 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA comparison of translation performance between DeepL and Supertext
Feb 04, 2025As strong machine translation (MT) systems are increasingly based on large language models (LLMs), reliable quality benchmarking requires methods that capture their ability to leverage extended context. This study compares two commercial MT systems -- DeepL and Supertext -- by assessing their performance on unsegmented texts. We evaluate translation quality across four language directions with professional translators assessing segments with full document-level context. While segment-level assessments indicate no strong preference between the systems in most cases, document-level analysis reveals a preference for Supertext in three out of four language directions, suggesting superior consistency across longer texts. We advocate for more context-sensitive evaluation methodologies to ensure that MT quality assessments reflect real-world usability. We release all evaluation data and scripts for further analysis and reproduction at https://github.com/supertext/evaluation_deepl_supertext.
Exploiting Biased Models to De-bias Text: A Gender-Fair Rewriting Model
May 18, 2023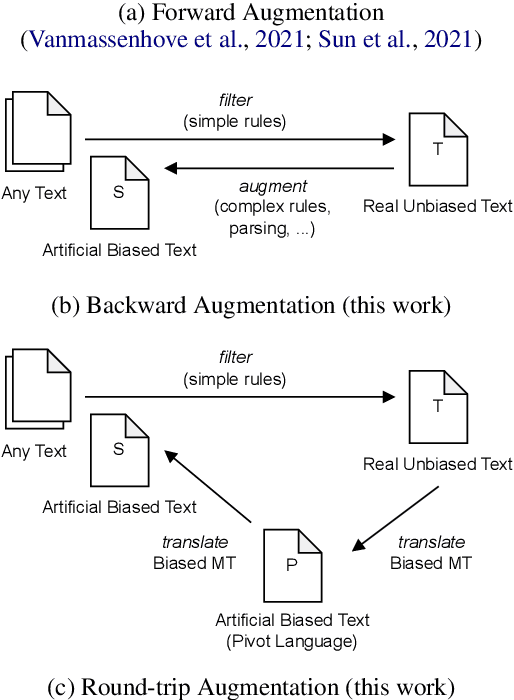



Natural language generation models reproduce and often amplify the biases present in their training data. Previous research explored using sequence-to-sequence rewriting models to transform biased model outputs (or original texts) into more gender-fair language by creating pseudo training data through linguistic rules. However, this approach is not practical for languages with more complex morphology than English. We hypothesise that creating training data in the reverse direction, i.e. starting from gender-fair text, is easier for morphologically complex languages and show that it matches the performance of state-of-the-art rewriting models for English. To eliminate the rule-based nature of data creation, we instead propose using machine translation models to create gender-biased text from real gender-fair text via round-trip translation. Our approach allows us to train a rewriting model for German without the need for elaborate handcrafted rules. The outputs of this model increased gender-fairness as shown in a human evaluation study.
The Impact of Text Presentation on Translator Performance
Nov 11, 2020

Widely used computer-aided translation (CAT) tools divide documents into segments such as sentences and arrange them in a side-by-side, spreadsheet-like view. We present the first controlled evaluation of these design choices on translator performance, measuring speed and accuracy in three experimental text processing tasks. We find significant evidence that sentence-by-sentence presentation enables faster text reproduction and within-sentence error identification compared to unsegmented text, and that a top-and-bottom arrangement of source and target sentences enables faster text reproduction compared to a side-by-side arrangement. For revision, on the other hand, our results suggest that presenting unsegmented text results in the highest accuracy and time efficiency. Our findings have direct implications for best practices in designing CAT tools.
What's the Difference Between Professional Human and Machine Translation? A Blind Multi-language Study on Domain-specific MT
Jun 08, 2020
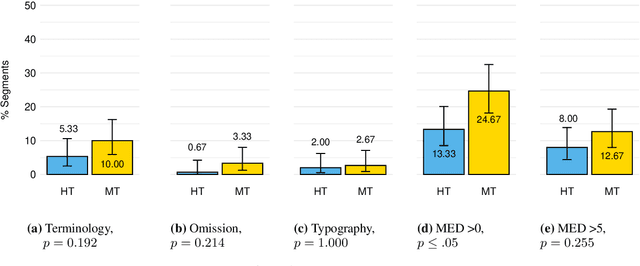

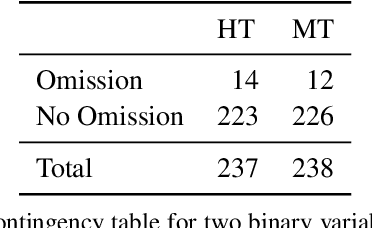
Machine translation (MT) has been shown to produce a number of errors that require human post-editing, but the extent to which professional human translation (HT) contains such errors has not yet been compared to MT. We compile pre-translated documents in which MT and HT are interleaved, and ask professional translators to flag errors and post-edit these documents in a blind evaluation. We find that the post-editing effort for MT segments is only higher in two out of three language pairs, and that the number of segments with wrong terminology, omissions, and typographical problems is similar in HT.
