 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyMarian: Fast Neural Machine Translation and Evaluation in Python
Aug 15, 2024



The deep learning language of choice these days is Python; measured by factors such as available libraries and technical support, it is hard to beat. At the same time, software written in lower-level programming languages like C++ retain advantages in speed. We describe a Python interface to Marian NMT, a C++-based training and inference toolkit for sequence-to-sequence models, focusing on machine translation. This interface enables models trained with Marian to be connected to the rich, wide range of tools available in Python. A highlight of the interface is the ability to compute state-of-the-art COMET metrics from Python but using Marian's inference engine, with a speedup factor of up to 7.8$\times$ the existing implementations. We also briefly spotlight a number of other integrations, including Jupyter notebooks, connection with prebuilt models, and a web app interface provided with the package. PyMarian is available in PyPI via $\texttt{pip install pymarian}$.
Improving Word Sense Disambiguation in Neural Machine Translation with Salient Document Context
Nov 27, 2023Lexical ambiguity is a challenging and pervasive problem in machine translation (\mt). We introduce a simple and scalable approach to resolve translation ambiguity by incorporating a small amount of extra-sentential context in neural \mt. Our approach requires no sense annotation and no change to standard model architectures. Since actual document context is not available for the vast majority of \mt training data, we collect related sentences for each input to construct pseudo-documents. Salient words from pseudo-documents are then encoded as a prefix to each source sentence to condition the generation of the translation. To evaluate, we release \docmucow, a challenge set for translation disambiguation based on the English-German \mucow \cite{raganato-etal-2020-evaluation} augmented with document IDs. Extensive experiments show that our method translates ambiguous source words better than strong sentence-level baselines and comparable document-level baselines while reducing training costs.
Additive Interventions Yield Robust Multi-Domain Machine Translation Models
Oct 23, 2022



Additive interventions are a recently-proposed mechanism for controlling target-side attributes in neural machine translation. In contrast to tag-based approaches which manipulate the raw source sequence, interventions work by directly modulating the encoder representation of all tokens in the sequence. We examine the role of additive interventions in a large-scale multi-domain machine translation setting and compare its performance in various inference scenarios. We find that while the performance difference is small between intervention-based systems and tag-based systems when the domain label matches the test domain, intervention-based systems are robust to label error, making them an attractive choice under label uncertainty. Further, we find that the superiority of single-domain fine-tuning comes under question when training data size is scaled, contradicting previous findings.
Controlling Translation Formality Using Pre-trained Multilingual Language Models
May 13, 2022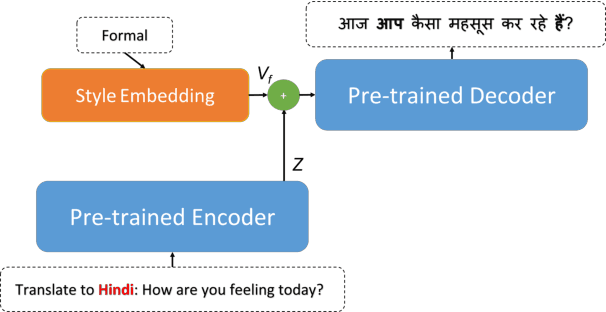
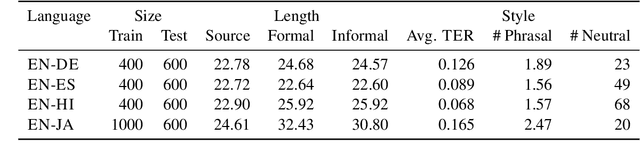
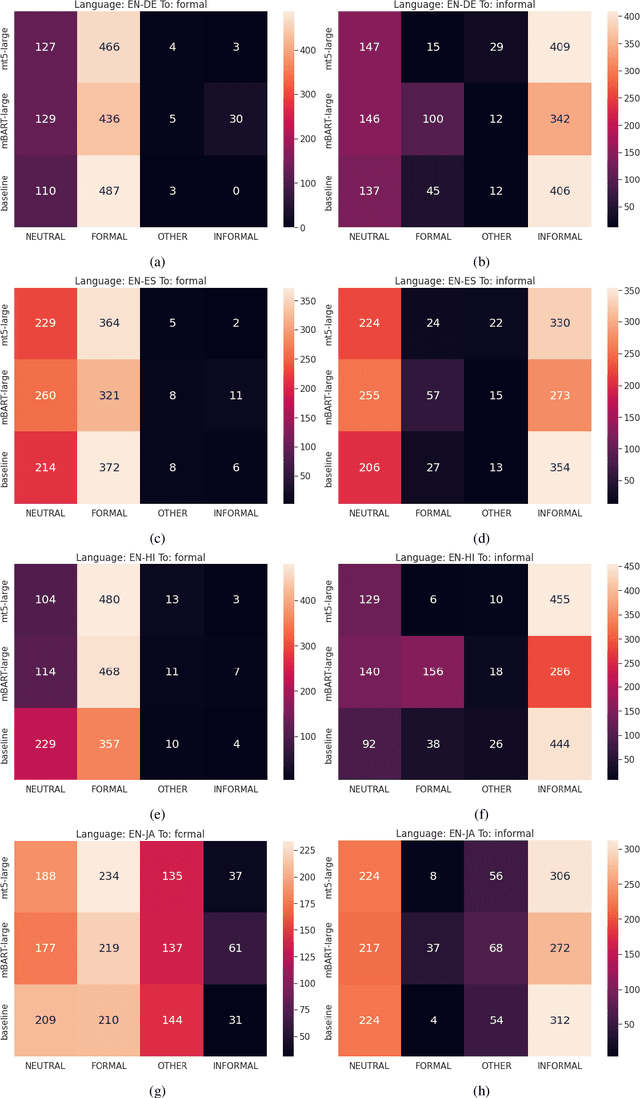

This paper describes the University of Maryland's submission to the Special Task on Formality Control for Spoken Language Translation at \iwslt, which evaluates translation from English into 6 languages with diverse grammatical formality markers. We investigate to what extent this problem can be addressed with a \textit{single multilingual model}, simultaneously controlling its output for target language and formality. Results show that this strategy can approach the translation quality and formality control achieved by dedicated translation models. However, the nature of the underlying pre-trained language model and of the finetuning samples greatly impact results.