 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe University of Edinburgh's Submission to the WMT22 Code-Mixing Shared Task
Oct 20, 2022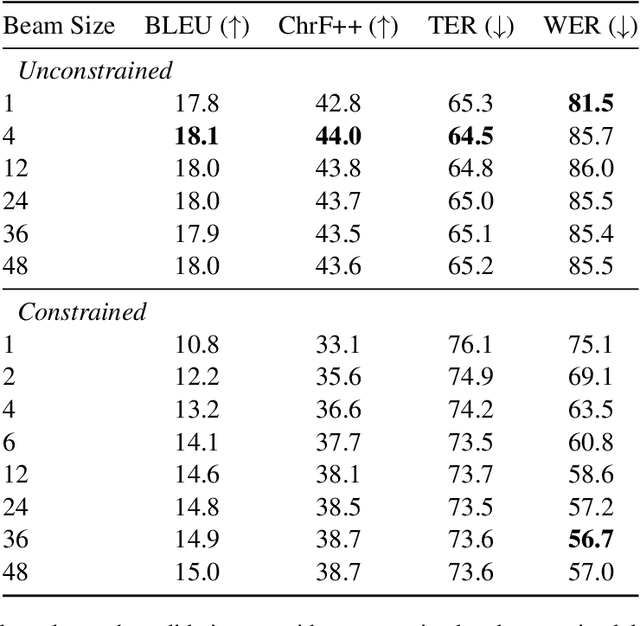
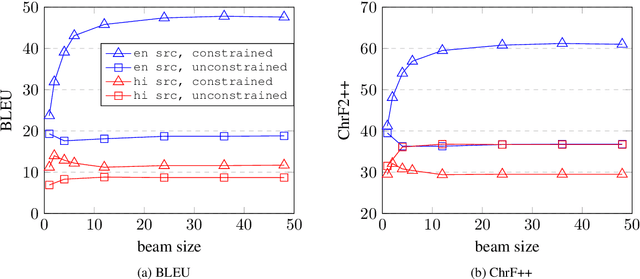
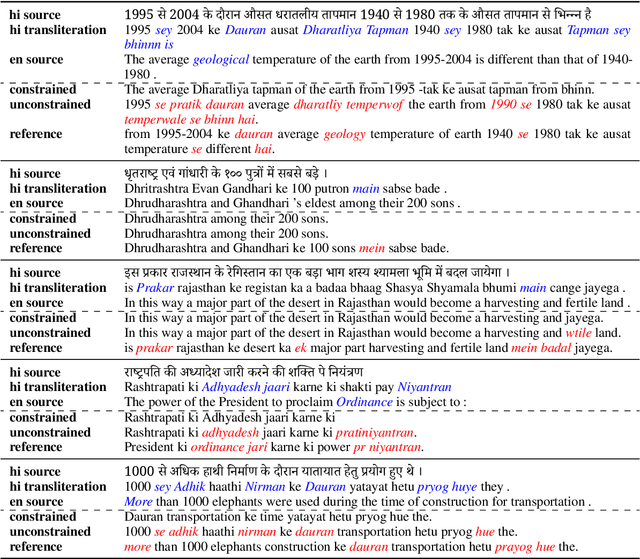
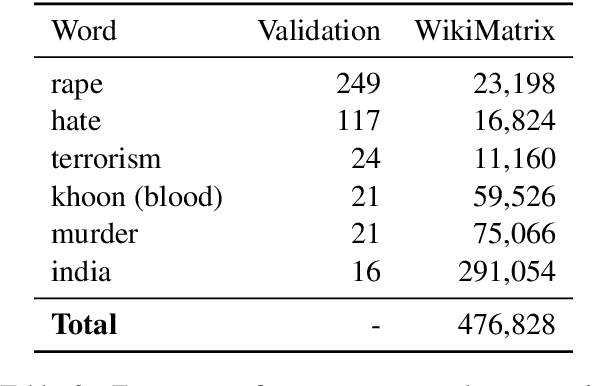
The University of Edinburgh participated in the WMT22 shared task on code-mixed translation. This consists of two subtasks: i) generating code-mixed Hindi/English (Hinglish) text generation from parallel Hindi and English sentences and ii) machine translation from Hinglish to English. As both subtasks are considered low-resource, we focused our efforts on careful data generation and curation, especially the use of backtranslation from monolingual resources. For subtask 1 we explored the effects of constrained decoding on English and transliterated subwords in order to produce Hinglish. For subtask 2, we investigated different pretraining techniques, namely comparing simple initialisation from existing machine translation models and aligned augmentation. For both subtasks, we found that our baseline systems worked best. Our systems for both subtasks were one of the overall top-performing submissions.
