 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommonLID: Re-evaluating State-of-the-Art Language Identification Performance on Web Data
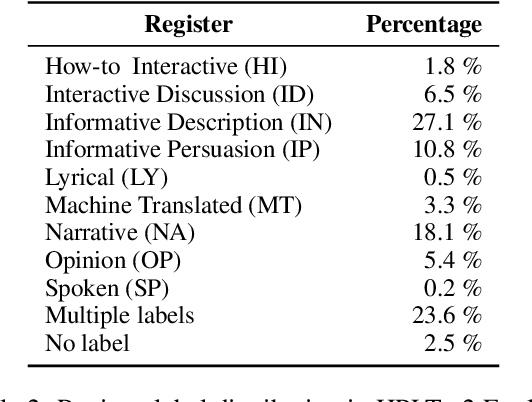
Jan 25, 2026Language identification (LID) is a fundamental step in curating multilingual corpora. However, LID models still perform poorly for many languages, especially on the noisy and heterogeneous web data often used to train multilingual language models. In this paper, we introduce CommonLID, a community-driven, human-annotated LID benchmark for the web domain, covering 109 languages. Many of the included languages have been previously under-served, making CommonLID a key resource for developing more representative high-quality text corpora. We show CommonLID's value by using it, alongside five other common evaluation sets, to test eight popular LID models. We analyse our results to situate our contribution and to provide an overview of the state of the art. In particular, we highlight that existing evaluations overestimate LID accuracy for many languages in the web domain. We make CommonLID and the code used to create it available under an open, permissive license.
Low-Resource, High-Impact: Building Corpora for Inclusive Language Technologies
Dec 16, 2025This tutorial (https://tum-nlp.github.io/low-resource-tutorial) is designed for NLP practitioners, researchers, and developers working with multilingual and low-resource languages who seek to create more equitable and socially impactful language technologies. Participants will walk away with a practical toolkit for building end-to-end NLP pipelines for underrepresented languages -- from data collection and web crawling to parallel sentence mining, machine translation, and downstream applications such as text classification and multimodal reasoning. The tutorial presents strategies for tackling the challenges of data scarcity and cultural variance, offering hands-on methods and modeling frameworks. We will focus on fair, reproducible, and community-informed development approaches, grounded in real-world scenarios. We will showcase a diverse set of use cases covering over 10 languages from different language families and geopolitical contexts, including both digitally resource-rich and severely underrepresented languages.
An Expanded Massive Multilingual Dataset for High-Performance Language Technologies
Mar 13, 2025


Training state-of-the-art large language models requires vast amounts of clean and diverse textual data. However, building suitable multilingual datasets remains a challenge. In this work, we present HPLT v2, a collection of high-quality multilingual monolingual and parallel corpora. The monolingual portion of the data contains 8T tokens covering 193 languages, while the parallel data contains 380M sentence pairs covering 51 languages. We document the entire data pipeline and release the code to reproduce it. We provide extensive analysis of the quality and characteristics of our data. Finally, we evaluate the performance of language models and machine translation systems trained on HPLT v2, demonstrating its value.
Code-Switched Language Identification is Harder Than You Think
Feb 02, 2024



Code switching (CS) is a very common phenomenon in written and spoken communication but one that is handled poorly by many natural language processing applications. Looking to the application of building CS corpora, we explore CS language identification (LID) for corpus building. We make the task more realistic by scaling it to more languages and considering models with simpler architectures for faster inference. We also reformulate the task as a sentence-level multi-label tagging problem to make it more tractable. Having defined the task, we investigate three reasonable models for this task and define metrics which better reflect desired performance. We present empirical evidence that no current approach is adequate and finally provide recommendations for future work in this area.
