 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurvey of Low-Resource Machine Translation
Sep 01, 2021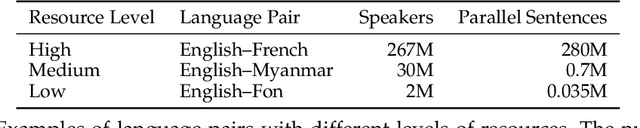
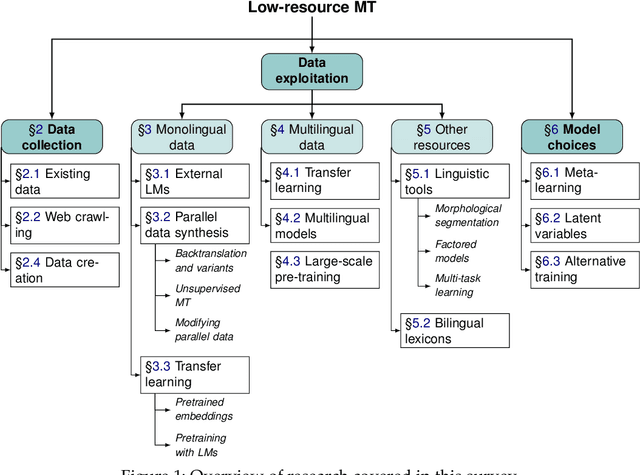
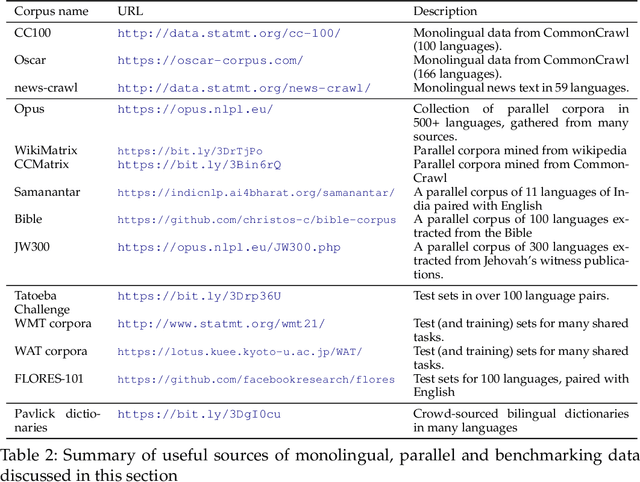
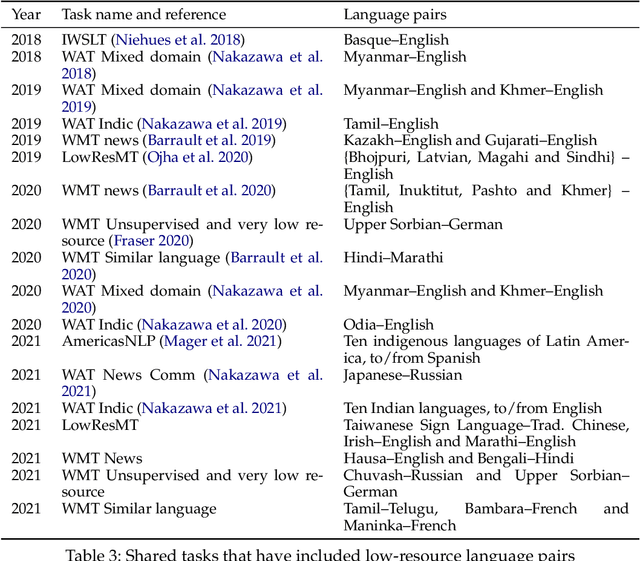
We present a survey covering the state of the art in low-resource machine translation. There are currently around 7000 languages spoken in the world and almost all language pairs lack significant resources for training machine translation models. There has been increasing interest in research addressing the challenge of producing useful translation models when very little translated training data is available. We present a high level summary of this topical field and provide an overview of best practices.
