 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEAR: Pairwise Evaluation for Automatic Relative Scoring in Machine Translation
Jan 25, 2026We present PEAR (Pairwise Evaluation for Automatic Relative Scoring), a supervised Quality Estimation (QE) metric family that reframes reference-free Machine Translation (MT) evaluation as a graded pairwise comparison. Given a source segment and two candidate translations, PEAR predicts the direction and magnitude of their quality difference. The metrics are trained using pairwise supervision derived from differences in human judgments, with an additional regularization term that encourages sign inversion under candidate order reversal. On the WMT24 meta-evaluation benchmark, PEAR outperforms strictly matched single-candidate QE baselines trained with the same data and backbones, isolating the benefit of the proposed pairwise formulation. Despite using substantially fewer parameters than recent large metrics, PEAR surpasses far larger QE models and reference-based metrics. Our analysis further indicates that PEAR yields a less redundant evaluation signal relative to other top metrics. Finally, we show that PEAR is an effective utility function for Minimum Bayes Risk (MBR) decoding, reducing pairwise scoring cost at negligible impact.
On Instruction-Finetuning Neural Machine Translation Models
Oct 07, 2024In this work, we introduce instruction finetuning for Neural Machine Translation (NMT) models, which distills instruction following capabilities from Large Language Models (LLMs) into orders-of-magnitude smaller NMT models. Our instruction-finetuning recipe for NMT models enables customization of translations for a limited but disparate set of translation-specific tasks. We show that NMT models are capable of following multiple instructions simultaneously and demonstrate capabilities of zero-shot composition of instructions. We also show that through instruction finetuning, traditionally disparate tasks such as formality-controlled machine translation, multi-domain adaptation as well as multi-modal translations can be tackled jointly by a single instruction finetuned NMT model, at a performance level comparable to LLMs such as GPT-3.5-Turbo. To the best of our knowledge, our work is among the first to demonstrate the instruction-following capabilities of traditional NMT models, which allows for faster, cheaper and more efficient serving of customized translations.
PyMarian: Fast Neural Machine Translation and Evaluation in Python
Aug 15, 2024



The deep learning language of choice these days is Python; measured by factors such as available libraries and technical support, it is hard to beat. At the same time, software written in lower-level programming languages like C++ retain advantages in speed. We describe a Python interface to Marian NMT, a C++-based training and inference toolkit for sequence-to-sequence models, focusing on machine translation. This interface enables models trained with Marian to be connected to the rich, wide range of tools available in Python. A highlight of the interface is the ability to compute state-of-the-art COMET metrics from Python but using Marian's inference engine, with a speedup factor of up to 7.8$\times$ the existing implementations. We also briefly spotlight a number of other integrations, including Jupyter notebooks, connection with prebuilt models, and a web app interface provided with the package. PyMarian is available in PyPI via $\texttt{pip install pymarian}$.
Preliminary WMT24 Ranking of General MT Systems and LLMs
Jul 29, 2024



This is the preliminary ranking of WMT24 General MT systems based on automatic metrics. The official ranking will be a human evaluation, which is superior to the automatic ranking and supersedes it. The purpose of this report is not to interpret any findings but only provide preliminary results to the participants of the General MT task that may be useful during the writing of the system submission.
Error Span Annotation: A Balanced Approach for Human Evaluation of Machine Translation
Jun 17, 2024



High-quality Machine Translation (MT) evaluation relies heavily on human judgments. Comprehensive error classification methods, such as Multidimensional Quality Metrics (MQM), are expensive as they are time-consuming and can only be done by experts, whose availability may be limited especially for low-resource languages. On the other hand, just assigning overall scores, like Direct Assessment (DA), is simpler and faster and can be done by translators of any level, but are less reliable. In this paper, we introduce Error Span Annotation (ESA), a human evaluation protocol which combines the continuous rating of DA with the high-level error severity span marking of MQM. We validate ESA by comparing it to MQM and DA for 12 MT systems and one human reference translation (English to German) from WMT23. The results show that ESA offers faster and cheaper annotations than MQM at the same quality level, without the requirement of expensive MQM experts.
