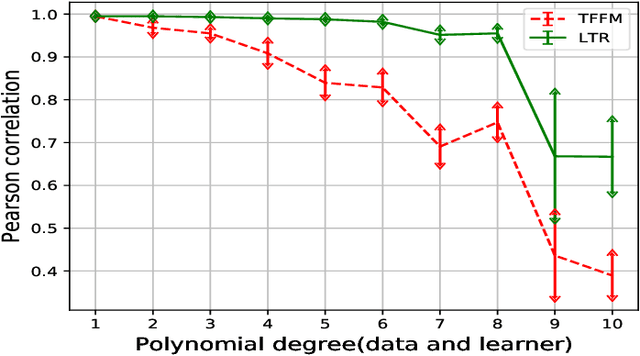
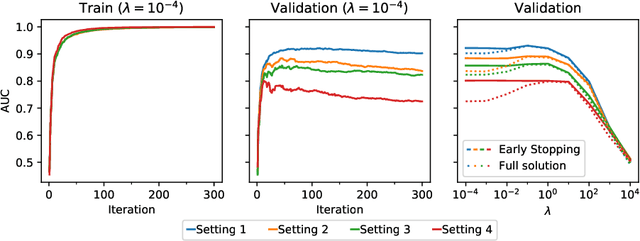
This paper proposes a novel method for learning highly nonlinear, multivariate functions from examples. Our method takes advantage of the property that continuous functions can be approximated by polynomials, which in turn are representable by tensors. Hence the function learning problem is transformed into a tensor reconstruction problem, an inverse problem of the tensor decomposition. Our method incrementally builds up the unknown tensor from rank-one terms, which lets us control the complexity of the learned model and reduce the chance of overfitting. For learning the models, we present an efficient gradient-based algorithm that can be implemented in linear time in the sample size, order, rank of the tensor and the dimension of the input. In addition to regression, we present extensions to classification, multi-view learning and vector-valued output as well as a multi-layered formulation. The method can work in an online fashion via processing mini-batches of the data with constant memory complexity. Consequently, it can fit into systems equipped only with limited resources such as embedded systems or mobile phones. Our experiments demonstrate a favorable accuracy and running time compared to competing methods.
A Comparative Study of Pairwise Learning Methods based on Kernel Ridge Regression
Mar 05, 2018Many machine learning problems can be formulated as predicting labels for a pair of objects. Problems of that kind are often referred to as pairwise learning, dyadic prediction or network inference problems. During the last decade kernel methods have played a dominant role in pairwise learning. They still obtain a state-of-the-art predictive performance, but a theoretical analysis of their behavior has been underexplored in the machine learning literature. In this work we review and unify existing kernel-based algorithms that are commonly used in different pairwise learning settings, ranging from matrix filtering to zero-shot learning. To this end, we focus on closed-form efficient instantiations of Kronecker kernel ridge regression. We show that independent task kernel ridge regression, two-step kernel ridge regression and a linear matrix filter arise naturally as a special case of Kronecker kernel ridge regression, implying that all these methods implicitly minimize a squared loss. In addition, we analyze universality, consistency and spectral filtering properties. Our theoretical results provide valuable insights in assessing the advantages and limitations of existing pairwise learning methods.