 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-rank passthrough neural networks
Paper and Code
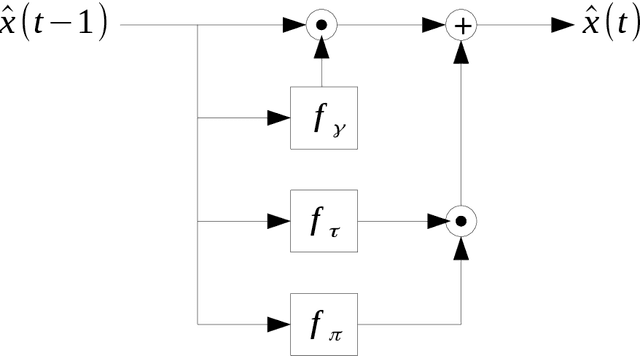
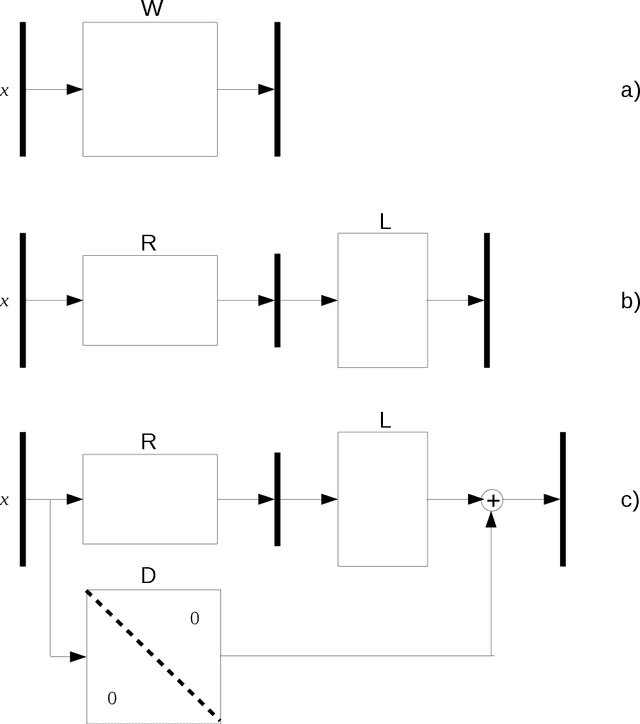
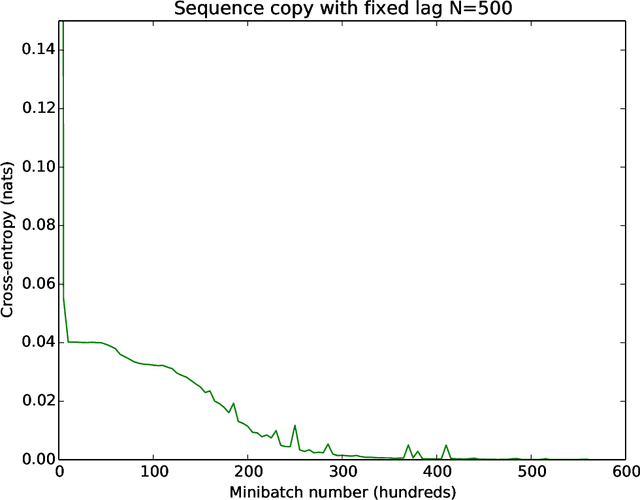
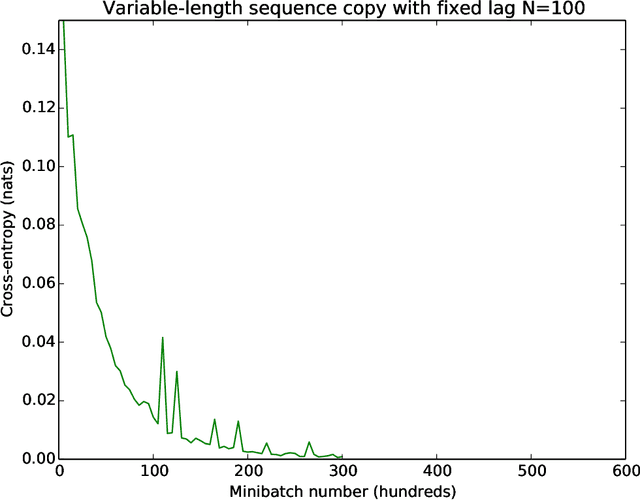
Various common deep learning architectures, such as LSTMs, GRUs, Resnets and Highway Networks, employ state passthrough connections that support training with high feed-forward depth or recurrence over many time steps. These "Passthrough Networks" architectures also enable the decoupling of the network state size from the number of parameters of the network, a possibility has been studied by \newcite{Sak2014} with their low-rank parametrization of the LSTM. In this work we extend this line of research, proposing effective, low-rank and low-rank plus diagonal matrix parametrizations for Passthrough Networks which exploit this decoupling property, reducing the data complexity and memory requirements of the network while preserving its memory capacity. This is particularly beneficial in low-resource settings as it supports expressive models with a compact parametrization less susceptible to overfitting. We present competitive experimental results on several tasks, including language modeling and a near state of the art result on sequential randomly-permuted MNIST classification, a hard task on natural data.