 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNew Recommendation Algorithm for Implicit Data Motivated by the Multivariate Normal Distribution
Dec 21, 2020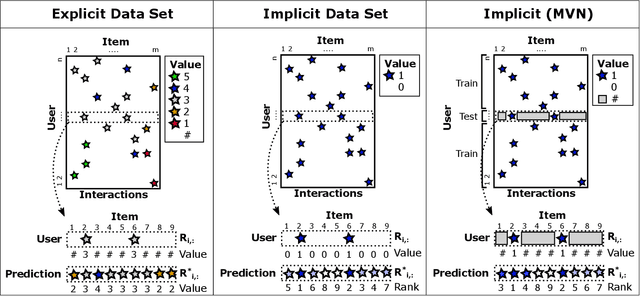
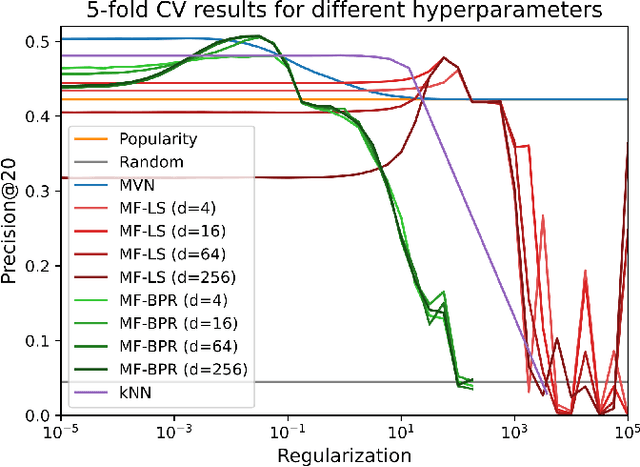
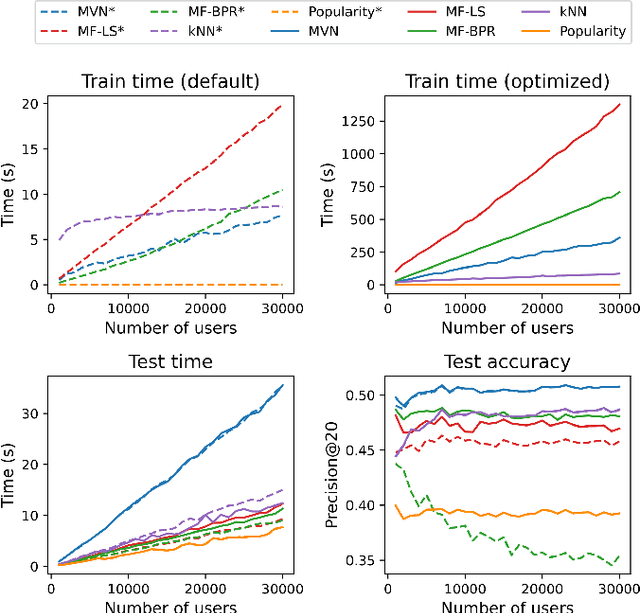
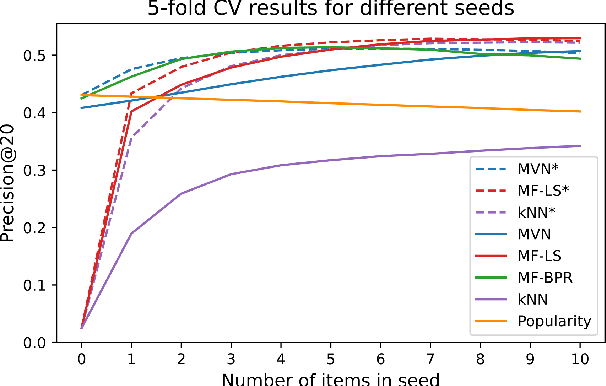
The goal of recommender systems is to help users find useful items from a large catalog of items by producing a list of item recommendations for every user. Data sets based on implicit data collection have a number of special characteristics. The user and item interaction matrix is often complete, i.e. every user and item pair has an interaction value or zero for no interaction, and the goal is to rank the items for every user. This study presents a simple new algorithm for implicit data that matches or outperforms baselines in accuracy. The algorithm can be motivated intuitively by the Multivariate Normal Distribution (MVN), where have a closed form expression for the ranking of non-interactions given user's interactions. The main difference to kNN and SVD baselines is that predictions are carried out using only the known interactions. Modified baselines with this trick have a better accuracy, however it also results in simpler models with fewer hyperparameters for implicit data. Our results suggest that this idea should used in Top-N recommendation with small seed sizes and the MVN is a simple way to do so.
