 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA parallel corpus of Python functions and documentation strings for automated code documentation and code generation
Paper and Code
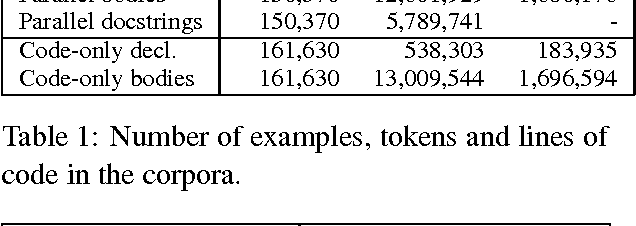

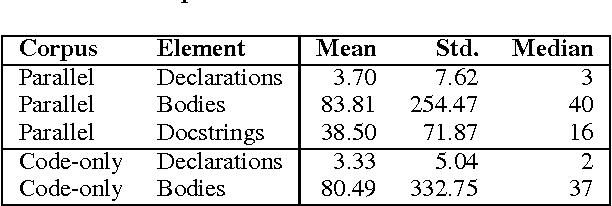
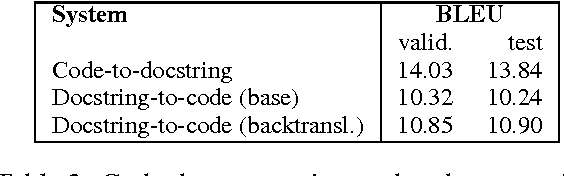
Automated documentation of programming source code and automated code generation from natural language are challenging tasks of both practical and scientific interest. Progress in these areas has been limited by the low availability of parallel corpora of code and natural language descriptions, which tend to be small and constrained to specific domains. In this work we introduce a large and diverse parallel corpus of a hundred thousands Python functions with their documentation strings ("docstrings") generated by scraping open source repositories on GitHub. We describe baseline results for the code documentation and code generation tasks obtained by neural machine translation. We also experiment with data augmentation techniques to further increase the amount of training data. We release our datasets and processing scripts in order to stimulate research in these areas.