Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePMIndia -- A Collection of Parallel Corpora of Languages of India
Paper and Code
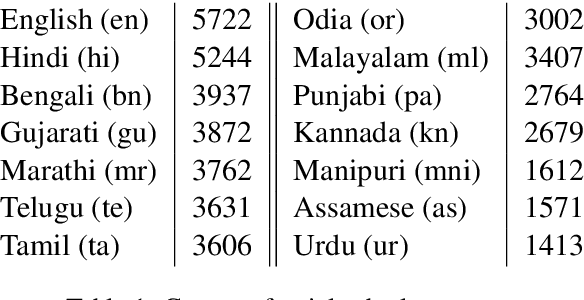
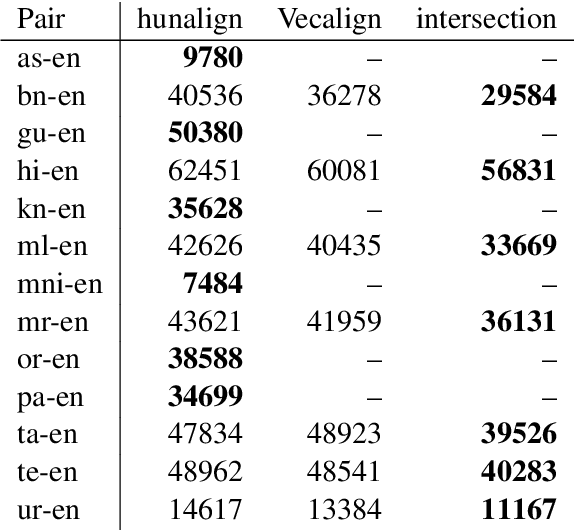
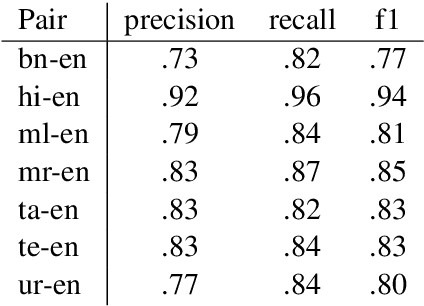

Parallel text is required for building high-quality machine translation (MT) systems, as well as for other multilingual NLP applications. For many South Asian languages, such data is in short supply. In this paper, we described a new publicly available corpus (PMIndia) consisting of parallel sentences which pair 13 major languages of India with English. The corpus includes up to 56000 sentences for each language pair. We explain how the corpus was constructed, including an assessment of two different automatic sentence alignment methods, and present some initial NMT results on the corpus.
View paper on