SOTASTREAM: A Streaming Approach to Machine Translation Training
Aug 14, 2023



Many machine translation toolkits make use of a data preparation step wherein raw data is transformed into a tensor format that can be used directly by the trainer. This preparation step is increasingly at odds with modern research and development practices because this process produces a static, unchangeable version of the training data, making common training-time needs difficult (e.g., subword sampling), time-consuming (preprocessing with large data can take days), expensive (e.g., disk space), and cumbersome (managing experiment combinatorics). We propose an alternative approach that separates the generation of data from the consumption of that data. In this approach, there is no separate pre-processing step; data generation produces an infinite stream of permutations of the raw training data, which the trainer tensorizes and batches as it is consumed. Additionally, this data stream can be manipulated by a set of user-definable operators that provide on-the-fly modifications, such as data normalization, augmentation or filtering. We release an open-source toolkit, SOTASTREAM, that implements this approach: https://github.com/marian-nmt/sotastream. We show that it cuts training time, adds flexibility, reduces experiment management complexity, and reduces disk space, all without affecting the accuracy of the trained models.
To Ship or Not to Ship: An Extensive Evaluation of Automatic Metrics for Machine Translation
Jul 22, 2021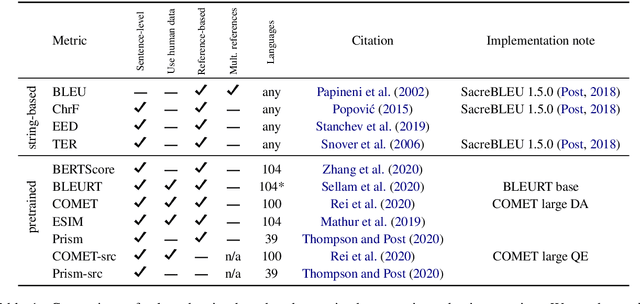
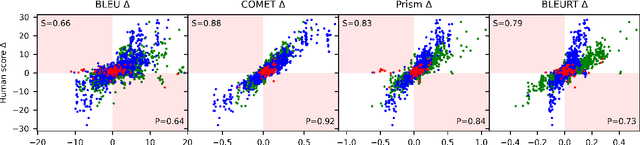
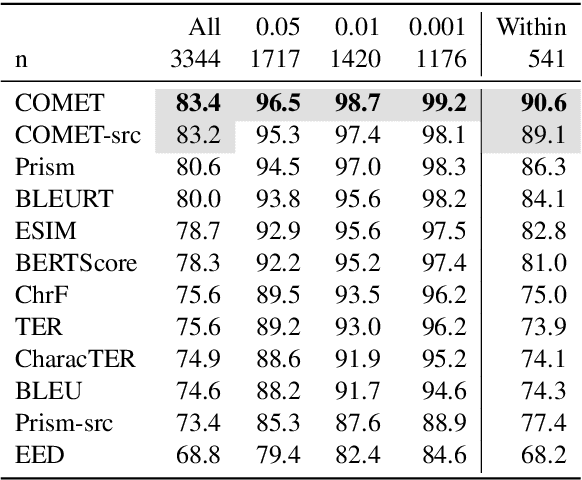
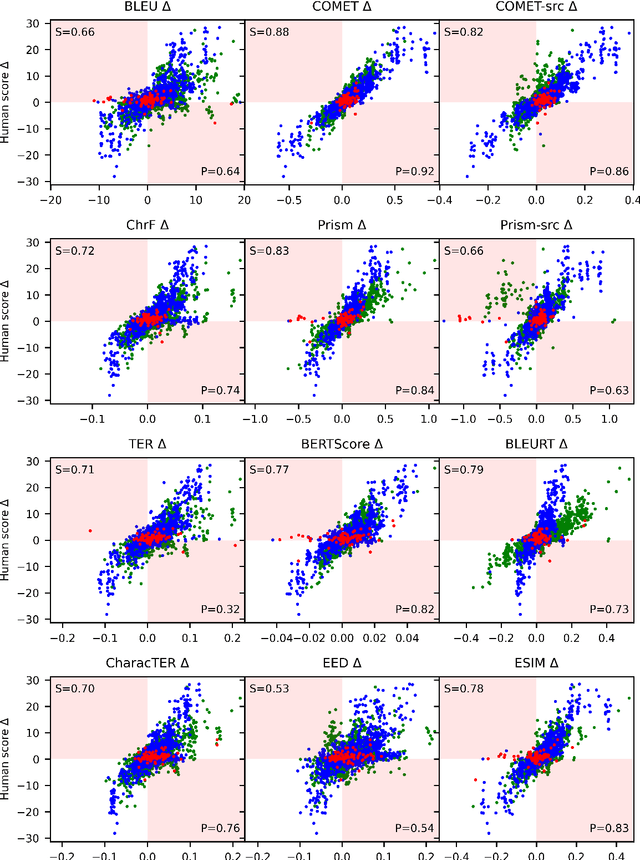
