 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimising ChatGPT for creativity in literary translation: A case study from English into Dutch, Chinese, Catalan and Spanish
Apr 25, 2025This study examines the variability of Chat-GPT machine translation (MT) outputs across six different configurations in four languages,with a focus on creativity in a literary text. We evaluate GPT translations in different text granularity levels, temperature settings and prompting strategies with a Creativity Score formula. We found that prompting ChatGPT with a minimal instruction yields the best creative translations, with "Translate the following text into [TG] creatively" at the temperature of 1.0 outperforming other configurations and DeepL in Spanish, Dutch, and Chinese. Nonetheless, ChatGPT consistently underperforms compared to human translation (HT).
Multi-perspective Alignment for Increasing Naturalness in Neural Machine Translation
Dec 11, 2024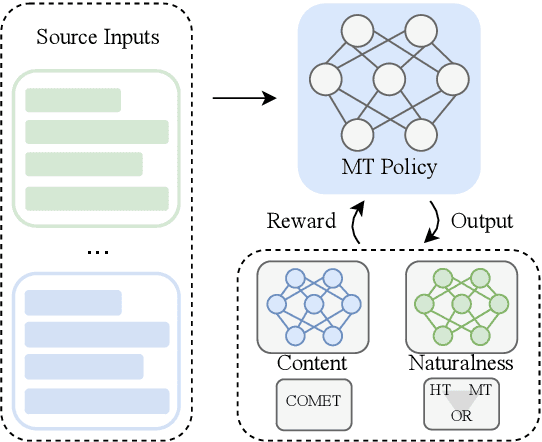
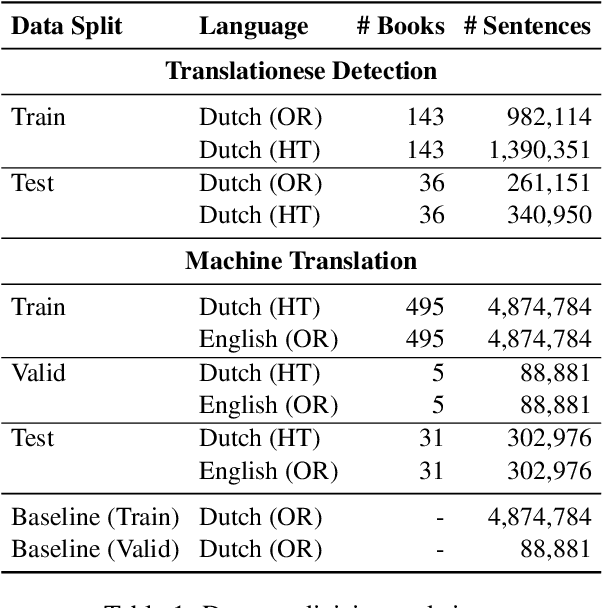
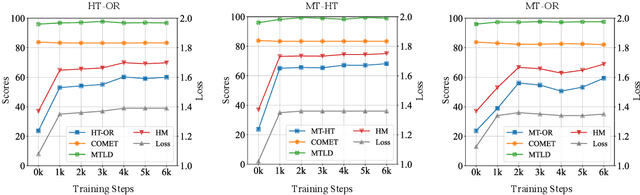
Neural machine translation (NMT) systems amplify lexical biases present in their training data, leading to artificially impoverished language in output translations. These language-level characteristics render automatic translations different from text originally written in a language and human translations, which hinders their usefulness in for example creating evaluation datasets. Attempts to increase naturalness in NMT can fall short in terms of content preservation, where increased lexical diversity comes at the cost of translation accuracy. Inspired by the reinforcement learning from human feedback framework, we introduce a novel method that rewards both naturalness and content preservation. We experiment with multiple perspectives to produce more natural translations, aiming at reducing machine and human translationese. We evaluate our method on English-to-Dutch literary translation, and find that our best model produces translations that are lexically richer and exhibit more properties of human-written language, without loss in translation accuracy.