The University of Edinburgh's Submissions to the WMT19 News Translation Task
Jul 12, 2019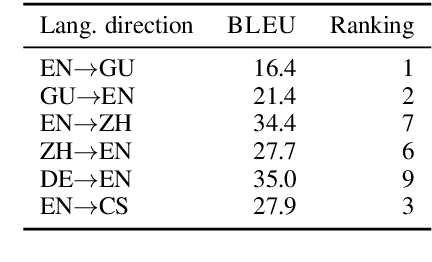
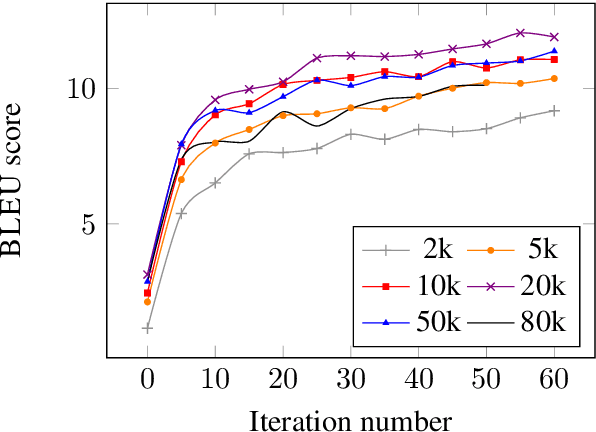
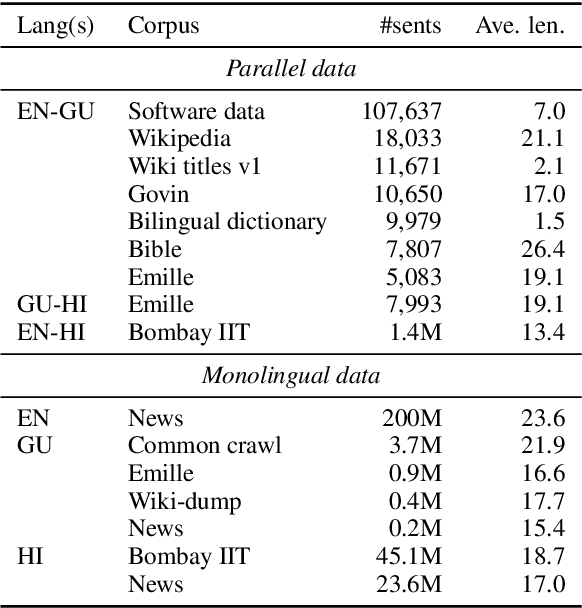

The University of Edinburgh participated in the WMT19 Shared Task on News Translation in six language directions: English-to-Gujarati, Gujarati-to-English, English-to-Chinese, Chinese-to-English, German-to-English, and English-to-Czech. For all translation directions, we created or used back-translations of monolingual data in the target language as additional synthetic training data. For English-Gujarati, we also explored semi-supervised MT with cross-lingual language model pre-training, and translation pivoting through Hindi. For translation to and from Chinese, we investigated character-based tokenisation vs. sub-word segmentation of Chinese text. For German-to-English, we studied the impact of vast amounts of back-translated training data on translation quality, gaining a few additional insights over Edunov et al. (2018). For English-to-Czech, we compared different pre-processing and tokenisation regimes.
Low-rank passthrough neural networks
Jul 09, 2018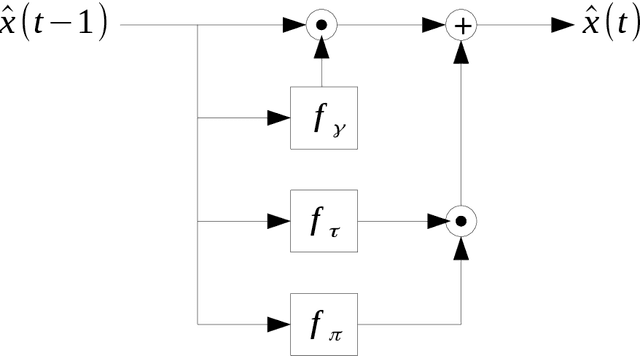