Automatic metrics are commonly used as the exclusive tool for declaring the superiority of one machine translation system's quality over another. The community choice of automatic metric guides research directions and industrial developments by deciding which models are deemed better. Evaluating metrics correlations has been limited to a small collection of human judgements. In this paper, we corroborate how reliable metrics are in contrast to human judgements on - to the best of our knowledge - the largest collection of human judgements. We investigate which metrics have the highest accuracy to make system-level quality rankings for pairs of systems, taking human judgement as a gold standard, which is the closest scenario to the real metric usage. Furthermore, we evaluate the performance of various metrics across different language pairs and domains. Lastly, we show that the sole use of BLEU negatively affected the past development of improved models. We release the collection of human judgements of 4380 systems, and 2.3 M annotated sentences for further analysis and replication of our work.
On User Interfaces for Large-Scale Document-Level Human Evaluation of Machine Translation Outputs
Apr 21, 2021
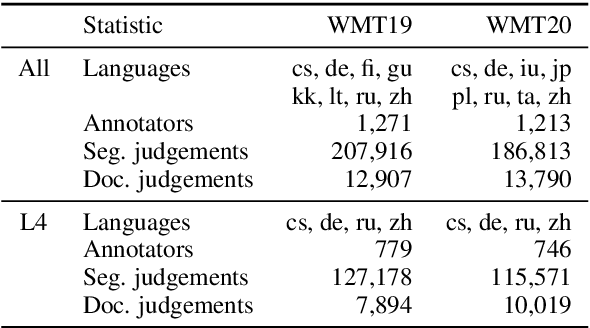
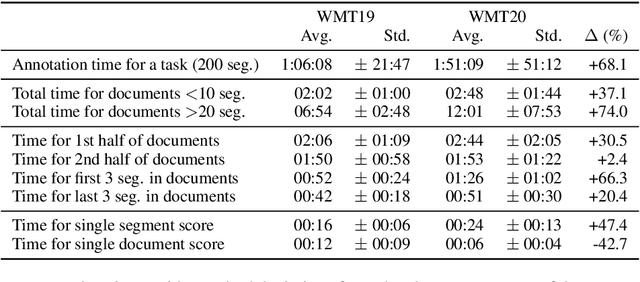
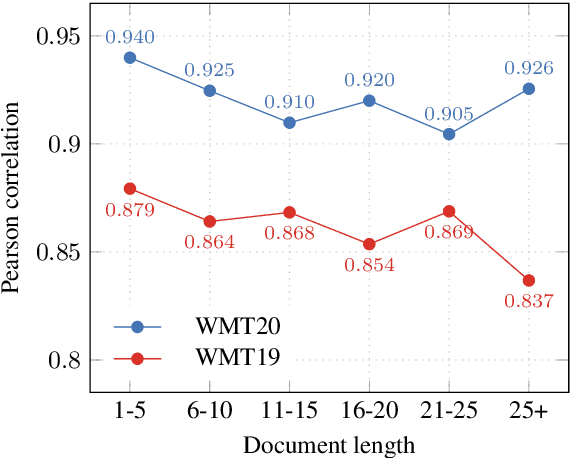
Recent studies emphasize the need of document context in human evaluation of machine translations, but little research has been done on the impact of user interfaces on annotator productivity and the reliability of assessments. In this work, we compare human assessment data from the last two WMT evaluation campaigns collected via two different methods for document-level evaluation. Our analysis shows that a document-centric approach to evaluation where the annotator is presented with the entire document context on a screen leads to higher quality segment and document level assessments. It improves the correlation between segment and document scores and increases inter-annotator agreement for document scores but is considerably more time consuming for annotators.
