Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining linear ranking SVMs in linearithmic time using red-black trees
Paper and Code
Jan 31, 2011
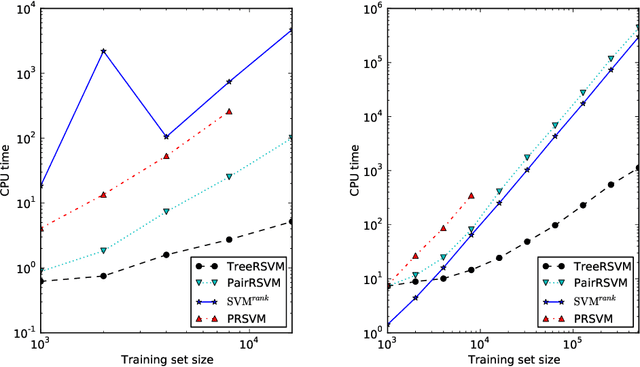


We introduce an efficient method for training the linear ranking support vector machine. The method combines cutting plane optimization with red-black tree based approach to subgradient calculations, and has O(m*s+m*log(m)) time complexity, where m is the number of training examples, and s the average number of non-zero features per example. Best previously known training algorithms achieve the same efficiency only for restricted special cases, whereas the proposed approach allows any real valued utility scores in the training data. Experiments demonstrate the superior scalability of the proposed approach, when compared to the fastest existing RankSVM implementations.
* 20 pages, 4 figures
View paper on