 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Set of Recommendations for Assessing Human-Machine Parity in Language Translation
Paper and Code
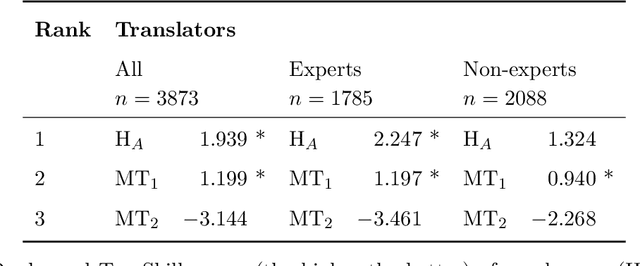

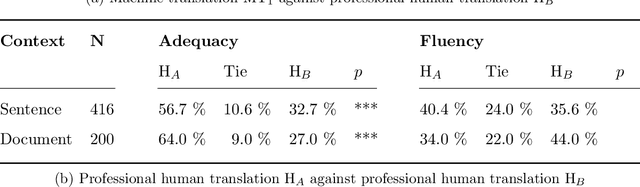
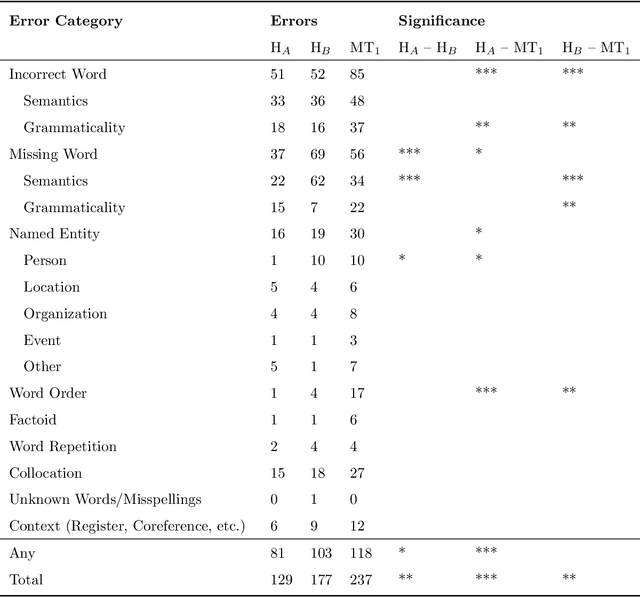
The quality of machine translation has increased remarkably over the past years, to the degree that it was found to be indistinguishable from professional human translation in a number of empirical investigations. We reassess Hassan et al.'s 2018 investigation into Chinese to English news translation, showing that the finding of human-machine parity was owed to weaknesses in the evaluation design - which is currently considered best practice in the field. We show that the professional human translations contained significantly fewer errors, and that perceived quality in human evaluation depends on the choice of raters, the availability of linguistic context, and the creation of reference translations. Our results call for revisiting current best practices to assess strong machine translation systems in general and human-machine parity in particular, for which we offer a set of recommendations based on our empirical findings.