The University of Edinburgh's Submissions to the WMT19 News Translation Task
Jul 12, 2019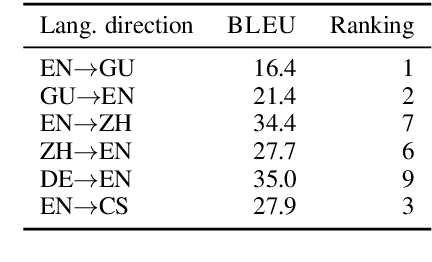
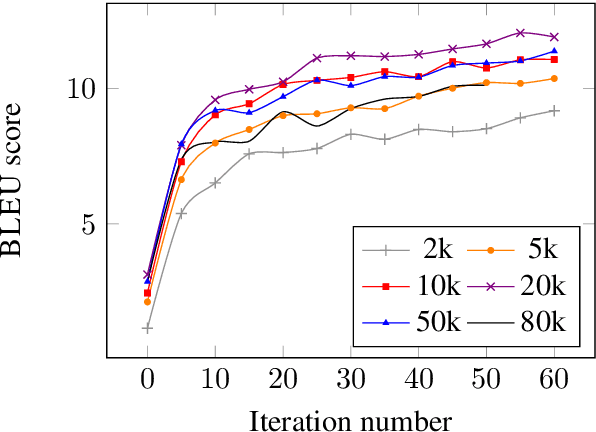
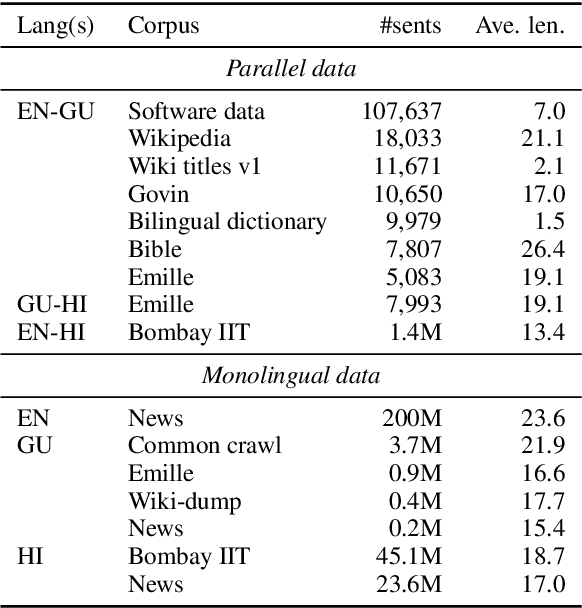

The University of Edinburgh participated in the WMT19 Shared Task on News Translation in six language directions: English-to-Gujarati, Gujarati-to-English, English-to-Chinese, Chinese-to-English, German-to-English, and English-to-Czech. For all translation directions, we created or used back-translations of monolingual data in the target language as additional synthetic training data. For English-Gujarati, we also explored semi-supervised MT with cross-lingual language model pre-training, and translation pivoting through Hindi. For translation to and from Chinese, we investigated character-based tokenisation vs. sub-word segmentation of Chinese text. For German-to-English, we studied the impact of vast amounts of back-translated training data on translation quality, gaining a few additional insights over Edunov et al. (2018). For English-to-Czech, we compared different pre-processing and tokenisation regimes.