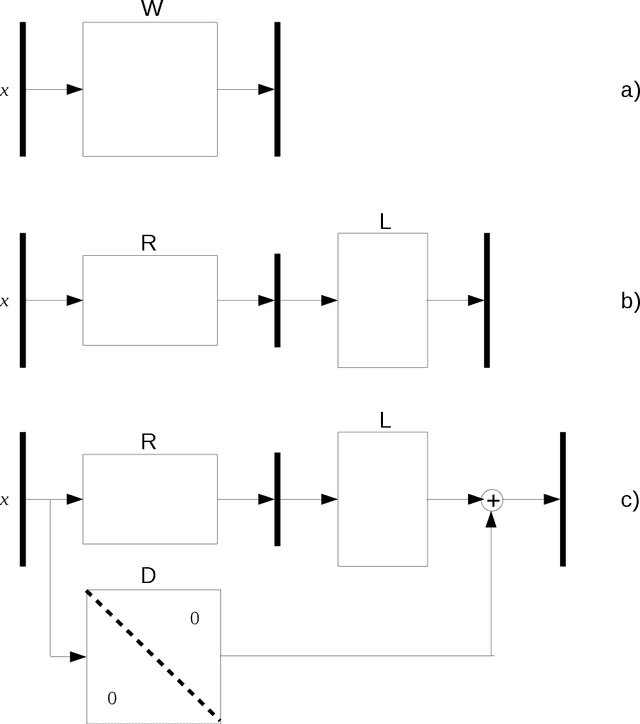
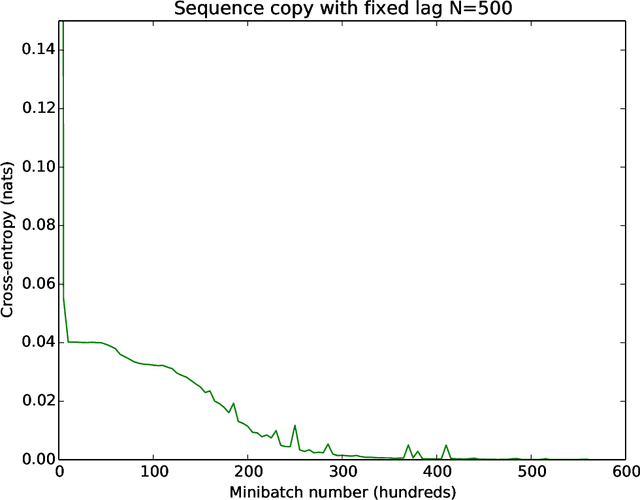
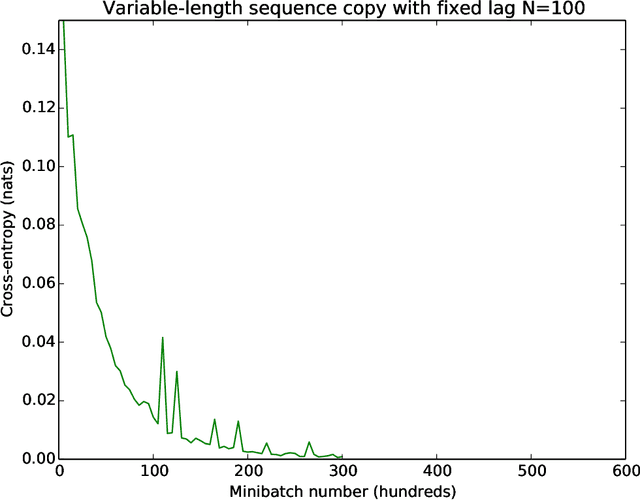
Various common deep learning architectures, such as LSTMs, GRUs, Resnets and Highway Networks, employ state passthrough connections that support training with high feed-forward depth or recurrence over many time steps. These "Passthrough Networks" architectures also enable the decoupling of the network state size from the number of parameters of the network, a possibility has been studied by \newcite{Sak2014} with their low-rank parametrization of the LSTM. In this work we extend this line of research, proposing effective, low-rank and low-rank plus diagonal matrix parametrizations for Passthrough Networks which exploit this decoupling property, reducing the data complexity and memory requirements of the network while preserving its memory capacity. This is particularly beneficial in low-resource settings as it supports expressive models with a compact parametrization less susceptible to overfitting. We present competitive experimental results on several tasks, including language modeling and a near state of the art result on sequential randomly-permuted MNIST classification, a hard task on natural data.