PMIndia -- A Collection of Parallel Corpora of Languages of India
Jan 27, 2020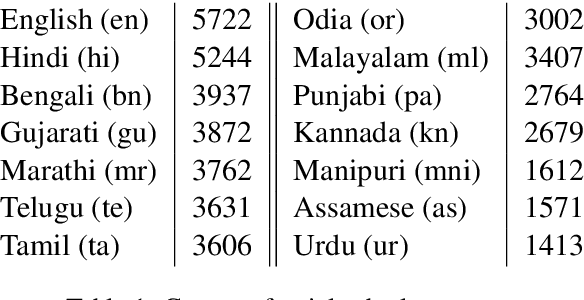
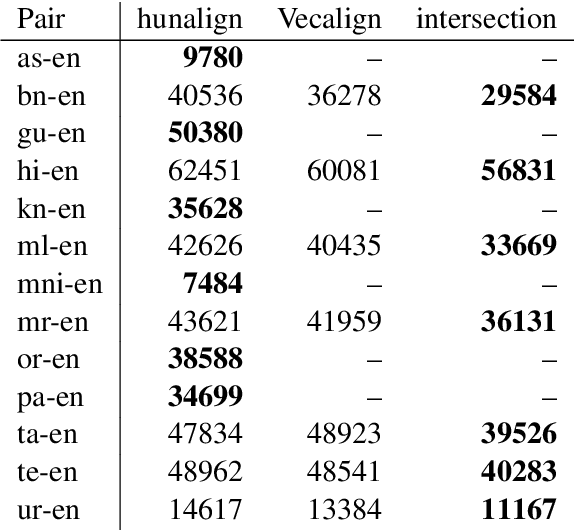
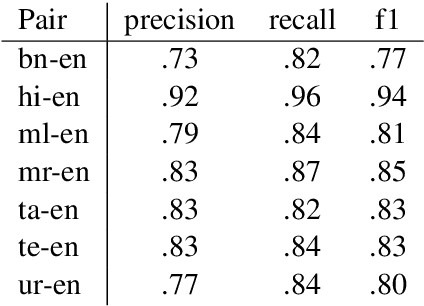

Parallel text is required for building high-quality machine translation (MT) systems, as well as for other multilingual NLP applications. For many South Asian languages, such data is in short supply. In this paper, we described a new publicly available corpus (PMIndia) consisting of parallel sentences which pair 13 major languages of India with English. The corpus includes up to 56000 sentences for each language pair. We explain how the corpus was constructed, including an assessment of two different automatic sentence alignment methods, and present some initial NMT results on the corpus.
The University of Edinburgh's Submissions to the WMT19 News Translation Task
Jul 12, 2019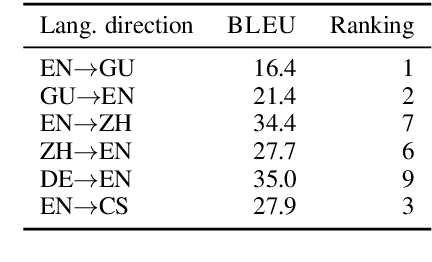
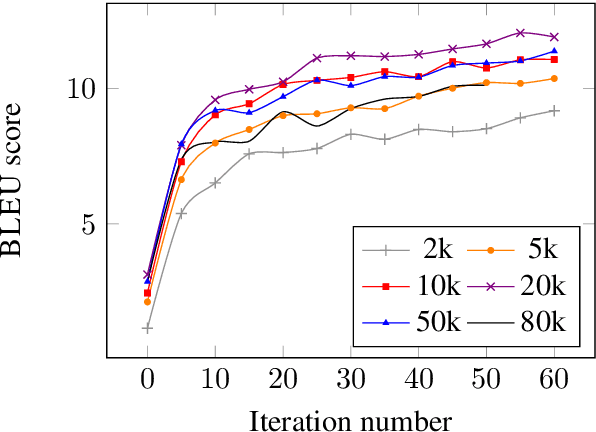
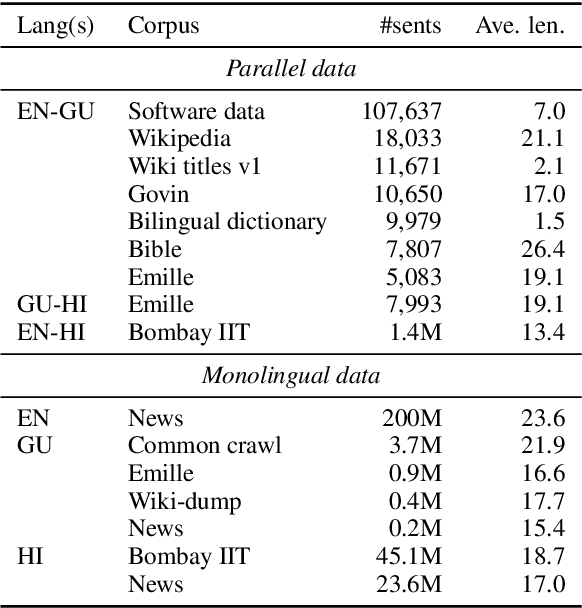

The University of Edinburgh participated in the WMT19 Shared Task on News Translation in six language directions: English-to-Gujarati, Gujarati-to-English, English-to-Chinese, Chinese-to-English, German-to-English, and English-to-Czech. For all translation directions, we created or used back-translations of monolingual data in the target language as additional synthetic training data. For English-Gujarati, we also explored semi-supervised MT with cross-lingual language model pre-training, and translation pivoting through Hindi. For translation to and from Chinese, we investigated character-based tokenisation vs. sub-word segmentation of Chinese text. For German-to-English, we studied the impact of vast amounts of back-translated training data on translation quality, gaining a few additional insights over Edunov et al. (2018). For English-to-Czech, we compared different pre-processing and tokenisation regimes.