MS-UEdin Submission to the WMT2018 APE Shared Task: Dual-Source Transformer for Automatic Post-Editing
Sep 01, 2018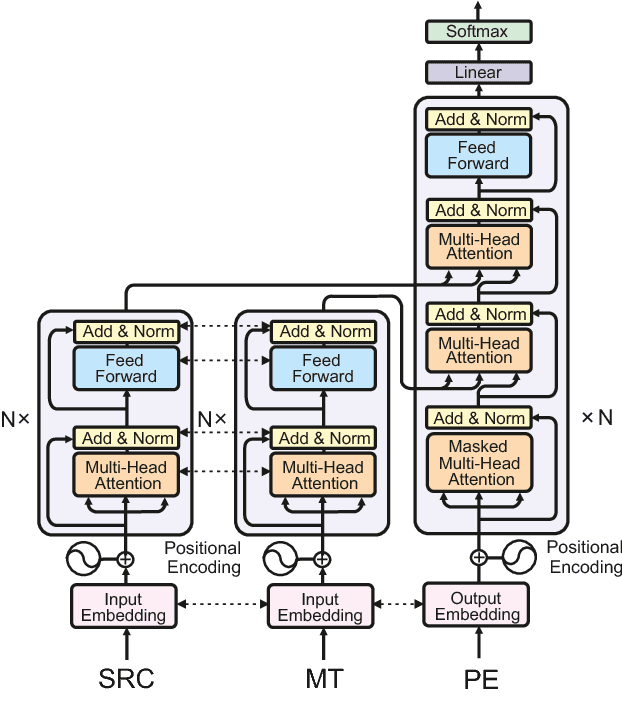
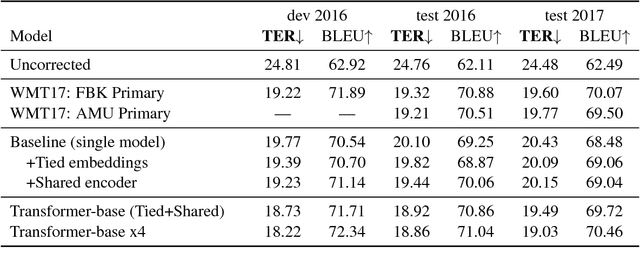
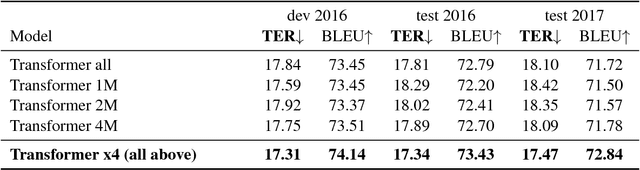
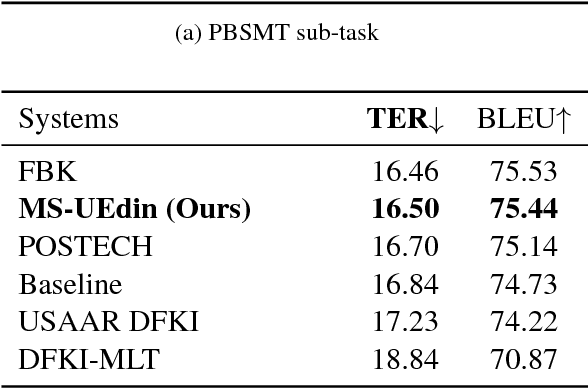
This paper describes the Microsoft and University of Edinburgh submission to the Automatic Post-editing shared task at WMT2018. Based on training data and systems from the WMT2017 shared task, we re-implement our own models from the last shared task and introduce improvements based on extensive parameter sharing. Next we experiment with our implementation of dual-source transformer models and data selection for the IT domain. Our submissions decisively wins the SMT post-editing sub-task establishing the new state-of-the-art and is a very close second (or equal, 16.46 vs 16.50 TER) in the NMT sub-task. Based on the rather weak results in the NMT sub-task, we hypothesize that neural-on-neural APE might not be actually useful.