A Set of Recommendations for Assessing Human-Machine Parity in Language Translation
Apr 03, 2020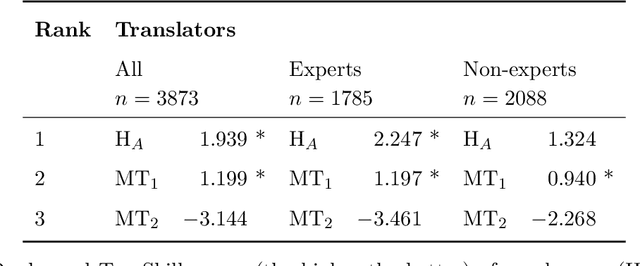

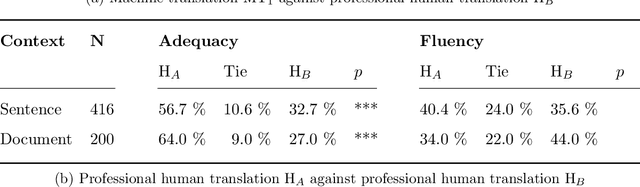
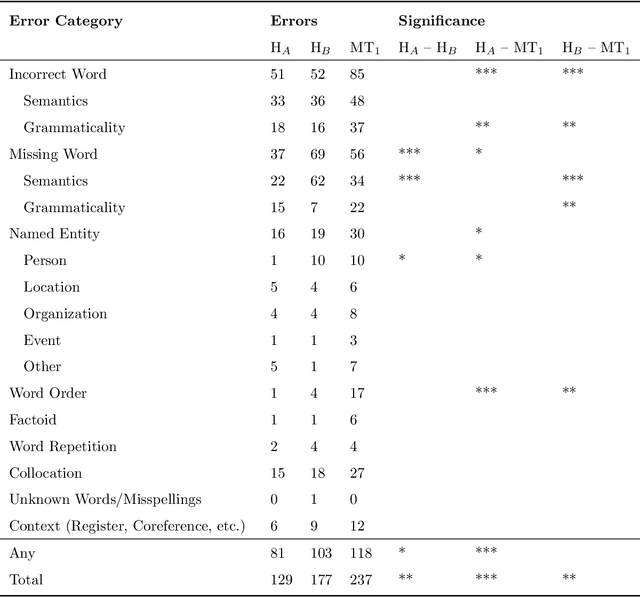
The quality of machine translation has increased remarkably over the past years, to the degree that it was found to be indistinguishable from professional human translation in a number of empirical investigations. We reassess Hassan et al.'s 2018 investigation into Chinese to English news translation, showing that the finding of human-machine parity was owed to weaknesses in the evaluation design - which is currently considered best practice in the field. We show that the professional human translations contained significantly fewer errors, and that perceived quality in human evaluation depends on the choice of raters, the availability of linguistic context, and the creation of reference translations. Our results call for revisiting current best practices to assess strong machine translation systems in general and human-machine parity in particular, for which we offer a set of recommendations based on our empirical findings.