The University of Edinburgh's Neural MT Systems for WMT17
Aug 02, 2017
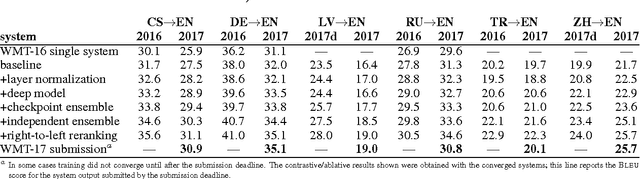
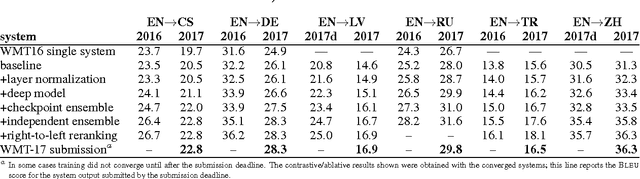
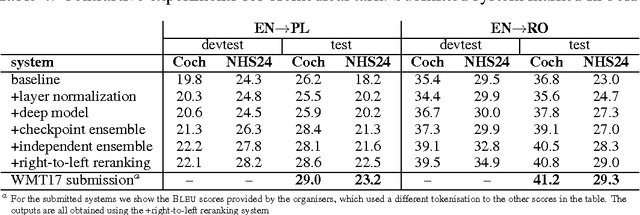
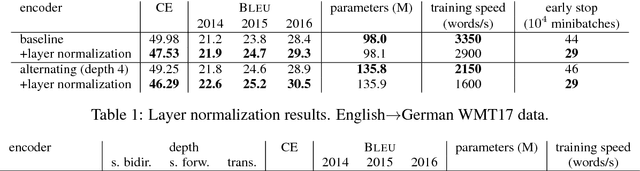
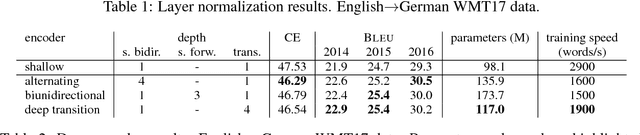
This paper describes the University of Edinburgh's submissions to the WMT17 shared news translation and biomedical translation tasks. We participated in 12 translation directions for news, translating between English and Czech, German, Latvian, Russian, Turkish and Chinese. For the biomedical task we submitted systems for English to Czech, German, Polish and Romanian. Our systems are neural machine translation systems trained with Nematus, an attentional encoder-decoder. We follow our setup from last year and build BPE-based models with parallel and back-translated monolingual training data. Novelties this year include the use of deep architectures, layer normalization, and more compact models due to weight tying and improvements in BPE segmentations. We perform extensive ablative experiments, reporting on the effectivenes of layer normalization, deep architectures, and different ensembling techniques.
Regularization techniques for fine-tuning in neural machine translation
Jul 31, 2017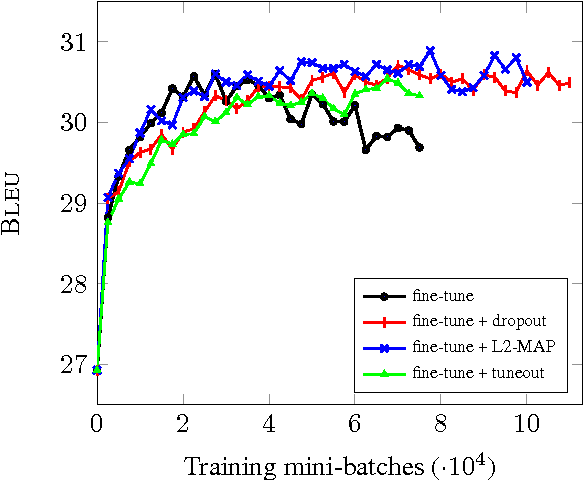
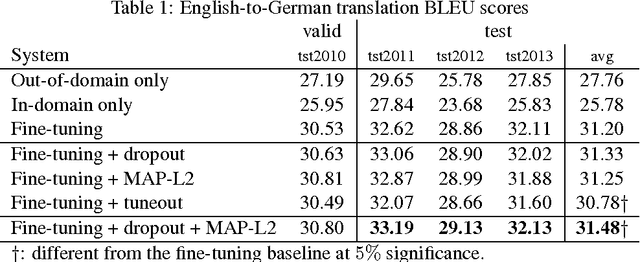
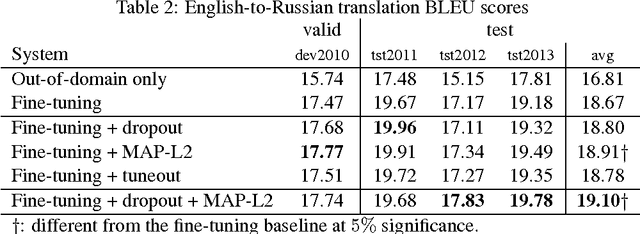
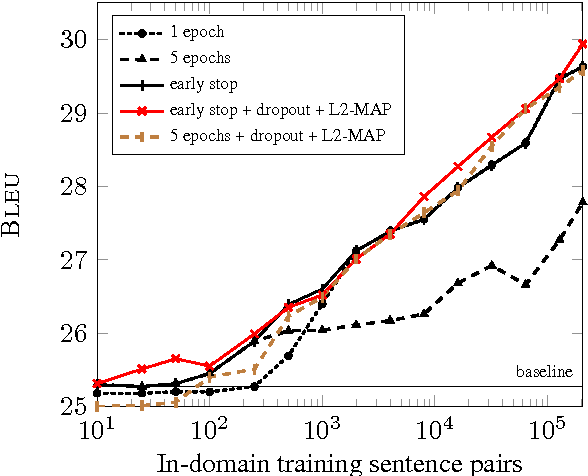
We investigate techniques for supervised domain adaptation for neural machine translation where an existing model trained on a large out-of-domain dataset is adapted to a small in-domain dataset. In this scenario, overfitting is a major challenge. We investigate a number of techniques to reduce overfitting and improve transfer