An Open Dataset and Model for Language Identification
May 23, 2023
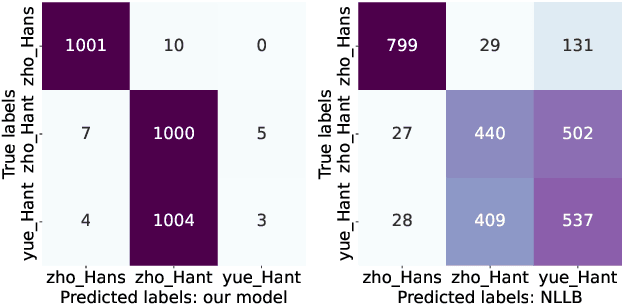
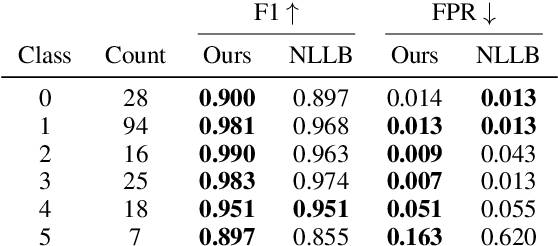
Language identification (LID) is a fundamental step in many natural language processing pipelines. However, current LID systems are far from perfect, particularly on lower-resource languages. We present a LID model which achieves a macro-average F1 score of 0.93 and a false positive rate of 0.033 across 201 languages, outperforming previous work. We achieve this by training on a curated dataset of monolingual data, the reliability of which we ensure by auditing a sample from each source and each language manually. We make both the model and the dataset available to the research community. Finally, we carry out detailed analysis into our model's performance, both in comparison to existing open models and by language class.
The University of Edinburgh's Submission to the WMT22 Code-Mixing Shared Task
Oct 20, 2022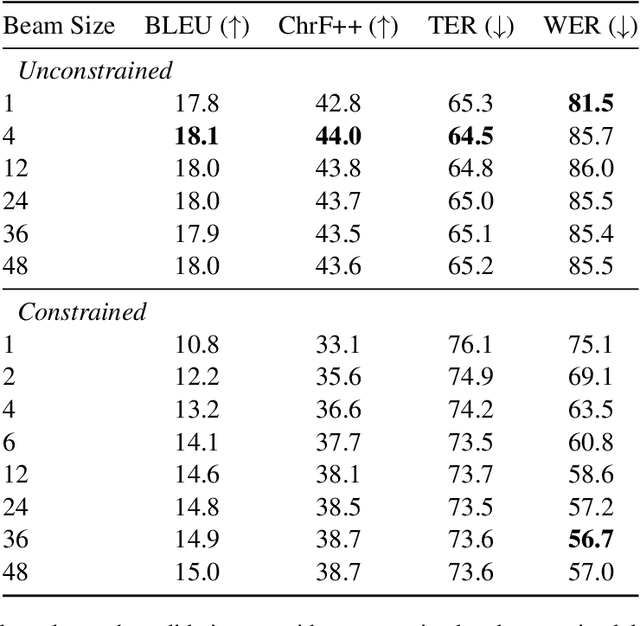
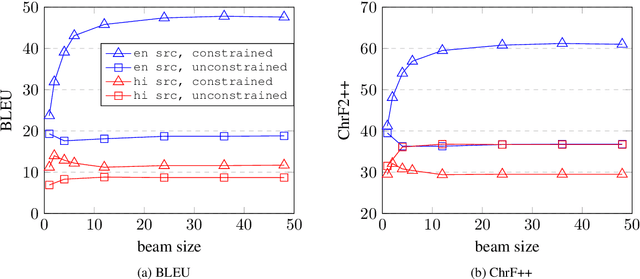
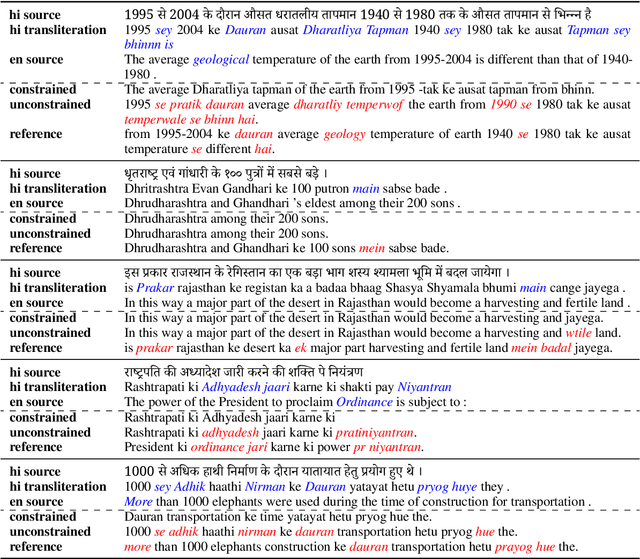
The University of Edinburgh participated in the WMT22 shared task on code-mixed translation. This consists of two subtasks: i) generating code-mixed Hindi/English (Hinglish) text generation from parallel Hindi and English sentences and ii) machine translation from Hinglish to English. As both subtasks are considered low-resource, we focused our efforts on careful data generation and curation, especially the use of backtranslation from monolingual resources. For subtask 1 we explored the effects of constrained decoding on English and transliterated subwords in order to produce Hinglish. For subtask 2, we investigated different pretraining techniques, namely comparing simple initialisation from existing machine translation models and aligned augmentation. For both subtasks, we found that our baseline systems worked best. Our systems for both subtasks were one of the overall top-performing submissions.