Content Based Player and Game Interaction Model for Game Recommendation in the Cold Start setting
Sep 11, 2020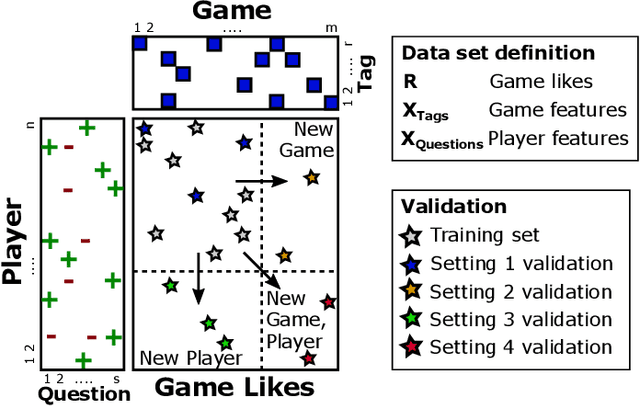
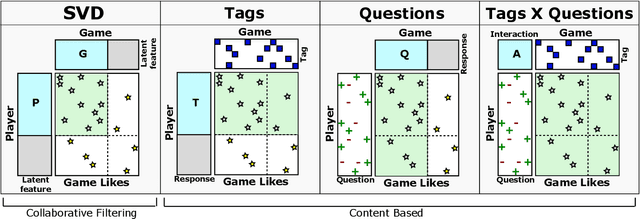
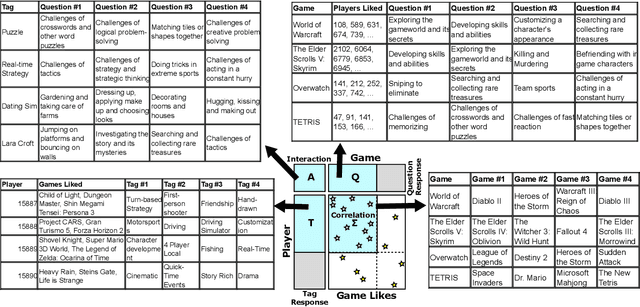
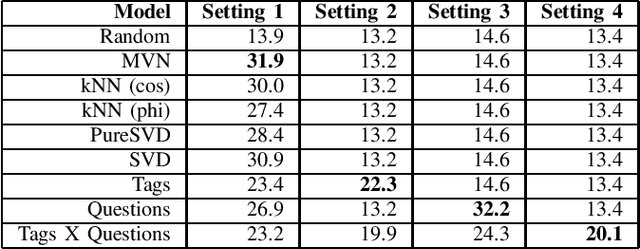
Game recommendation is an important application of recommender systems. Recommendations are made possible by data sets of historical player and game interactions, and sometimes the data sets include features that describe games or players. Collaborative filtering has been found to be the most accurate predictor of past interactions. However, it can only be applied to predict new interactions for those games and players where a significant number of past interactions are present. In other words, predictions for completely new games and players is not possible. In this paper, we use a survey data set of game likes to present content based interaction models that generalize into new games, new players, and both new games and players simultaneously. We find that the models outperform collaborative filtering in these tasks, which makes them useful for real world game recommendation. The content models also provide interpretations of why certain games are liked by certain players for game analytics purposes.