learning, including regularization techniques such as dropout and L2-regularization towards an out-of-domain prior. In addition, we introduce tuneout, a novel regularization technique inspired by dropout. We apply these techniques, alone and in combination, to neural machine translation, obtaining improvements on IWSLT datasets for English->German and English->Russian. We also investigate the amounts of in-domain training data needed for domain adaptation in NMT, and find a logarithmic relationship between the amount of training data and gain in BLEU score.
Deep Architectures for Neural Machine Translation
Jul 24, 2017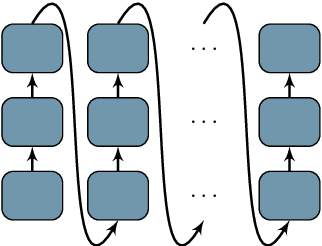
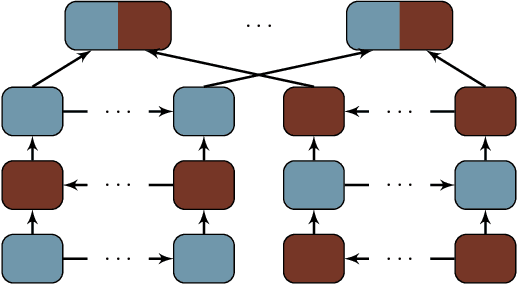
It has been shown that increasing model depth improves the quality of neural machine translation. However, different architectural variants to increase model depth have been proposed, and so far, there has been no thorough comparative study. In this work, we describe and evaluate several existing approaches to introduce depth in neural machine translation. Additionally, we explore novel architectural variants, including deep transition RNNs, and we vary how attention is used in the deep decoder. We introduce a novel "BiDeep" RNN architecture that combines deep transition RNNs and stacked RNNs. Our evaluation is carried out on the English to German WMT news translation dataset, using a single-GPU machine for both training and inference. We find that several of our proposed architectures improve upon existing approaches in terms of speed and translation quality. We obtain best improvements with a BiDeep RNN of combined depth 8, obtaining an average improvement of 1.5 BLEU over a strong shallow baseline. We release our code for ease of adoption.