Post-editing Productivity with Neural Machine Translation: An Empirical Assessment of Speed and Quality in the Banking and Finance Domain
Jun 04, 2019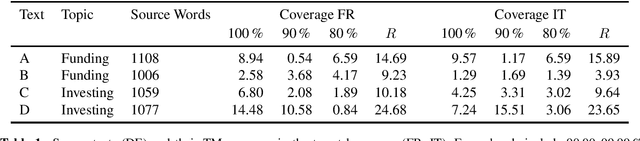
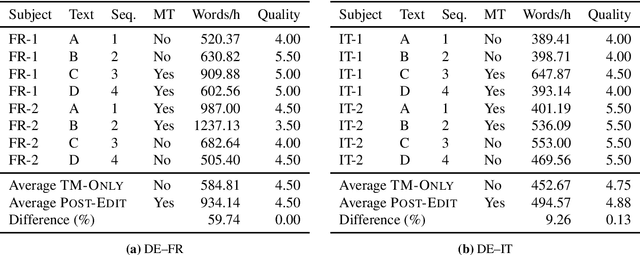
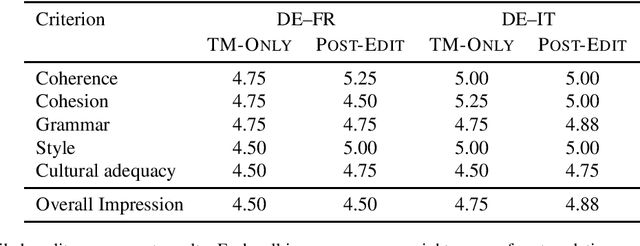
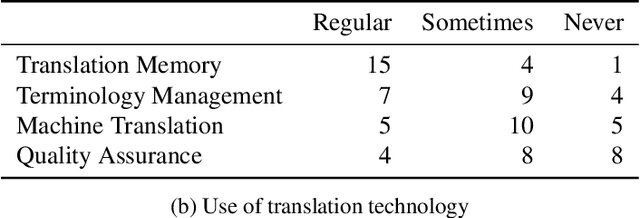
Neural machine translation (NMT) has set new quality standards in automatic translation, yet its effect on post-editing productivity is still pending thorough investigation. We empirically test how the inclusion of NMT, in addition to domain-specific translation memories and termbases, impacts speed and quality in professional translation of financial texts. We find that even with language pairs that have received little attention in research settings and small amounts of in-domain data for system adaptation, NMT post-editing allows for substantial time savings and leads to equal or slightly better quality.
Has Machine Translation Achieved Human Parity? A Case for Document-level Evaluation
Aug 21, 2018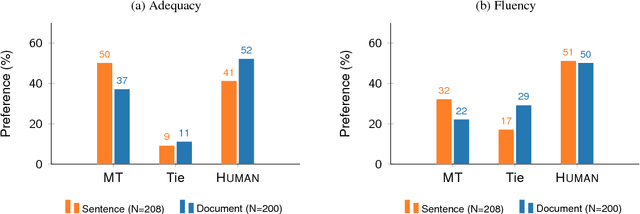
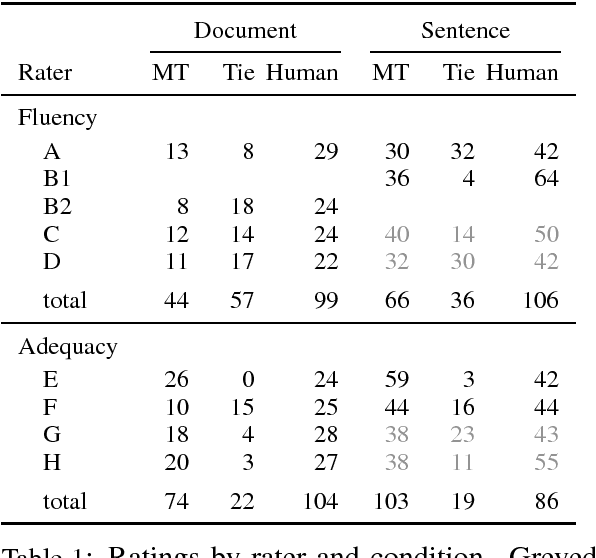
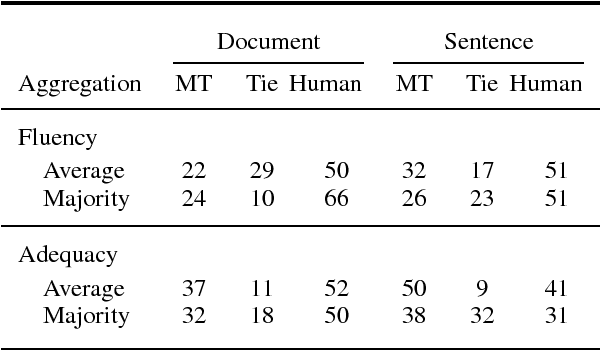
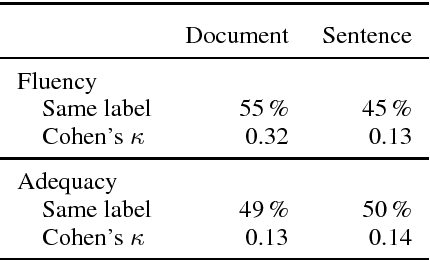
Recent research suggests that neural machine translation achieves parity with professional human translation on the WMT Chinese--English news translation task. We empirically test this claim with alternative evaluation protocols, contrasting the evaluation of single sentences and entire documents. In a pairwise ranking experiment, human raters assessing adequacy and fluency show a stronger preference for human over machine translation when evaluating documents as compared to isolated sentences. Our findings emphasise the need to shift towards document-level evaluation as machine translation improves to the degree that errors which are hard or impossible to spot at the sentence-level become decisive in discriminating quality of different translation outputs.