Towards Tailored Recovery of Lexical Diversity in Literary Machine Translation
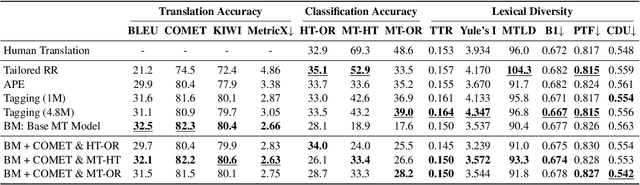
Aug 30, 2024Machine translations are found to be lexically poorer than human translations. The loss of lexical diversity through MT poses an issue in the automatic translation of literature, where it matters not only what is written, but also how it is written. Current methods for increasing lexical diversity in MT are rigid. Yet, as we demonstrate, the degree of lexical diversity can vary considerably across different novels. Thus, rather than aiming for the rigid increase of lexical diversity, we reframe the task as recovering what is lost in the machine translation process. We propose a novel approach that consists of reranking translation candidates with a classifier that distinguishes between original and translated text. We evaluate our approach on 31 English-to-Dutch book translations, and find that, for certain books, our approach retrieves lexical diversity scores that are close to human translation.
Do Language Models Care About Text Quality? Evaluating Web-Crawled Corpora Across 11 Languages
Mar 13, 2024Large, curated, web-crawled corpora play a vital role in training language models (LMs). They form the lion's share of the training data in virtually all recent LMs, such as the well-known GPT, LLaMA and XLM-RoBERTa models. However, despite this importance, relatively little attention has been given to the quality of these corpora. In this paper, we compare four of the currently most relevant large, web-crawled corpora (CC100, MaCoCu, mC4 and OSCAR) across eleven lower-resourced European languages. Our approach is two-fold: first, we perform an intrinsic evaluation by performing a human evaluation of the quality of samples taken from different corpora; then, we assess the practical impact of the qualitative differences by training specific LMs on each of the corpora and evaluating their performance on downstream tasks. We find that there are clear differences in quality of the corpora, with MaCoCu and OSCAR obtaining the best results. However, during the extrinsic evaluation, we actually find that the CC100 corpus achieves the highest scores. We conclude that, in our experiments, the quality of the web-crawled corpora does not seem to play a significant role when training LMs.
To be or not to be: a translation reception study of a literary text translated into Dutch and Catalan using machine translation
Jul 05, 2023This article presents the results of a study involving the reception of a fictional story by Kurt Vonnegut translated from English into Catalan and Dutch in three conditions: machine-translated (MT), post-edited (PE) and translated from scratch (HT). 223 participants were recruited who rated the reading conditions using three scales: Narrative Engagement, Enjoyment and Translation Reception. The results show that HT presented a higher engagement, enjoyment and translation reception in Catalan if compared to PE and MT. However, the Dutch readers show higher scores in PE than in both HT and MT, and the highest engagement and enjoyments scores are reported when reading the original English version. We hypothesize that when reading a fictional story in translation, not only the condition and the quality of the translations is key to understand its reception, but also the participants reading patterns, reading language, and, perhaps language status in their own societies.
Multilingual Multi-Figurative Language Detection
May 31, 2023Figures of speech help people express abstract concepts and evoke stronger emotions than literal expressions, thereby making texts more creative and engaging. Due to its pervasive and fundamental character, figurative language understanding has been addressed in Natural Language Processing, but it's highly understudied in a multilingual setting and when considering more than one figure of speech at the same time. To bridge this gap, we introduce multilingual multi-figurative language modelling, and provide a benchmark for sentence-level figurative language detection, covering three common figures of speech and seven languages. Specifically, we develop a framework for figurative language detection based on template-based prompt learning. In so doing, we unify multiple detection tasks that are interrelated across multiple figures of speech and languages, without requiring task- or language-specific modules. Experimental results show that our framework outperforms several strong baselines and may serve as a blueprint for the joint modelling of other interrelated tasks.
Automatic Discrimination of Human and Neural Machine Translation in Multilingual Scenarios
May 31, 2023We tackle the task of automatically discriminating between human and machine translations. As opposed to most previous work, we perform experiments in a multilingual setting, considering multiple languages and multilingual pretrained language models. We show that a classifier trained on parallel data with a single source language (in our case German-English) can still perform well on English translations that come from different source languages, even when the machine translations were produced by other systems than the one it was trained on. Additionally, we demonstrate that incorporating the source text in the input of a multilingual classifier improves (i) its accuracy and (ii) its robustness on cross-system evaluation, compared to a monolingual classifier. Furthermore, we find that using training data from multiple source languages (German, Russian, and Chinese) tends to improve the accuracy of both monolingual and multilingual classifiers. Finally, we show that bilingual classifiers and classifiers trained on multiple source languages benefit from being trained on longer text sequences, rather than on sentences.