Exploring Diversity in Back Translation for Low-Resource Machine Translation
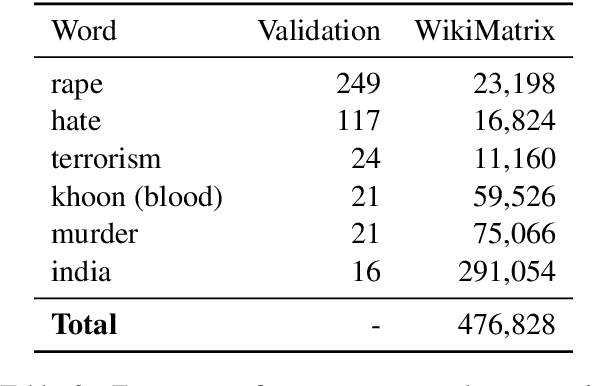
Jun 01, 2022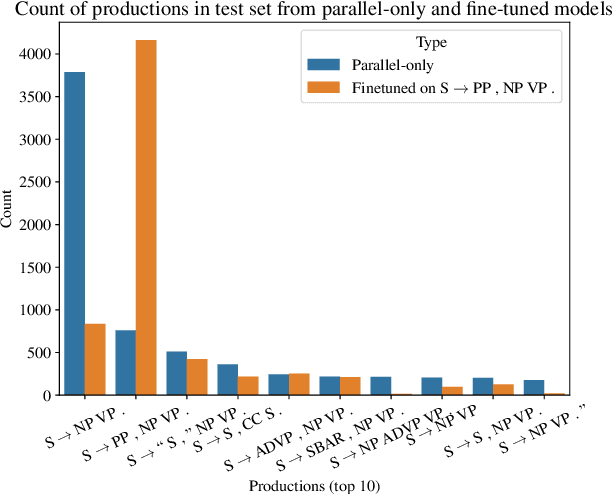
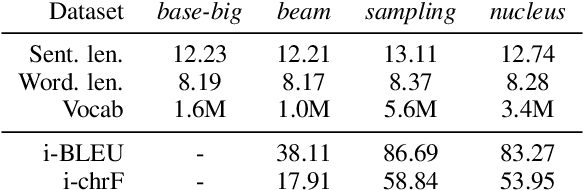
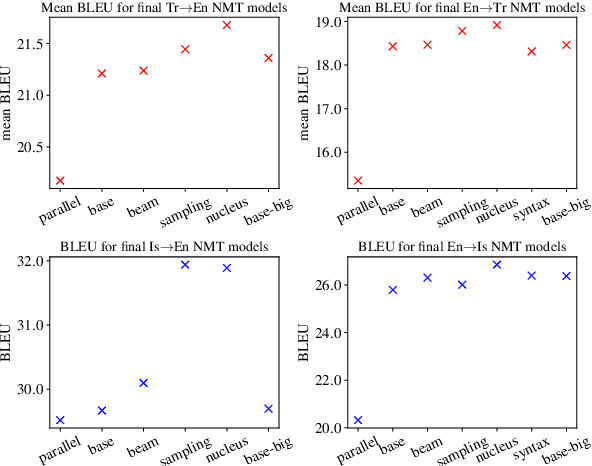
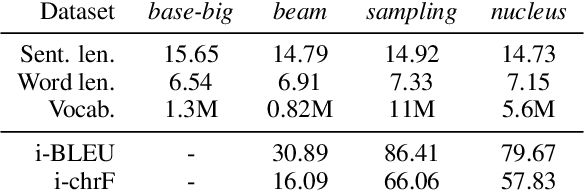
Back translation is one of the most widely used methods for improving the performance of neural machine translation systems. Recent research has sought to enhance the effectiveness of this method by increasing the 'diversity' of the generated translations. We argue that the definitions and metrics used to quantify 'diversity' in previous work have been insufficient. This work puts forward a more nuanced framework for understanding diversity in training data, splitting it into lexical diversity and syntactic diversity. We present novel metrics for measuring these different aspects of diversity and carry out empirical analysis into the effect of these types of diversity on final neural machine translation model performance for low-resource English$\leftrightarrow$Turkish and mid-resource English$\leftrightarrow$Icelandic. Our findings show that generating back