Generalized vec trick for fast learning of pairwise kernel models
Sep 02, 2020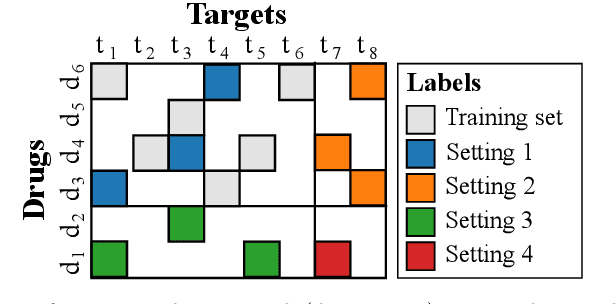


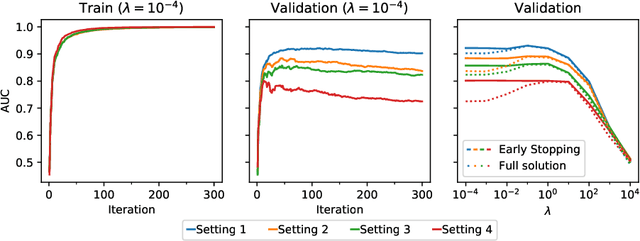
Pairwise learning corresponds to the supervised learning setting where the goal is to make predictions for pairs of objects. Prominent applications include predicting drug-target or protein-protein interactions, or customer-product preferences. Several kernel functions have been proposed for incorporating prior knowledge about the relationship between the objects, when training kernel based learning methods. However, the number of training pairs n is often very large, making O(n^2) cost of constructing the pairwise kernel matrix infeasible. If each training pair x= (d,t) consists of drug d and target t, let m and q denote the number of unique drugs and targets appearing in the training pairs. In many real-world applications m,q << n, which can be used to develop computational shortcuts. Recently, a O(nm+nq) time algorithm we refer to as the generalized vec trick was introduced for training kernel methods with the Kronecker kernel. In this work, we show that a large class of pairwise kernels can be expressed as a sum of product matrices, which generalizes the result to the most commonly used pairwise kernels. This includes symmetric and anti-symmetric, metric-learning, Cartesian, ranking, as well as linear, polynomial and Gaussian kernels. In the experiments, we demonstrate how the introduced approach allows scaling pairwise kernels to much larger data sets than previously feasible, and compare the kernels on a number of biological interaction prediction tasks.
Playtime Measurement with Survival Analysis
Jan 04, 2017
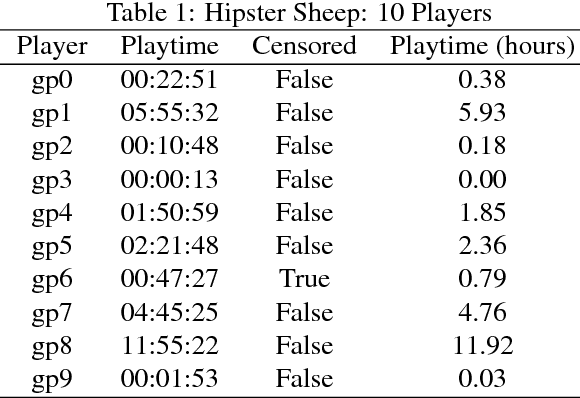


Maximizing product use is a central goal of many businesses, which makes retention and monetization two central analytics metrics in games. Player retention may refer to various duration variables quantifying product use: total playtime or session playtime are popular research targets, and active playtime is well-suited for subscription games. Such research often has the goal of increasing player retention or conversely decreasing player churn. Survival analysis is a framework of powerful tools well suited for retention type data. This paper contributes new methods to game analytics on how playtime can be analyzed using survival analysis without covariates. Survival and hazard estimates provide both a visual and an analytic interpretation of the playtime phenomena as a funnel type nonparametric estimate. Metrics based on the survival curve can be used to aggregate this playtime information into a single statistic. Comparison of survival curves between cohorts provides a scientific AB-test. All these methods work on censored data and enable computation of confidence intervals. This is especially important in time and sample limited data which occurs during game development. Throughout this paper, we illustrate the application of these methods to real world game development problems on the Hipster Sheep mobile game.
Spectral Analysis of Symmetric and Anti-Symmetric Pairwise Kernels
Jun 19, 2015We consider the problem of learning regression functions from pairwise data when there exists prior knowledge that the relation to be learned is symmetric or anti-symmetric. Such prior knowledge is commonly enforced by symmetrizing or anti-symmetrizing pairwise kernel functions. Through spectral analysis, we show that these transformations reduce the kernel's effective dimension. Further, we provide an analysis of the approximation properties of the resulting kernels, and bound the regularization bias of the kernels in terms of the corresponding bias of the original kernel.