A parallel corpus of Python functions and documentation strings for automated code documentation and code generation
Jul 07, 2017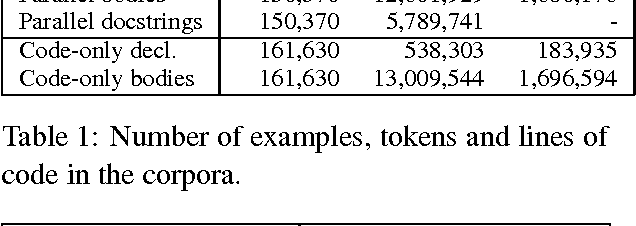

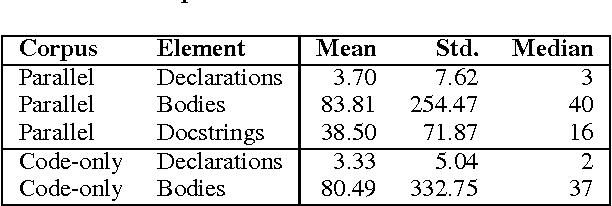
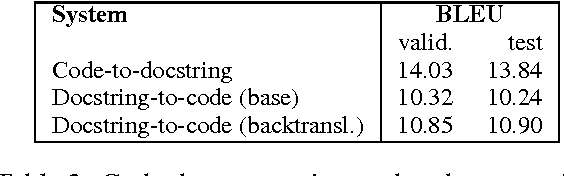
Automated documentation of programming source code and automated code generation from natural language are challenging tasks of both practical and scientific interest. Progress in these areas has been limited by the low availability of parallel corpora of code and natural language descriptions, which tend to be small and constrained to specific domains. In this work we introduce a large and diverse parallel corpus of a hundred thousands Python functions with their documentation strings ("docstrings") generated by scraping open source repositories on GitHub. We describe baseline results for the code documentation and code generation tasks obtained by neural machine translation. We also experiment with data augmentation techniques to further increase the amount of training data. We release our datasets and processing scripts in order to stimulate research in these areas.
Nematus: a Toolkit for Neural Machine Translation
Mar 13, 2017
We present Nematus, a toolkit for Neural Machine Translation. The toolkit prioritizes high translation accuracy, usability, and extensibility. Nematus has been used to build top-performing submissions to shared translation tasks at WMT and IWSLT, and has been used to train systems for production environments.
Towards cross-lingual distributed representations without parallel text trained with adversarial autoencoders
Aug 09, 2016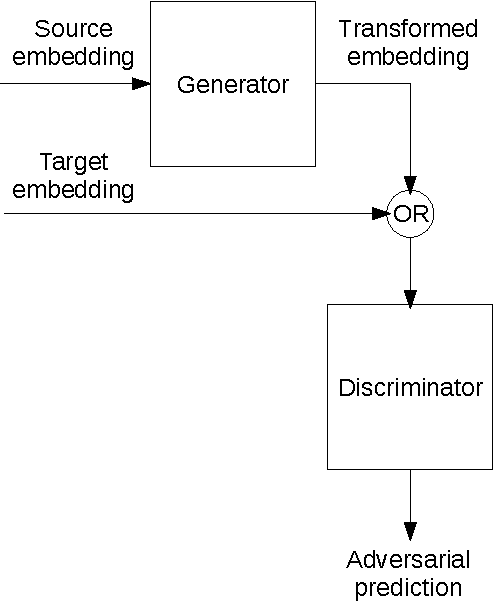
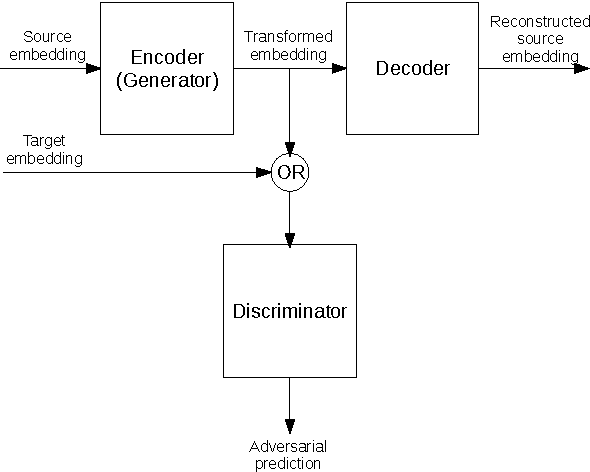
Current approaches to learning vector representations of text that are compatible between different languages usually require some amount of parallel text, aligned at word, sentence or at least document level. We hypothesize however, that different natural languages share enough semantic structure that it should be possible, in principle, to learn compatible vector representations just by analyzing the monolingual distribution of words. In order to evaluate this hypothesis, we propose a scheme to map word vectors trained on a source language to vectors semantically compatible with word vectors trained on a target language using an adversarial autoencoder. We present preliminary qualitative results and discuss possible future developments of this technique, such as applications to cross-lingual sentence representations.