Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarian: Cost-effective High-Quality Neural Machine Translation in C++
Paper and Code
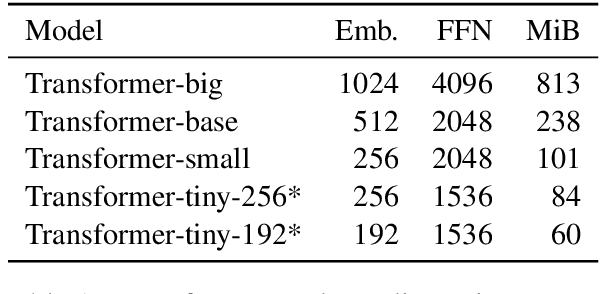
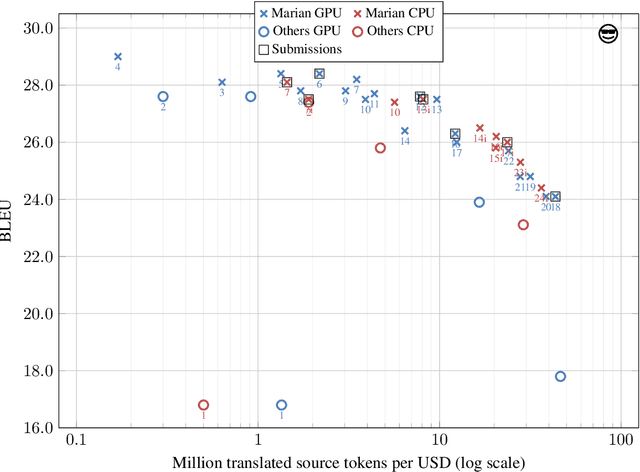
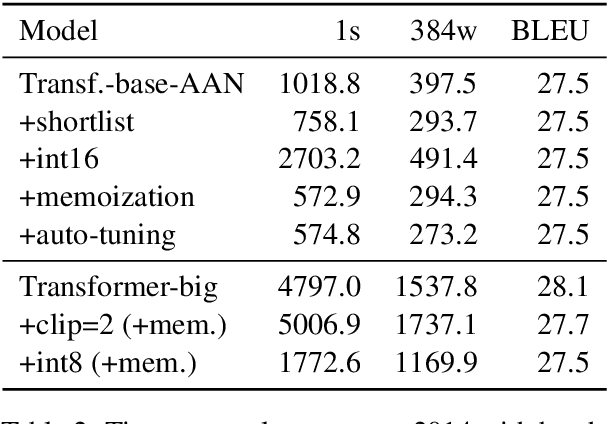
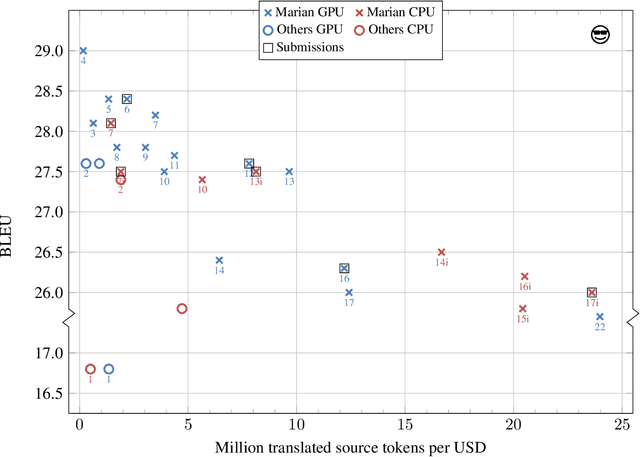
This paper describes the submissions of the "Marian" team to the WNMT 2018 shared task. We investigate combinations of teacher-student training, low-precision matrix products, auto-tuning and other methods to optimize the Transformer model on GPU and CPU. By further integrating these methods with the new averaging attention networks, a recently introduced faster Transformer variant, we create a number of high-quality, high-performance models on the GPU and CPU, dominating the Pareto frontier for this shared task.
* System submission to the Workshop for Neural Machine Translation
2018, efficiency task
View paper on