translation using nucleus sampling results in higher final model performance, and that this method of generation has high levels of both lexical and syntactic diversity. We also find evidence that lexical diversity is more important than syntactic for back translation performance.
Querent Intent in Multi-Sentence Questions
Oct 18, 2020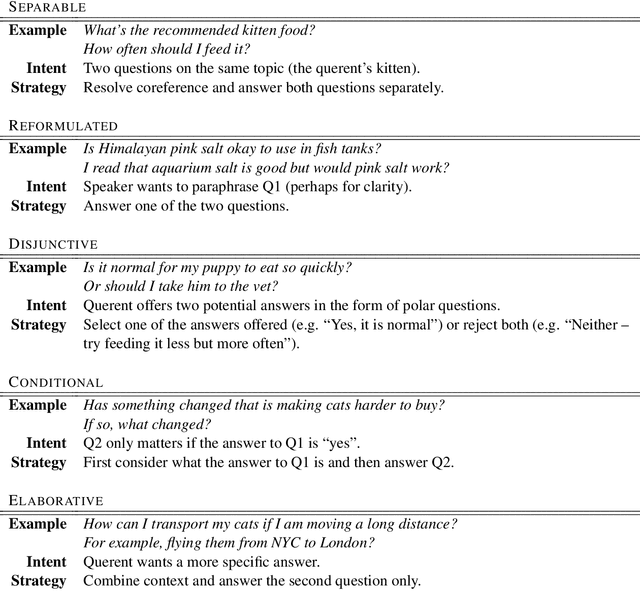
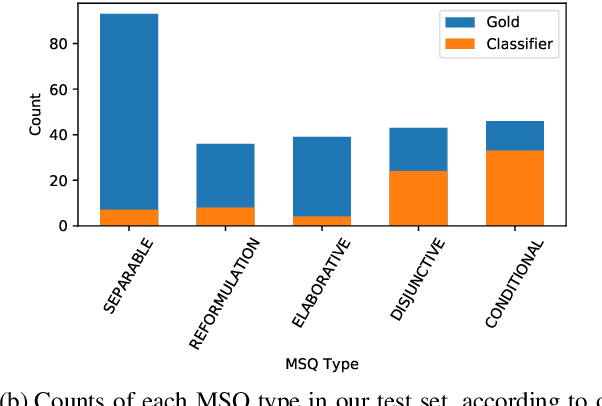

Multi-sentence questions (MSQs) are sequences of questions connected by relations which, unlike sequences of standalone questions, need to be answered as a unit. Following Rhetorical Structure Theory (RST), we recognise that different "question discourse relations" between the subparts of MSQs reflect different speaker intents, and consequently elicit different answering strategies. Correctly identifying these relations is therefore a crucial step in automatically answering MSQs. We identify five different types of MSQs in English, and define five novel relations to describe them. We extract over 162,000 MSQs from Stack Exchange to enable future research. Finally, we implement a high-precision baseline classifier based on surface features.