 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Ship or Not to Ship: An Extensive Evaluation of Automatic Metrics for Machine Translation
Paper and Code
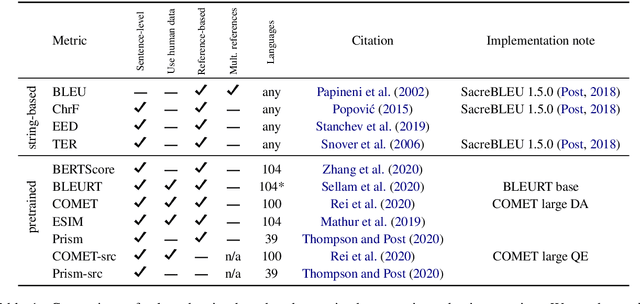
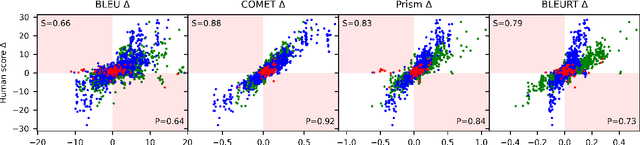
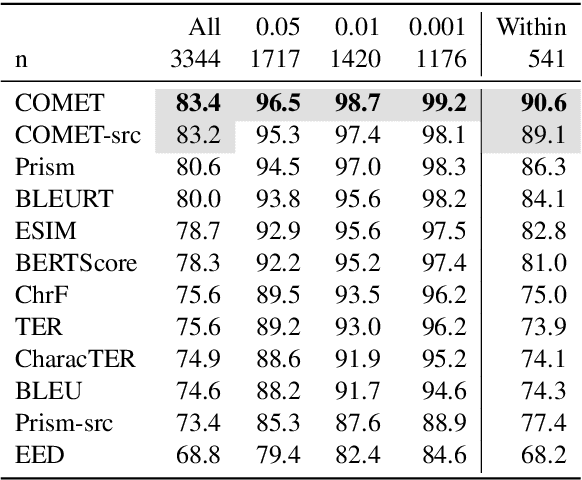
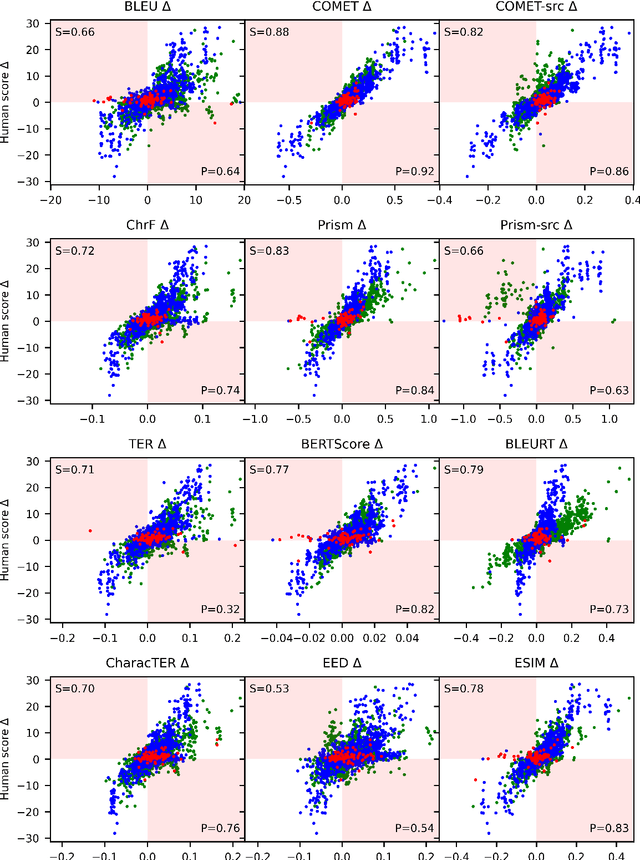
Automatic metrics are commonly used as the exclusive tool for declaring the superiority of one machine translation system's quality over another. The community choice of automatic metric guides research directions and industrial developments by deciding which models are deemed better. Evaluating metrics correlations has been limited to a small collection of human judgements. In this paper, we corroborate how reliable metrics are in contrast to human judgements on - to the best of our knowledge - the largest collection of human judgements. We investigate which metrics have the highest accuracy to make system-level quality rankings for pairs of systems, taking human judgement as a gold standard, which is the closest scenario to the real metric usage. Furthermore, we evaluate the performance of various metrics across different language pairs and domains. Lastly, we show that the sole use of BLEU negatively affected the past development of improved models. We release the collection of human judgements of 4380 systems, and 2.3 M annotated sentences for further analysis and replication of our work.