Nematus: a Toolkit for Neural Machine Translation
Mar 13, 2017
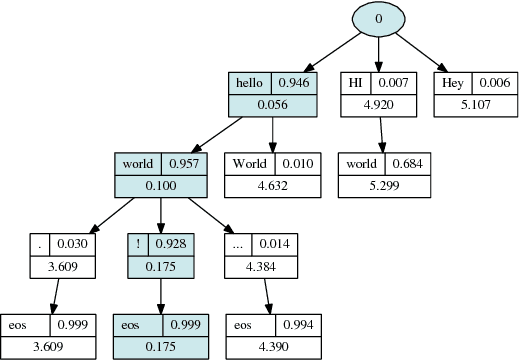
We present Nematus, a toolkit for Neural Machine Translation. The toolkit prioritizes high translation accuracy, usability, and extensibility. Nematus has been used to build top-performing submissions to shared translation tasks at WMT and IWSLT, and has been used to train systems for production environments.
Automatic TM Cleaning through MT and POS Tagging: Autodesk's Submission to the NLP4TM 2016 Shared Task
May 19, 2016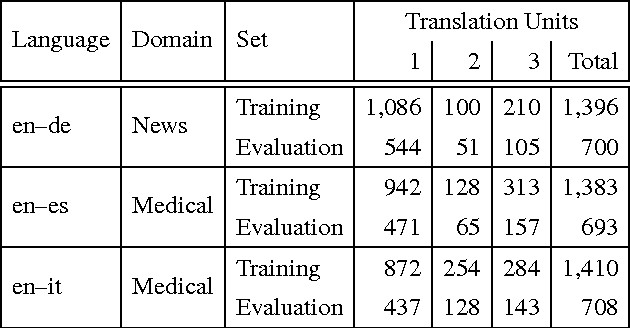
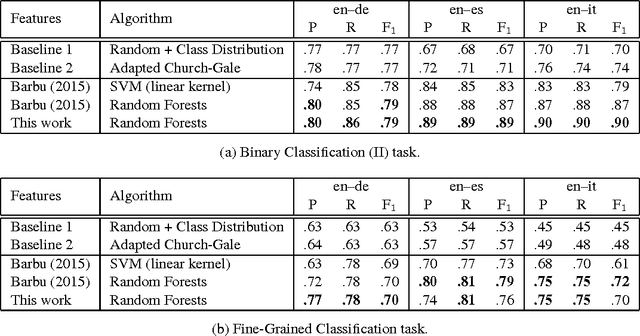
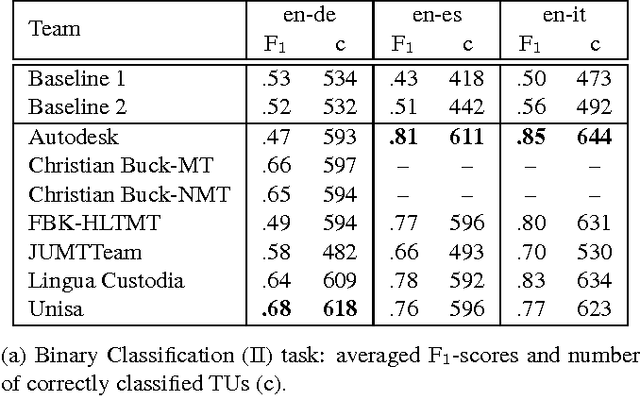
We describe a machine learning based method to identify incorrect entries in translation memories. It extends previous work by Barbu (2015) through incorporating recall-based machine translation and part-of-speech-tagging features. Our system ranked first in the Binary Classification (II) task for two out of three language pairs: English-Italian and English-Spanish.