Missing Information, Unresponsive Authors, Experimental Flaws: The Impossibility of Assessing the Reproducibility of Previous Human Evaluations in NLP
May 02, 2023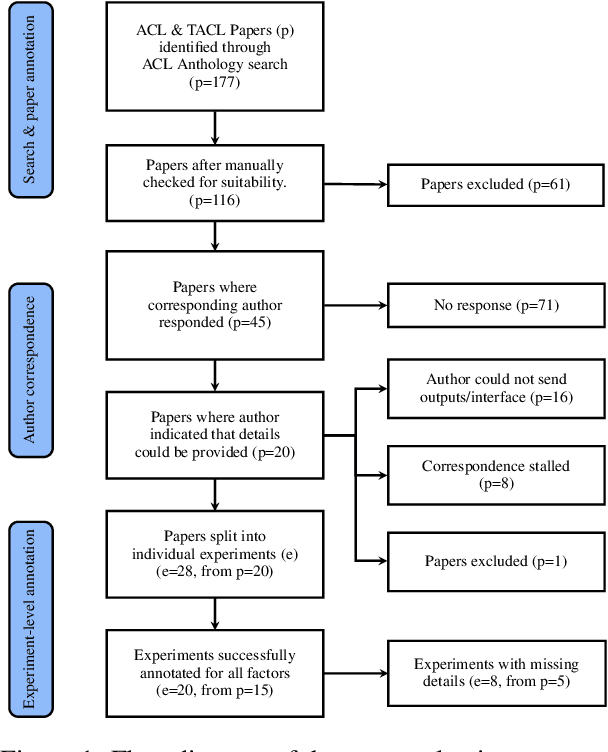
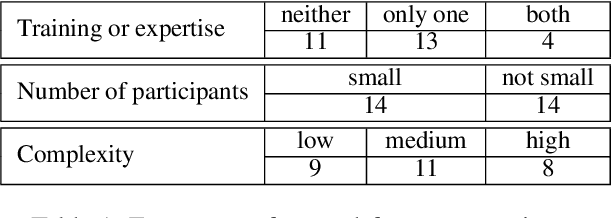


We report our efforts in identifying a set of previous human evaluations in NLP that would be suitable for a coordinated study examining what makes human evaluations in NLP more/less reproducible. We present our results and findings, which include that just 13\% of papers had (i) sufficiently low barriers to reproduction, and (ii) enough obtainable information, to be considered for reproduction, and that all but one of the experiments we selected for reproduction was discovered to have flaws that made the meaningfulness of conducting a reproduction questionable. As a result, we had to change our coordinated study design from a reproduce approach to a standardise-then-reproduce-twice approach. Our overall (negative) finding that the great majority of human evaluations in NLP is not repeatable and/or not reproducible and/or too flawed to justify reproduction, paints a dire picture, but presents an opportunity for a rethink about how to design and report human evaluations in NLP.
Multidimensional Evaluation for Text Style Transfer Using ChatGPT
Apr 26, 2023We investigate the potential of ChatGPT as a multidimensional evaluator for the task of \emph{Text Style Transfer}, alongside, and in comparison to, existing automatic metrics as well as human judgements. We focus on a zero-shot setting, i.e. prompting ChatGPT with specific task instructions, and test its performance on three commonly-used dimensions of text style transfer evaluation: style strength, content preservation, and fluency. We perform a comprehensive correlation analysis for two transfer directions (and overall) at different levels. Compared to existing automatic metrics, ChatGPT achieves competitive correlations with human judgments. These preliminary results are expected to provide a first glimpse into the role of large language models in the multidimensional evaluation of stylized text generation.
Are Character-level Translations Worth the Wait? An Extensive Comparison of Character- and Subword-level Models for Machine Translation
Feb 28, 2023Pretrained large character-level language models have been recently revitalized and shown to be competitive with subword models across a range of NLP tasks. However, there has not been any research showing their effectiveness in neural machine translation (NMT). This work performs an extensive comparison across multiple languages and experimental conditions of state-of-the-art character- and subword-level pre-trained models (ByT5 and mT5, respectively) on NMT, and shows that the former not only are effective in translation, but frequently outperform subword models, particularly in cases where training data is limited. The only drawback of character models appears to be their inefficiency (at least 4 times slower to train and for inference). Further analysis indicates that character models are capable of implicitly translating on the word or subword level, thereby nullifying a major potential weakness of operating on the character level.